기존의 Word를 Vector로 표현하는 방법은 Topic Modeling에서와 같이 Frequency(빈도) 기반의 방법론이 대세를 이루고 있습니다. 이러한 빈도 기반의 방법론에서 벗어나 Word Embedding을 distributed representation(분산 표현)으로 나타내고자 한 방법이 바로 Word2Vec과 GloVe입니다.
해당 방법론들이 등장한 이후로 빈도 기반의 word embedding 방법론은 모두 사라지고 현재까지도 distributed representation 즉, word의 의미를 Vector의 각 차원에 고루 값을 갖도록 하는 방법이 유행하고 있습니다.
각 차원의 의미를 해석하기는 어려워졌지만, 다양한 Task에서 강력한 성능을 보이면서 현재까지 각광받고 있는 접근법입니다.
Word2Vec

Word Embedding은 의미가 비슷한 단어라면, 좌표공간에서도 비슷한 위치에 있기 바라는 것이다.
예를 들어, cat과 kitty는 '고양이' 라는 비슷한 의미를 가진다. 그렇다면, 이 두 단어들은 벡터공간상에서 비슷한 벡터들로 나타내어지고, 두 벡터의 위치가 가깝게 된다.
반대로, '햄버거' 라는 의미를 가진 단어는 '고양이' 와는 먼 거리에 위치한 벡터가 될 것이다.
기본적으로 분류 task를 한다고 할 때, 위와 같은 과정이 잘 되어 있다면, 'I love this movie' , 'I hate this movie' 와 같이 긍정/부정으로 쉽게 분류할 수 있게 된다.

하지만, 우리는 두 개의 단어의 의미를 알고 있기 때문에 비슷하거나 다르다고 판단할 수 있지만, 알고리즘은 두 개의 단어가 주어졌을 때, 얼마나 비슷한지 비교할 수 없다. 따라서, 통계적인 co-occurrence을 판단의 기준으로 삼는다.
예를 들면, 'cat'이라는 단어가 있을 때, 학습데이터를 모은 후, 같은 문장에서 주어진 단어들을 비교해보자.
'purrs'라는 단어는 '털이 빠진다'는 뜻이다. 'cat'과 'purrs'라는 단어가 한 문장내에서 같이 등장했다는 것은, 무슨 의미인지는 모르더라도 두 개의 단어가 비슷한 의미를 가진다라고 가정하는 것이다.
'cat'과 'purrs' 라는 단어가 100만개의 문장 중 300개의 문장에서 동시에 들어있었고, 'dog'와 'purrs'라는 단어는 100만개의 문장 중 10개의 문장에서만 동시에 들어있었다면, 'cat'과 'purrs'가 훨씬 더 의미론적으로 유사하다고 생각하는 것이다.
따라서, 같이 등장하는 빈도수가 높으면 높을수록, 두 단어들을 유사한 의미로 판단하고 distance를 더 짧게 만들어준다.

직관적으로 말하자면, 이것을 하는 deep learning의 학습 과정이나 알고리즘의 방법은 다음과 같다.
먼저, 이 word들을 몇 차원의 벡터로 나타낼 것인가 는 사전에 정하고 들어가도록 한다. (ex. 3차원)
word embedding이라는 알고리즘은, 각각의 word들에 대한 어떤 의미를 잘 반영한 최적의 정해진 dimension만큼의 갯수를 가진 vector들을 각 단어별로 부여해준다.
그리고 그 알고리즘이 동작하는 기본과정은, 100만개의 문장을 모았다고 가정했을 때, 이 문장들에서 나타나는 unique한 단어들에 vector를 할당해 주는 것이다. 10개의 unique한 단어들로 조합된 100만개의 문장이 이루어져 있다고 가정하면, 10개의 unique한 단어별로 최적의 vector를 할당해준다. random initialization하듯이 random으로 부여해준다.
100만개의 문장들을 하나하나씩 살펴보고, 같은 문장에서 등장한 두 개의 단어는 같은 정도로 조금씩 당겨준다. 이러한 빈도수가 높다면, 두 단어는 가까운 곳에 위치할 것이다.
Word2Vec Algorithm

Word Embedding이라는 알고리즘에는 기본적으로 여러가지 알고리즘이 존재한다.
알고리즘의 기본적인 아이디어나 학습과정은 앞에서와 같은 직관적인 과정을 전부 따르고 있다.
구체적인 알고리즘으로써 Word2Vec과 GLoVe 기법이 있는데, 이 둘은 약간의 차이가 있지만, 둘 다 많이 쓰인다.
먼저, Word2Vec 기법은 같은 문장에서 나타난 co-occurrence를 기반으로, 그 횟수에 비례해서 더욱 더 거리를 가깝게 만들어주는 것에서부터 시작한다. co-occurrence를 따질때, 문장이 길다면, 문장 앞의 단어와 문장 뒤의 단어는 연관성이 떨어질 수도 있을 것이다.
그래서 window size라는 것을 생각한다. window size를 ± 1 로 잡는다면, sliding window를 하면서 다음과 같이 생각해볼 수 있을 것이다.

이렇게 window를 돌아다니면서 가운데 단어와 window 내부에 존재하는 주변의 단어 하나하나씩을 가지고 pair를 만들게 된다.
문장 내부에서 slide window를 옮겨가게 되면서 구체적으로 Word2Vec 모델을 학습할 때, word-pair를 얻어내게 된다.
이것이 우리의 학습 데이터가 된다.
word-pair에서 앞쪽은 입력 word, 뒤쪽은 출력 word가 된다.
이러한 입출력 pair를 구성했으면, study를 입력으로 주었을 때 I를 추론한다던지, math를 추론하는 형태로 deep learning 모델을 학습하게 될 것이다.
이 학습과정은 다음과 같다.

먼저, hidden layer 하나짜리에 neural net을 만든다. 여기서 주어지는 입력은 우리가 갖고 있는 단어수가 된다. 예를들어, 100만개의 문장에서 unique한 단어가 10개 있다고 가정한다면, 10개의 입력노드들로 구성되는 input layer가 만들어진다.
output layer도 마찬가지이다. output은 10개 단어 중에 하나의 단어를 맞추는 task가 될 것이다. input layer와 output layer는 각각 10개의 노드로 구성될 것이다. hidden layer는 이 단어 하나하나들을 몇 개의 dimension으로 이루어지는 vector space embedding할 것인지에서의 dimension 수가 hidden layer에서의 node 수가 될 것이다.
여기서, 입력과 출력의 node 수를 unique한 word의 수와 같게 한 이유는 각각의 dimension이 unique한 word에 각각 할당되기 때문이다.

간단하게 나타내면, 만약, 우리가 가진 문장은 하나이고, 이것이 ' I study math' 라는 문장일 때, input layer와 output layer는 3개의 node를 가진다. 그리고 hidden layer를 2차원이라고 가정해보자. 이러한 neural net에서 (study, I) 라는 데이터를 가지고 학습을 할 것이다. study를 나타내는 vector는 [0 1 0]이 될 것이다. 이런 것을 one-hot vector라고 한다. (one-hot vector는 categorical variable을 vector로 나타내는 단순한 방식이다.) 또한, 2 layer를 가진다.(입력은 제외하고 말한다)
출력은 I가 나와야하므로 [1 0 0 ]이라는 vector가 output으로 나와야 할 것이다. 이에 가까워지기 위해서는 input layer -> hidden layer와 hidden layer -> output layer의 parameter들이 학습이 되어야 할 것이다. (학습을 통해 최적화하기)
입력이 one-hot vector이고, 1번째 layer에 쓰이는 linear transform matrix를 W라고 하면(W' 도 있다.), linear transformation이 일어나는 것을 행렬곱으로 표현해보자면, W1은 위와 같다. 위와 같은 방식으로 행렬곱을 표현하면 두 개의 layer를 거쳐서 2차원으로 줄었다가, 다시 3차원으로 늘어나는 과정을 거치게 된다.
이렇게 나온 3차원 vector에 softmax 함수를 걸어주게 된다. 여기서 softmax가 가지는 역할은 기본적으로 어떤 주어진 벡터든지, 그 벡터를 확률분포(합이 1이며, 0보다 크거나 같은) 로 변환해준다.
그렇게 만들어진 vector가 [0.7 0.2 0.1]이라고 하면, 이것은 예측한 확률분포라고 생각할 수 있게 된다. 이렇게 예측값으로 나온 확률분포가 ground truth( [ 1 0 0 ] )와 가장 근사적인 값이 되도록 만들어주는 loss를 걸어서 학습시키게 된다. 여기서 loss는 softmax loss이고, ground truth에 가까워지게끔 한다.
W1 matrix에서 input vector와 같이 해당 word에 해당하는 column vector를 뽑아오는 것이 첫 번째 layer가 하는 일이다. (여기서 2 dimension vector(column)를 뽑는다)
W2는 row vector가 vocab에 정의된 각각의 word에 대응하는 2차원 벡터이다. W1에서 뽑힌 입력 word에 대한 2차원 벡터를 W2의 각각의 word가 가지는 2차원 벡터와 다 내적을 해서 만들어지는 값이 softmax의 입력으로 들어가는 값이 된다.
따라서, ground truth에 output word에 해당하는 2 dimension vector(row)는 W2(두 번째 layer)에서 뽑게 된다.
이 둘 간의 내적은 최대한 무한대에 가까워지게 만들고, word에 해당하지 않는 벡터들은 최대한 멀어지게 학습하는 것이다.

https://ronxin.github.io/wevi/ 이 사이트에서 예제를 살펴볼 수 있다.

2 layer (보통 입력은 빼고 말한다) neural net이다.
입력 layer의 node의 개수(unique한 word)는 8이고, 5차원의 hidden layer를 가진다. 8개의 unique한 단어들로 이루어지는 각각의 word들을 5차원 벡터로 Word2Vec 모델을 학습시키는 사례이다.
train data는 미리 짝지어서 구분해놓았다.

이것은 random initialization한 결과이다. 빨간색일수록 큰 값이고, 파란색일수록 작은 값이다. 이것이 계속 학습될수록 색깔이 진해지게 된다. word embedding에는 input과 output의 평균을 낸 값을 이용하기도하고, W1이 나타내는 word embedding vector만을 사용하기도 한다.
이런식으로 배운 것을 보기 쉽게 이해해보자.
만약, ( apple, eat ), ( orange, eat ) 이 있다고 한다면, apple 이라는 input word vector는 eat이라는 output word vector와 비슷해야하고, orange도 eat과 비슷해야한다. 이 둘은 공통 output word vector를 가진다. 따라서, apple 과 orange는 같은 output vector를 공유함으로써, 비슷한 위치에 존재할 것이다. 반대의 경우도 마찬가지이다.
Word2Vec Property

Word2Vec은 대규모 데이터를 가지고 학습을 했더니, 여러가지 흥미로운 task들을 수행할 수 있게된다.
예를 들면, 위쪽의 식을 이항하게 되면, vec[queen] - vec[king] + vec[man] = vec[woman] 이 됩니다. 이것은 여왕과 남왕의 차이가 성별의 차이를 나타내는 개념으로써 생각할 수 있으며, 이것들을 vector로 바꾸어 계산할 수 있게 됩니다.
vector 공간 상에서 성별의 차이를 일관된 vector의 형태로 학습하게 됩니다.


성별의 차이뿐만 아니라, 회사와 ceo의 사이(차이)를 학습된 vector를 가지고도 각 vector들은 비슷한 크기와 방향을 가리킵니다. 이런식으로 학습된 것은 word embedding의 특성이 됩니다.



이 예시를 보면, 한국 - 서울 + 도쿄 의 결과로는 일본이 나올 것입니다.

이러한 word embedding vector가 여러 자연어처리 task를 수행하는데 starting point로써, word들을 벡터화해서 정량적인 숫자들로 표시해주는 필수적인 역할을 수행하게 된다.


word embedding을 통해서 할 수 있는 흥미로운 task 중 하나는, Intrusion detection 이라는 task입니다.
각각의 word들은 특정한 vector를 가질 것입니다. 이 vector들 간의 거리를 전부 재보는 것입니다. 모든 word-pair들 간의 거리를 계산해서, 어떤 word가 평균적으로 유사도가 떨어지는지 확인을 합니다. 이렇게 유사도를 효과적으로 학습했다는 사실을 알 수 있습니다.



image captioning이라는 task는 이미지를 text로 변환하는 것입니다.
GloVe

또 다른 word embedding 기법으로는 GloVe가 있다.
Word2Vec은 동일한 train instance를 여러번에 걸쳐서 학습하기 때문에 학습에 있어서 비효율적인면이 있다.
하지만, GloVe는 모든 word-pair에 대해서 co-occurrence의 횟수(같이 등장한 빈도수)를 계산한다. 이는 다음과 같다.

우리는 다음과 같이 횟수에 대한 ground truth를 얻을 수 있다.
대각선의 값은 항상 0이 되진 않을 것이다. 만약, 'Thank you very very much ' 라는 문장이 있다면, very가 연속적으로 등장하기 때문에 0이 아닐 수도 있다.
결국 이 횟수들에 비례해서 vector들의 유사도가 커지면 될 것이다.
앞에서의 방식을 다시 보자. W1과 W2의 내적값으로 생성된 matrix가 우리가 미리 구해놓은 횟수들이 담긴 matrix와 유사해지도록 W1와 W2를 학습시켜야한다.
이것이 또 다른 관점에서 살펴본 word embedding 학습을 하는 과정이다. ( GloVe의 아이디어가 된다. ) 이 방법은 학습을 좀 더 빠르게 할 수 있다.
위 그림에서 왼쪽 아래에 보이는 matrix는 모든 input word와 output word에 대한 word embedding vector의 내적 값이다.
오른쪽 위의 ground truth로 사용하는 matrix는 각각의 값에다가 log값을 취한다. (log는 값이 커질수록 증가폭이 작아지는 성질을 가진다)

matrix 안의 숫자가 높으면 Word2Vec에서는 더 많은 횟수로 학습이 된다는 의미이다. 이것처럼, 빈도수에 비례해서 가중치를 부여하여 학습하는 것이다. 이 가중치는 위 그림에서처럼 f 라는 함수이다. 이러한 함수를 사용하면, 어떤 빈도수를 정하면, 그 빈도수에 비례하게 learning rate를 크게 써주지만, 그 빈도수 이상이되면, 더이상 learning rate가 늘어나지 않도록 한다.
위 식에서 i 는 모든 input word, j는 모든 output word이다. 실제 내적값과 ground truth similarity의 차의 제곱을 minimize 해주며, 가중치에 비례하는 gradient값이 나오기 때문에 learning rate를 가변적으로 달리 쓰는것과 동일한 효과를 내게 된다.
이것이 바로 word embedding하는 GloVe라는 방식이다.
학습을 다 마치고나면, 입력버전의 word embedding vector와 출력버전의 word embedding vector, 이렇게 두 세트가 나오지만, 편의상 입력버전의 word embedding vector를 가지고 사용을 하여 main task를 학습을 한다. 또한, 이 두 세트를 평균내어 사용하기도 한다.
https://nlp.stanford.edu/projects/glove/ 이 링크는 GloVe의 웹사이트이다. 이곳에는 GloVe라는 word embedding vector를 학습할 수 있는 학습 코드도 오픈소스로 제공해줄 뿐만 아니라, 대규모 data에 대해서 이미 GloVe를 학습을 끝내고 난 후의 최종 output을 제공하기도 한다.
Doc2Vec (Paragraph2Vec)


Word2Vec은 기본적으로 word들을 vector화 하는 알고리즘이지만, Doc2Vec 혹은 Paragraph2Vec 이라는 형태의 알고리즘은 word 뿐만 아니라, 주어지는 다른 종류의 categorical variable도 word들과 함께 embedding을 할 수 있게 된다.
예를 들면, ' I study math ' 라는 글이 있다고 가정해보자. 이 글을 쓴 작성자의 정보 ( 여성인지, 10대인지, 글이 쓰여진 장소가 학교인지 등) , 이를 메타 정보라고 하며, 또 다른 세트의 categorical variable이라고 볼 수 있다. 이러한 categorical variable들도 word들을 embedding vector로써 변환하는 이 과정을 학습하는 가운데에, 같은 embedding space에 vector들로써 같이 학습을 시켜서 도출해낼 수 있게 된다.

' I study math ' 라는 글이 있다고 해보자. 이번에는 study와 math를 뽑았다.
그런데, 이 글을 쓴 사람이 female이고 10대이다라고하면, male과 female의 값로 이루어지는 categorical variable을 입력에 추가한다. 마찬가지로, 10대, 20대, 30대, 40대라는 categorical variable을 입력에 추가해준다.
이렇게 우리는 입력에 두 가지 정보를 끼워넣어주었다.

다시 Word2Vec으로 돌아가서 학습을 구상해보자.
입력 벡터( x)는 성별, 나이를 나타내는 categorical one-hot vector가 추가된 vector이다.
이 입력 벡터(x)에 embedding vector(W1)를 곱해주면, embedding vector의 column(W1)의 갯수도 input 갯수만큼 늘어나게 된다.
W1은 x와 내적으로 곱해지고, x에서 1이 존재하는 부분의 값들이 더해지게 된다. 결국, 1자리에 위치하는 embedding vector들이 다 합산이 된 2차원 벡터로 나오게 된다.
이 2차원 vector는 다시 W2(output word)와 내적이 된다.
결론적으로, study라는 입력 벡터가 math라는 단어와 가까워져야될뿐만아니라, female, 10대라는 입력베터와도 math가 가까워져야한다. 즉, study, female, 10대가 합해진 입력 벡터와 가까워져야한다.
즉, 추가적인 attribute도 같은 2차원 공간상에서 다른 word들과 함께 embedding을 시킬 수 있다. W1은 주어진 word들 뿐만아니라, 추가적인 category에 대한 2D embedding vector들도 같이 학습을 할 수 있게 된다.
이러한 기법들을 Doc2Vec 또는 Paragraph2Vec 이라고 부른다.

study와 math가 있는 pair에 추가적으로 등장한 female이나 10대라는 입력에 추가할 수 있지만, 출력에도 추가할 수 있다.
그렇게 된다면, 입력은 study 한 단어로만 있고, 출력에 math, female, 10대가 있는 one-hot vector로 나올 수 있게 된다.
study에 해당하는 vector가 하나 뽑히고, 이것을 2차원 vector라고 한다면, W2는 총 단어수로 vector dimension을 이루게 된다.

앞에서와 같이 계산하여 나온 내적 값을 softmax를 category별로 걸어서 해당 단어인 math, female, 10대 만 나오도록 한다. (ex. I, study, math 에서 하나, male, female에서 하나, 10대, 20대, 30대, 40대 중에서 하나)
output으로 추가적인 정보를 주입한다는 것은, 각각의 요소를 동시에 예측을 할 것이라는 의미이다.

기존에 의해 만들어진 여러 정보를 예측하는 것은 multi-task learning이라고 볼 수 있다. 각각 word, gender, age를 예측하는 loss function에다가 각각의 가중치를 hyperparameter로써 정의해서 이 값들을 validation data를 통해서 최적화를 수행하게 된다.

또 다른 Word2Vec의 Application으로써는,
지금까지의 Word2Vec은 다른 종류의 categorical variable을 추가로 주입을 할 수 있었듯이, 꼭 입력과 출력이 word이어야만 하지는 않는다. 어떤 종류의 categorical variable이라도 추가가 가능하다.
예를들어, 추천 시스템의 경우에는 유저가 존재할 때, netflix의 가입자가 3명 있고, 쇼핑몰에서 판매되는 상품이 4개가 있다고 하자. 여기서 Jane이 macbook을 샀다고 가정하면, Jane에 해당하는 one-hot vector가 입력으로 들어오게 되고, Mackbook에 해당하는 one-hot vector가 출력으로 주어진다.
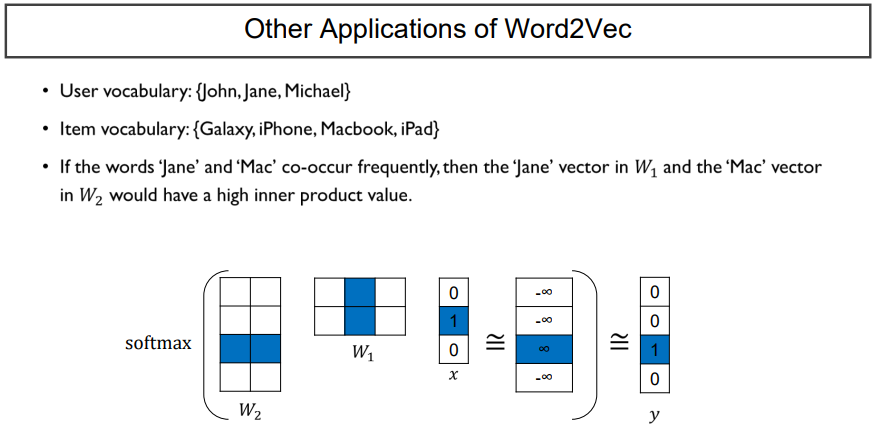
입력벡터(x) 에 해당하는 one-hot vector의 1자리의 column을 뽑게 된다면, W1에서는 Jane이 될 것이다.
출력벡터로는 macbook에 해당하는 W2와 아까 구한 Jane에 해당하는 W1의 내적값을 키우는 방식으로 학습하게 된다.
Word2Vec에서는 W1과 W2 모두 word들에 대응하는 2 Dimension vector였다면, 이번에는, W1은 사용자에 대한 embedding vector, W2는 사용자가 산 물건에 대한 embedding vector를 얻게 된다. 사람과 물건이 같은 embedding space 혹은 우리가 정한 hidden layer의 node 개수 혹은 target dimension space 에 같이 encoding이 되는 것이다.

상품에 대한 정보만 embedding space에 정의해보았다. 모여있는 아이템을 자세히보니, 목걸이만 보여지게되었다.
이러한 데이터들은 추천시스템에 사용 가능할 것이다.



'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 40. NLP Quiz 1 (0) | 2022.06.11 |
|---|---|
| Day 39. LSTM & GRU (0) | 2022.06.09 |
| Day 38. RNN (0) | 2022.06.09 |
| Day 36. Topic Modeling (0) | 2022.06.07 |
| Day35. NLP intro (0) | 2022.03.22 |