4강.Convolutional Neural Networks
convolution 식은 아래와 같다. 우리가 사용할 2D image convolution 에서 i는 전체 이미지 공간이 되고, k라는 것은 적용할 convolution 필터가 된다.
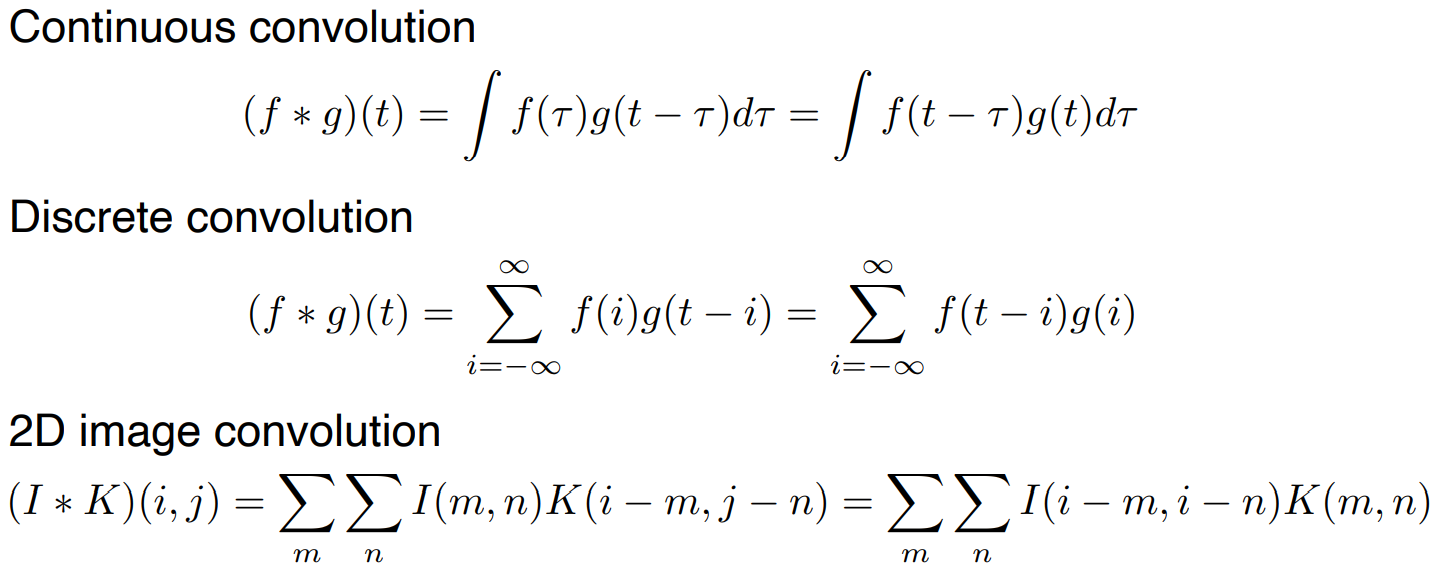
padding이나 stride를 고려하지 않고 가장 기본적인 convolution을 하게 되면, 아래 그림과 같이 된다.

필터와 이미지를 겹쳐놓은 후, 각각의 위치에 있는 픽셀 값들을 전부 곱한 후 더해준 것을 output의 한 픽셀로 나타낼 수 있다. 적용하고자 하는 필터에 따라서 output은 각각 다른 효과를 가진 이미지로 나올 수 있게 된다.
일반적으로 우리는 RGB image를 다룬다. 32 x 32 image가 있을 때 3 채널(RGB)이 들어가게 됨으로써 32 x 32 x 3 image가 된다. 5 x 5 x 3 필터를 이 이미지에 연산하게 되면, 최종적으로 28 x 28 x 1 feature가 되는 것이다. ( output의 depth는 커널(필터)의 개수만큼 생성된다.) ((일반적으로 2D image convolution kernel size는 5 x 5 이다.))

feature map의 channel 숫자는 convolution filter의 개수와 같다. 그렇기 때문에, input channel과 output feature map의 channel을 알면, 적용되는 conv feature의 크기도 계산 가능하다.

convolution 연산을 한 번 한 후, activation function을 통과시킨다. 그 후 다시 convolution 연산을 하고 그 과정을 반복하면 깊은 network가 만들어진다.
우리는 이러한 연산을 정의하는데 필요한 파라미터의 수를 아는 것이 중요하다. 32 x 32 x 3 image로 28 x 28 x 4 feature map을 얻기 위해 필요한 파라미터 수는 5 x 5 x 3 x 4가 된다. 계산 방법은 커널의 사이즈 (5 x 5)와 input channel의 숫자(3), output channel의 숫자(4) 를 곱한 것이다.

convolution layer와 pooling layer가 해주는 것은 feature extraction(특징 추출)이고, fully connected layer는 decision making( ex. classification) 을 해준다. 이러한 layer들로 cnn은 구성되어있다.

Stride
stride = 1은, conv filter가 한 픽셀씩 옆으로 움직이는 것을 말한다. 만약, stride = 2라면, 두 픽셀씩 옆으로 움직인다. 결국 stride는 conv filter를 얼마나 넓게, 또는 좁게 옮겨서 찍을 것인지를 말한다.

Padding
padding은 stride를 할 때, 공간이 부족하다면 image 주변에 공간을 늘려주는 역할을 한다. zero padding은 덧대는 공간을 0으로 잡아주는 것이다.

padding과 stride를 한 것은 다음 그림과 같다.

파라미터 수를 계산해보자. 첫 번째 layer에서 두 번째 layer로 갈 때 필요한 파라미터 개수는 다음과 같이 계산할 수 있다.
11 x 11 x 3 x 48 = 35k 이다. 이는 커널의 크기와 input channel, output channel의 크기를 곱해준 값이다. 마찬가지로 이후에도 계산해줄 수 있다. fully connected layer로 가게 되면서는 파라미터 개수가 너무 많이 필요하게 된다. 요즘 layer를 쌓을 때의 트렌드는 파라미터 개수를 최대한 줄이기 위해서 convolution layer를 깊게 쌓고, fully connected layer를 얕게 쌓는 것이 특징이다.

1 x 1 convolution은 image를 보지는 않는다. 하지만 이를 사용하는 이유는 dimension을 줄이기 위해서이다. 또한, convolution layer를 깊게 쌓으면서 파라미터 수를 줄일 수 있게 된다.

5강. Modern Convolutional Neural Networks
ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)에서 좋은 성적을 내었던 모델들 위주로 설명할 것이다.
AlexNet
AlexNet은 5개의 convolutional layer와 3개의 dense layer로 구성 되어 있다. 총 8 layer로 구성되어 있는 것이다.
AlexNet은 네트워크가 두 개로 나뉘어져 있는 것이 특징이다. 그 이유는 GPU를 최대한 활용하기 위함이다. 또 다른 특징은 input으로 11 x 11 feature를 사용한 것이다. 하지만 이는 좋은 선택은 아니다. 하나의 conv kernel이 image에서 볼 수 있는 영역은 커지지만, 필요한 파라미터의 개수는 너무 커지기 때문이다.
AlexNet가 성능이 잘 나왔던 이유는 다음과 같다.
- ReLu activation function을 사용하였다.
- 2개의 GPU를 사용하였다.
- LRN(local response normalization)을 사용하였다.
- data augmentation을 활용했다.
- dropout을 사용하였다.

AlexNet에 사용되었던 ReLu에 대해 자세히 알아보자.
- ReLu activation function은 linear model이 activation 값이 커져도 gradient 값은 그대로인 성질을 갖고 있다.
- gradient descent로 최저화하기 용이하게 된다.
- vanishing gradient 문제를 극복했다.
VGGNet
VGGNet은 2015에 1등한 논문이다. 특징은 다음과 같다.

'부스트캠프 AI Tech' 카테고리의 다른 글
| [NLP] Intro to NLP (0) | 2023.04.06 |
|---|---|
| 3주차 - 최적화 (0) | 2022.10.05 |
| 3주차 - 딥러닝 기본 (0) | 2022.10.04 |
| 2주차 - PyTorch 구조 학습하기 (0) | 2022.09.30 |
| 2주차 - Pytorch 기본 (0) | 2022.09.29 |