- DEVIEW 2019
- 발표자 : 이주홍(@roomylee) Pingpong, Scatter Lab

1. 일상대화와 BERT 이해하기
사람 → 내일 데뷰에서 발표하는데 너무 떨려
AI → ??? 이해를 하지 못했어요. 제가 할 수 없는 일이에요
사람 → 응…
위 대화는 사람이 AI 스피커에게 시도한 대화이다. AI는 위로하고 공감해주는 편안한 일상대화 능력이 부족하다.
왜 일상대화를 잘 못할까?
대화 주제가 무한하다
사람이 얘기하는 모든 주제를 커버해야 함
필요한 지식과 상식이 무한하다.
“사과는 빨갛다”, “동물은 숨을 쉰다”, “택시는 타는 것이다” 와 같은 지식과 상식은 인간이 살아가면서 당연하게 학습하지만, 모델은 그렇지 않다.
의도나 목적이 불분명하다 (=정답이 불분명하다)
“오늘 날씨가 어때?” → “(아하 날씨를 알려달라는 거구나!!)”
“아 커피 너무 맛있다” → “(??? 어쩌라고…)”
일상 대화 데이터가 많이 없는 한계점이 존재한다.
→ 핑퐁이는 대용량 데이터와 BERT를 통해 일상대화를 많이 이해할 수 있게 되었다!
도대체 BERT가 뭐길래..? (Devlin et al., 2018)
Bidirectional Encoder Representation from Transformer
11개의 다양한 NLP 태스크에서 SOTA 성능을 보였으며, 이 중 일부에서는 사람보다도 뛰어난 결과를 얻음
BERT 학습시키기
-
-
- Pre-training : 언어 전반에 대해 깊게 이해하는 단계
- Fine-tuning : 깊은 언어의 이해를 바탕으로 특정 문제에 맞춰 적응하는 단계
-
BERT Pre-training
Next Sentence Prediction(NSP)
- Input : 이순신은 그 즉시…. 파발을 보냈다. | 그 뒤 이순신은 …. 갖추도록 하였다.
- Output : True
→ 두 문장이 주어지고, 앞문장 다음에 온 뒷문장이 맞는지 맞추는 문제
Masked Language Modeling(Masked LM)
- Input : 이순신은 그 즉시 조정에 [MASK]를 올렸고, 아울러 …. 파발을 보냈다.
- Output : 장계
→ 문장에 빈칸을 뚫고, 그 빈칸에 어떤 단어가 들어가면 좋을지 예측하는 문제
💡 BERT의 저자는 NSP, MLM를 푸는 것이 언어를 이해함에 있어서 큰 기여를 한다고 말했다.
BERT Fine-tuning
Question Answering (Machine Reading Comprehension)
- Input : 이순신이 태어난 년도는 언제인가?
- Output : 1545년
Sentiment Analysis
- Input : 스토리면 스토리 액션이면 액션 너무 재밌네요!!
- Output : Positive
2. 일상대화를 위한 Dialog-BERT 학습시키기(Pre-training)
일상대화 데이터
스캐터랩은 ‘연애의 과학’이라는 서비스로부터 100억건의 한국어 카카오톡 데이터, 2억 건의 일본어 라인 데이터를 수집함
일상대화 데이터 전처리 : Tokenization
- 형태소 분석 기반
- Mecab, Khaiii 등
- 한국어는 다른 언어와는 다르게 조사가 존재한다. 이 부분에 있어서 많은 효과를 보임
- Subword 기반
- SentencePiece, WordPiece 등
- BERT의 tokenizer이다.
- Combined Approach
- Mecab으로 먼저 자르고 SentencePiece로 또 자르고
과연, 어떤 방법이 가장 좋을까?
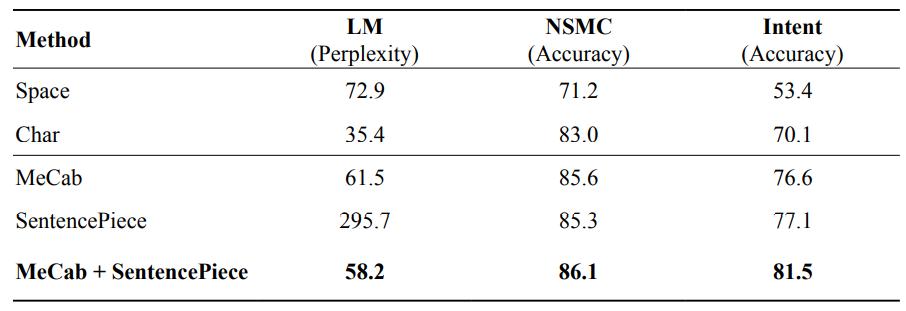
Mecab + SentencePiece가 모든 task에서 가장 높은 성능을 보임
65억 token, 50 GB의 데이터로 학습 시켰으며, 30000개의 vocab size를 가진다.
Pre-training, 그냥 하면 될까? → 대화에 알맞은 Pre-training 전략

고민1. 대화체로 학습시켜도 괜찮을까?
보통의 BERT들은 문어체 기반의 데이터로 학습을 시켜왔다. 하지만, 대화체는 문어체와는 많이 다르다. 과연 대화체로 학습시켜도 괜찮을까?
차이점 1. 문어체는 한 문장의 길이가 길고, 대화체는 한 문장의 길이가 짧다.
차이점 2. 대화체는 대화의 생략이나 변형이 빈번하다.
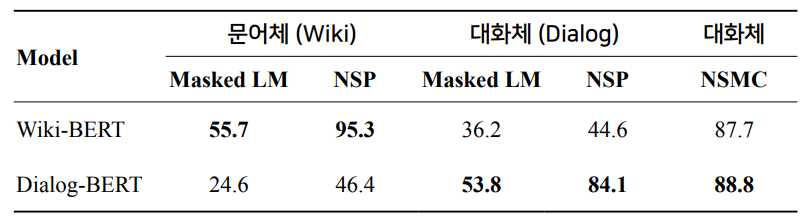
-
- 대화체 데이터로도 충분히 학습이 잘 된다!
- 서로 다른 도메인에서는 성능이 매우 떨어진다
고민2. Turn에 대한 구분이 있어야 하지 않을까?

두 도메인이 다른 이유 중 하나는, 대화에는 Turn이 존재한다는 점이다.
즉, 대화는 두 개의 흐름이 서로 상호작용을 하며 이어져나간다.
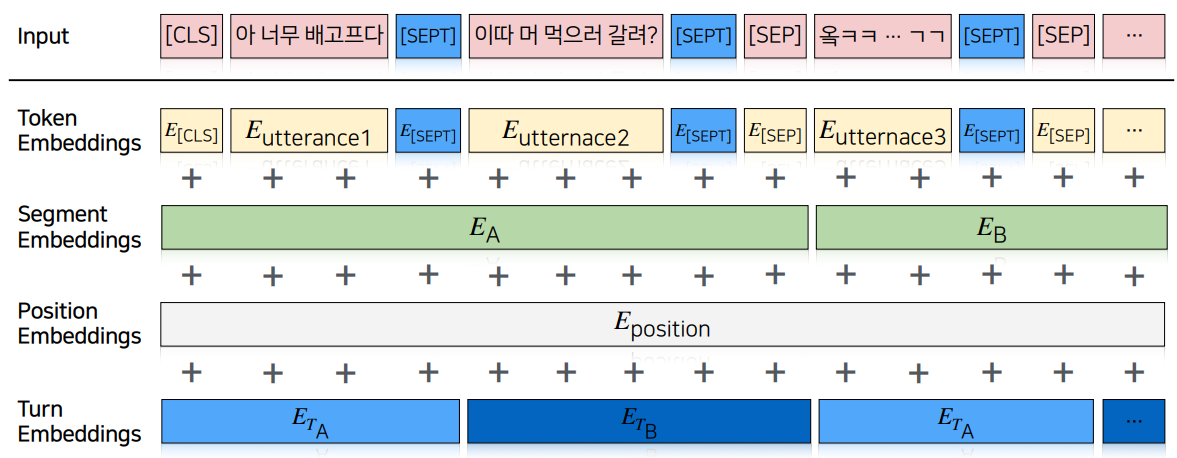
turn에 대한 구분을 위해 [SEPT]라는 special token을 넣어줌
추가적으로, 각 발화에 해당하는 화자에 대한 embedding을 만들어 더해줌
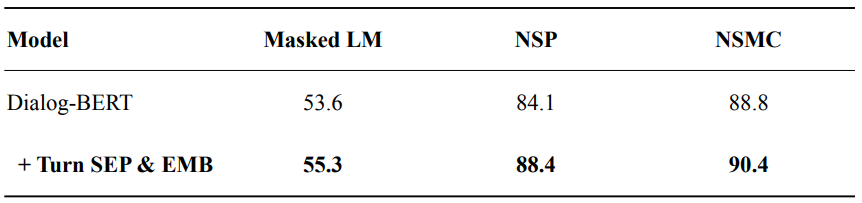
→ 각 발화 문장과 대화의 흐름을 더 잘 이해할 수 있게 되었다.
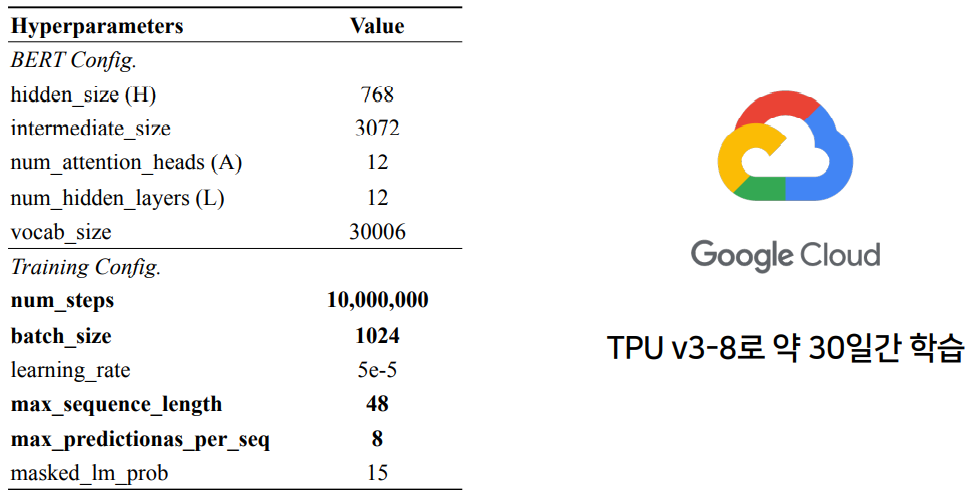
Dialog-BERT Configuration
3. Dialog-BERT로 일상대화 태스크 해결하기(Fine-tuning)
일상대화 태스크는 user input을 받고, 어떤 일련의 과정을 거친 후 output을 도출해나간다.
일상대화 태스크
일상대화 태스크는 매우 다양하기에 아래와 같은 세 가지 태스크로 해결하고자 함
Task 1. Semantic Textual Similarity - 주어진 두 문장이 의미적으로 유사한가?
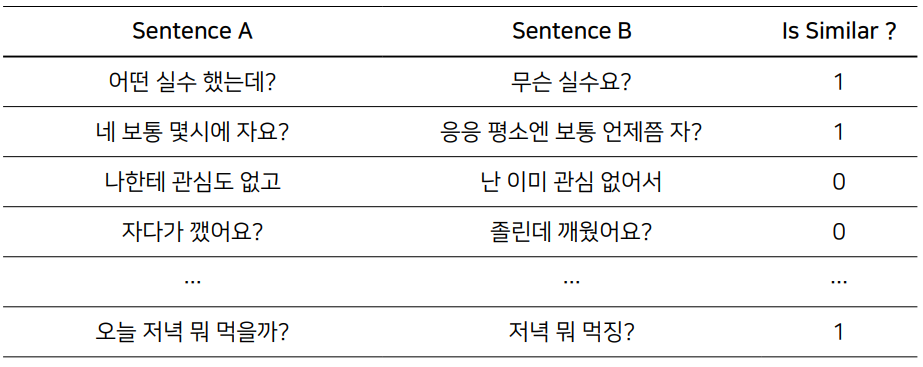
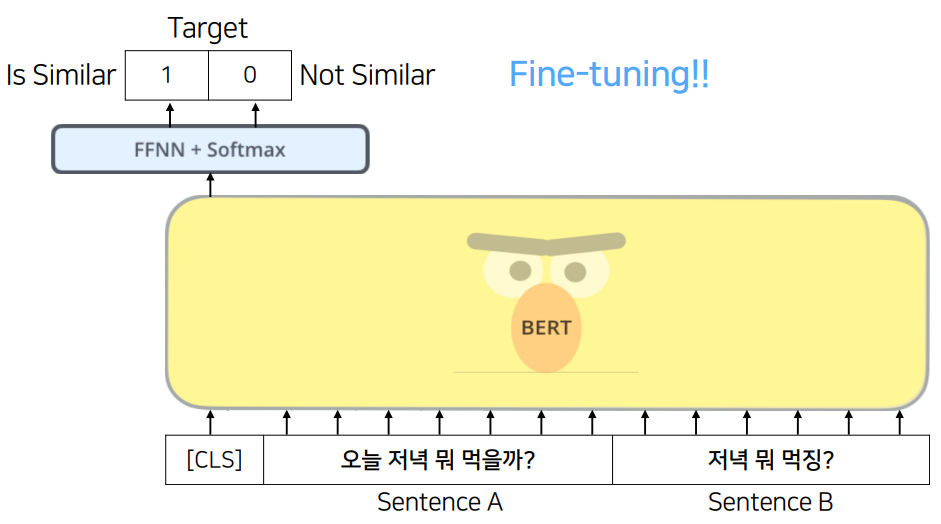
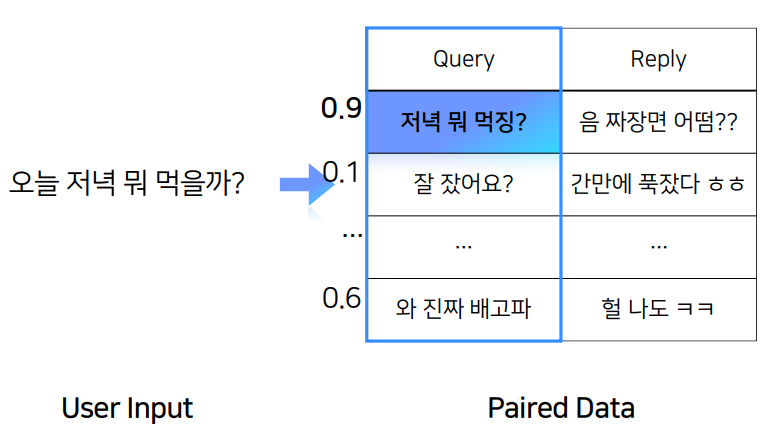
FAQ와 비슷한 방식으로 진행되면 이해가 쉬울 것이다. user input을 가지고 paired data의 query와 얼마나 유사한지 판단하여 reply를 내뱉는 형태이다.
Task 2. Query-Reply Matching - 주어진 문장 다음에 올 문장으로 적절한가?
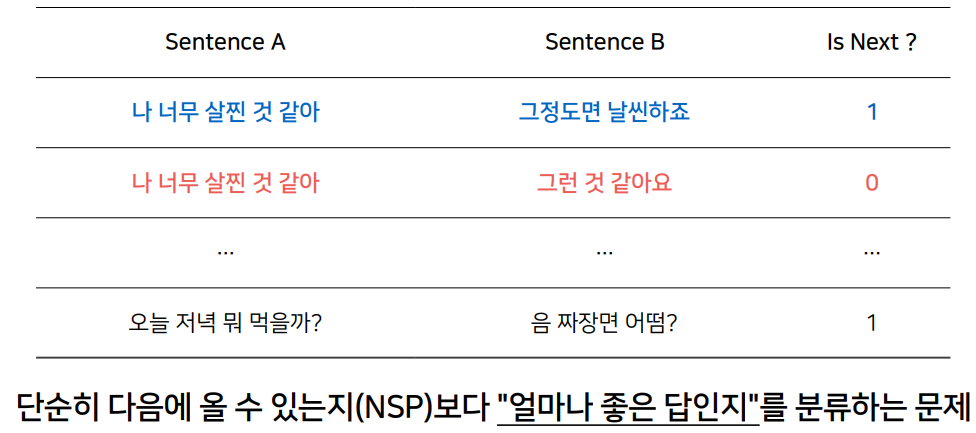

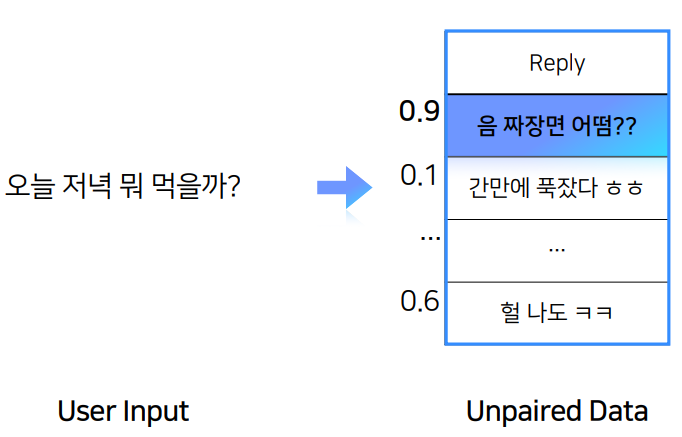
user input을 넣어주면, unpaired data가 다음으로 올 문장이 적절한지 확률값을 내뱉음
Task 3. Reaction Classification - 주어진 문장 다음에 올 리액션은 무엇일까?
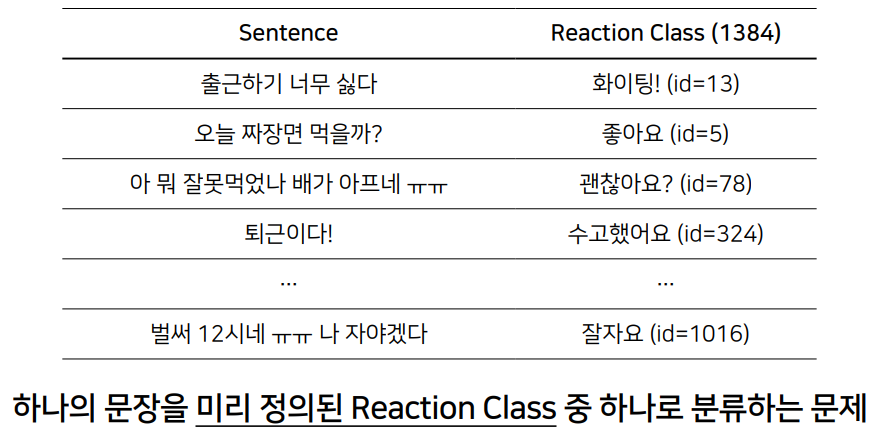
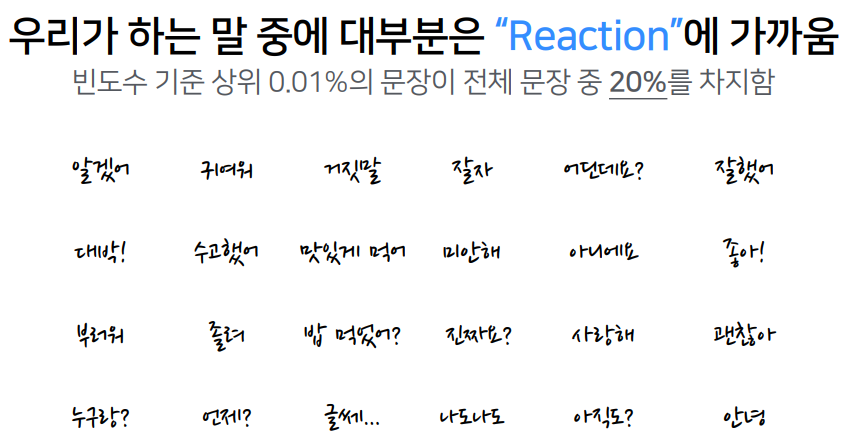
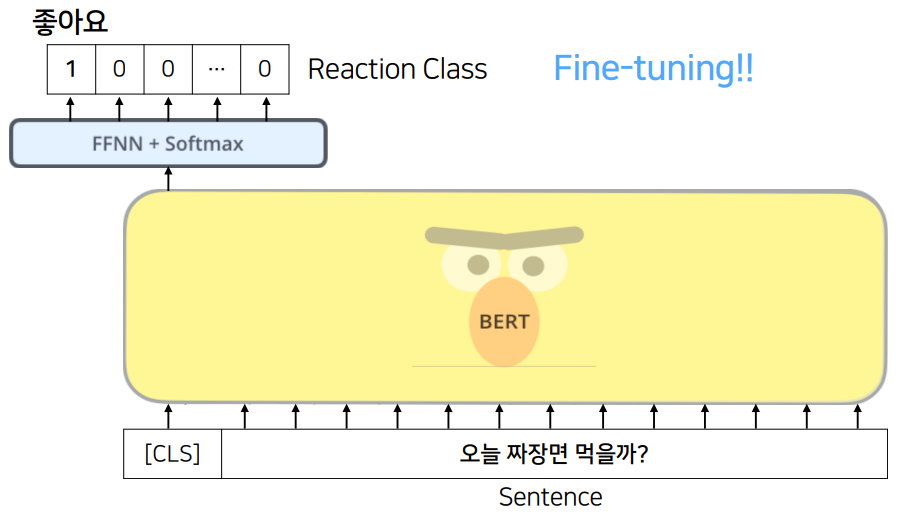
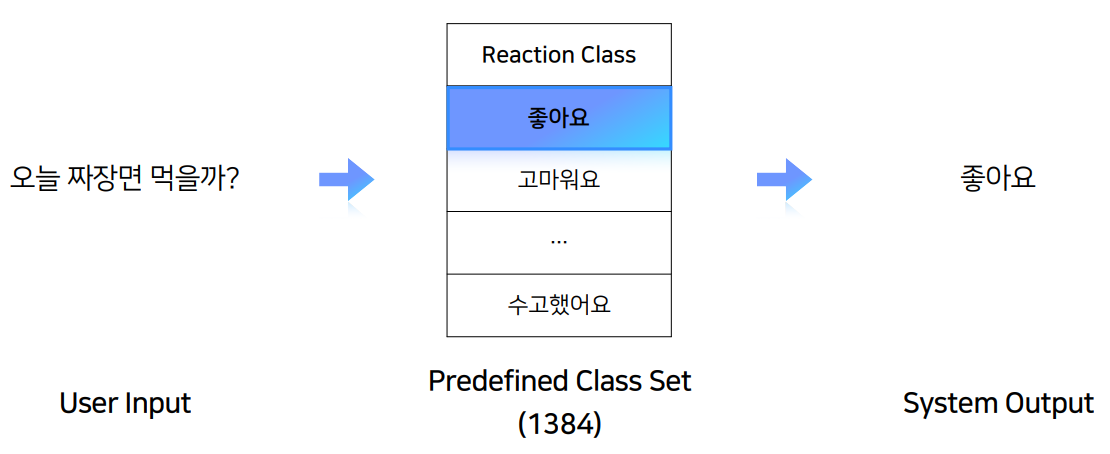
위 세 가지 태스크를 서로 상호보완적으로 적절한 답변을 생성할 수 있다.
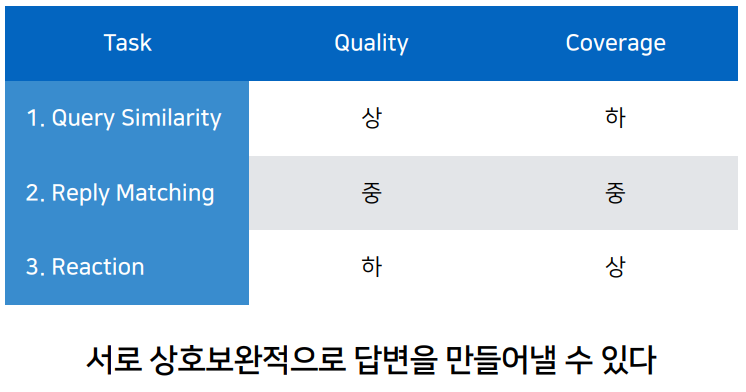
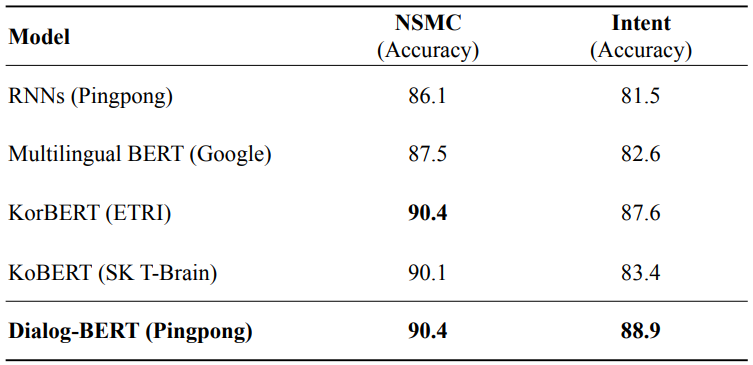
일상대화 태스크 성능
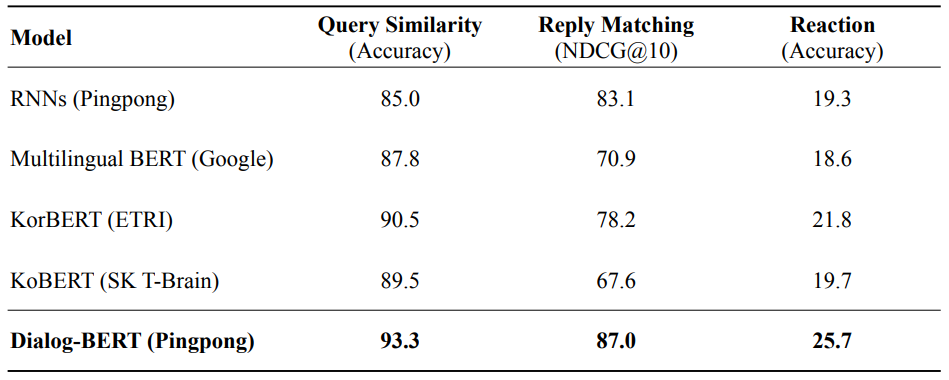
대회 관련 NLP 태스크 성능
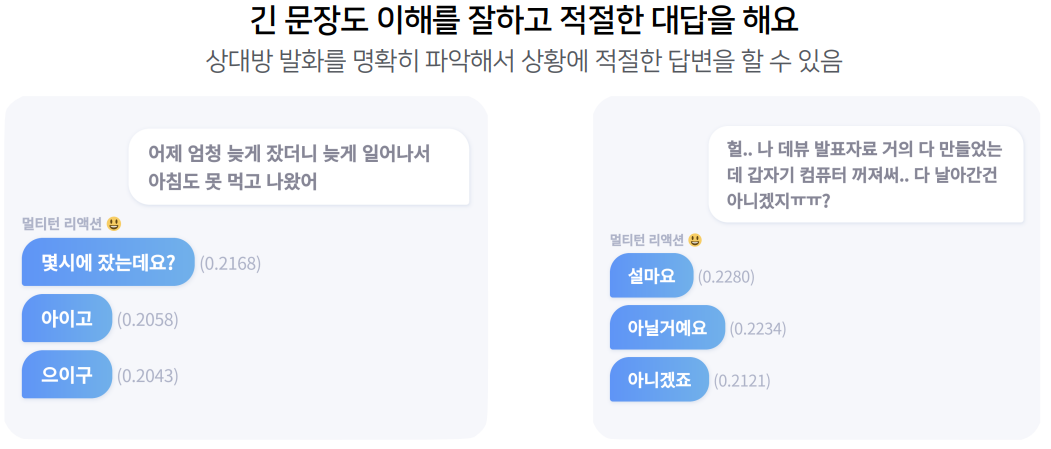
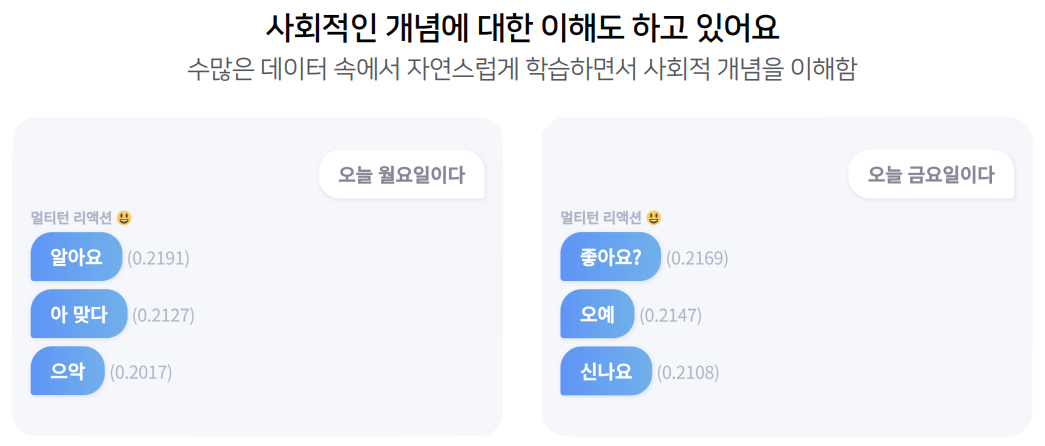
인공지능과 대화해보기
4. 서비스를 위한 BERT 경량화
BERT는 기존 RNN에 비해 parameter가 4배 정도 많고, inference time이 약 3배 정도 더 오래 걸린다.
모델 경량화 : Knowledge Distillation
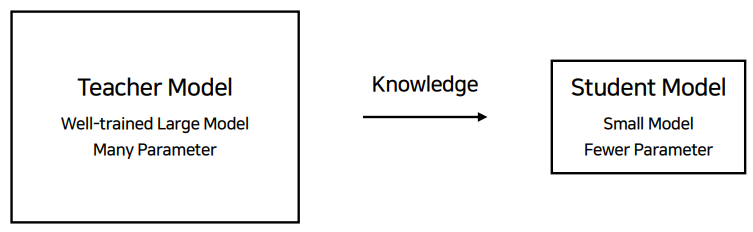
아주 잘 학습된 거대한 모델이 teacher model이 되어 작은 모델이 좋은 성능을 낼 수 있도록 가르친다는 방법이다.
아래는 예시이다.

분산된 soft label로 학습을 시키는 것이다. large model은 small model에게 지식을 전수해준다.
BERT Distillation

diatillation은 pre-training이 아닌 fine-tuning에 적용된다.

BERT-base는 아니더라도 경량화를 한 모델이 성능도 나쁘지 않았으며 속도가 많이 개선된 모습을 보였다.
Multi-task distillation
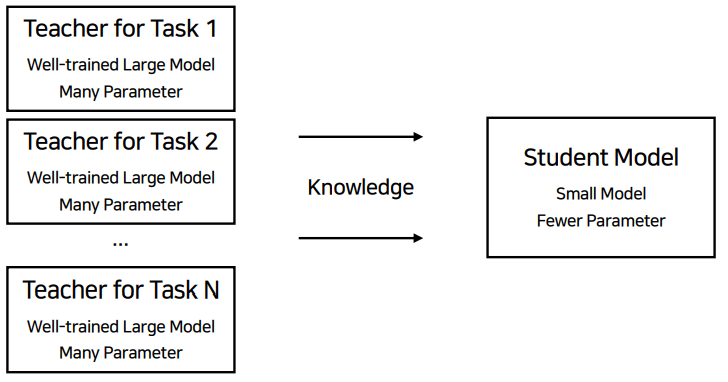
오히려 distillation을 했을 때 성능이 더 오름을 볼 수 있다.
5. Conclusion
- BERT, 이제는 선택이 아닌 필수!
- 태스크의 문체에 맞춰서 BERT를 사용하면 더 좋아요!
- Distillation 꼭 해보세요!
https://tv.naver.com/v/11212753
Dialog-BERT: 100억 건의 메신저 대화로 일상대화 인공지능 서비스하기
NAVER Engineering
tv.naver.com