오늘은 Attention의 개념을 다뤄보겠습니다.
Sequence-to-sequence 구조의 RNN계열 모델에서 attention이 왜 필요한지, 어떻게 적용될 수 있는지 살펴보도록 하겠습니다.
Sequence to sequence

sequence to sequence model을 보면, 한쪽은 encoder, 다른 한쪽은 decoder라는 부분으로 나뉘어져 있다. 간단하게, encoding은 문장이 들어가는 부분, decoding은 문장이 나오는 부분이라고 생각하자.
이들은 각각 RNN 혹은 LSTM 혹은 GRU를 기반한 구조가 된다.
위 그림은 챗봇의 예제로써, 질문이 들어왔을 때, 그것에 답을 하는 task를 수행하는 것이다. 이 질문은 LSTM에 기반해서 하나씩 입력을 받아 다음 step으로 넘기는 과정을 통해 필요한 정보만을 저장하는 등의 형태로 마지막 hidden state vector가 최종적으로 나오게 된다. 이는 문장 전체에서 필요한 정보만을 갖고 있는 벡터로, 문장을 대변한다고 할 수 있다.
질문에서 필요한 정보를 전부 추출한 후, 이를 바탕으로 적절한 답에 해당할 법한 단어들을 sequence 형태로 뽑아주어야 한다. 이 과정은 오른쪽 그림의 decoder 파트에서 이루어진다. 이 decoder에서는 새로운 RNN cell이 동작을 하게 되고, 여기서는 단순하게 encoder에서 최종적으로 나온 hidden state vector를 마치 이전의 time step에서 넘어온 hidden state vector처럼 생각을 한다. 이 hidden state vector를 토대로 decoder에서의 첫 번째 단어를 예측해야할 것이다. 이렇게 예측된 첫 번째 단어와 여기서 나온 hidden state vector는 decoder의 두 번째 단계에서 input으로 들어가게 되며 그 다음 출력을 에측한다. 이와 같은 과정을 반복해서 decoder 과정은 끝이 난다.
이러한 과정을 가진 모델이 sequence to sequence 모델이다.
NLP의 분야의 sequence to sequence 모델에서는 기본적으로 input sequence를 읽어들일때, bidirectional LSTM 혹은 bidirectional GRU를 사용한다. 이는 보통 encoder부분에서 사용된다. bidirectional model은 동일한 input과 모델들을 forward 방향과 backward 방향에서 최종적으로 나오는 hidden state vector들을 concat하여 사용하는 model이다. 이 과정을 통해서 필요한 정보만을 추출해낼 수 있다.
하지만, decoder에서 정답을 생성할 때에는 bidirectional model을 사용하지는 않는다.
Attention

위 그림처럼 encoding을 하는 것은 약간의 문제가 생길 수 있다.
위의 예시를 보자. 'He', 'loved', 'to', 'eat' 이라는 단어들은 one-hot vector이겠지만, 이들을 word embedding을 가지고 학습을 했으며 이들을 2차원 벡터로 나타냈다고 가정하자. 처음 input은 'He' 라는 embedding vector와 h0라는 hidden state vector가 되고, 이들을 통해서 만들어진 것이 h1이 될 것이다. h1도 2차원 벡터라고 하자. 이러한 방식으로 hidden state vector들이 생길 것이다.
h3은 'He', 'loved', 'to'의 정보를 담고 있는 vector가 될 것이고, h1은 'He'의 정보만을 담고 있는 vector가 될 것이다. 마지막 vector인 h5은 'He', 'loved', 'to', 'eat', '.' 이라는 모든 의미를 담고 있는 2차원 벡터일 것이다. 우리는 이렇게 매 time step의 hidden state vector에 계속해서 정보가 쌓이게 된다. 하지만, 이 벡터에는 정해진 공간이 있고, 이는 많은 정보를 담기에 한정적이다.
따라서, 마지막 hidden state vector(h5)에 모든 정보를 담아야 한다는 점이 문제점이 된다.
이 문제를 해결하기 위해 decoding을 할 때, 마지막 hidden state vector만 주는 것이 아니라, encoding을 하면서 생성된 모든 hidden state vector들을 넘겨주는 것이다. h5는 모든 정보를 담고 있지만, 오래된 정보들은 많이 잊었을 것이고, 최근에 입력된 정보들은 잘 기억할 것이다. 이것은 단어 하나하나를 입력으로 주는 것보다, 단어 사이의 맥락을 파악할 수 있기 때문에 이러한 형식의 hidden state vector로 전해주게 된다. 그렇게 된다면, 이 hidden state vector는 조금 더 유의미한 vector가 될 것이고, 이렇게 유의미한 hidden state vector를 만들어 주는 과정을 encoding이라고 한다.

이렇게 encoding 단계에서 나온 h1, h2, h3, h4, h5 ( encoding vector )를 전부 decoding 단계에 주면, 과연 decoding 단계에서는 어떻게 이를 수행할까?
기계 번역을 예시로 들 때, decoding 단계에서 첫 번째로 출력될 단어는 '그는' 이다. 우리는 주어를 생성해야하므로 'He' 라는 단어의 정보를 많이 갖고 있는 h1를 중점으로 출력을 생성해야할 것이다. 이런식으로 decoding을 할 때, 각각의 time step에서 어떠한 encoding vector를 써야할지에 대한 선택의 이슈가 생긴다.
이러한 선택을 Attention 이라고 부른다.
첫 번째로 출력될 단어는 '그는' 이고, 이에 해당하는 'He'라는 정보를 가장 많이 담고 있는 h1을 골라주는 역할을 attention module이 한다.
두 번째로 출력될 단어인 '먹는' 은 h4와 직접적으로 관련이 있고, 단어가 출력 될 것이다.
세 번째로 출력될 단어인 '것은' 은 h3와 직접적으로 관련이 있고, 단어가 출력 될 것이다.
이러한 순서를 보면 h1 - h4 - h3 - h2 - h5 라는 순서가 됨을 알 수 있다.
맨 처음으로 h1이 들어오면, h1은 이전 단계에서 무슨일이 벌어지고, 다음 단계에서는 어떠한 정보가 필요한지를 넘겨주게 된다. 우리는 h1이 다음 step에서는 목적어를 찾는다는 정보를 포함하는 벡터가 될 것이다.
encoding 단계에서 넘어온 hidden state vector로 '그는' 이라는 단어가 출력되었고, 그리고 나서 생성된 hidden state vector를 g1이라고 해보자. g1은 hidden state vector와 마찬가지로 2차원 벡터이다. 이 g1을 h1, h2, h3, h4, h5와 비교를 한다. (내적을 통해서 내적에 기반한 유사도를 바탕으로 비교한다.) 우리는 이 내적을 한 값을 softmax를 취함으로써, input sequence 5개에 대한 확률분포를 구할 수 있게 된다. 이것은 5개의 vector중에서 누구를 찾고싶은지를 상대적으로 나타낸 비율이라고 생각할 수 있다. 우리는 이 비율을 가중치로 적용해서 가중합을 내어 하나의 2차원 벡터를 뽑을 수 있다.
내적을 기반으로 하므로, 이것은 곱셈 기반의 attention이다.
이해를 돕기 위해, 아래에 다른 예시를 들어보자.

encoding vector가 3개만 있다고 하자. 여기서 g1은 [ 2 -3 ] 이다. g1과 encoding vector들을 전부 내적하면, -4, -6, 19가 나온다. 이것을 softmax를 취하면, 대략 1%, 2%, 97% 정도가 나오게 될 것이다. 이러한 %를 각각의 encoding vector에 가중치로 곱해준다. 그리고 난 후, 가중치가 곱해진 encoding vector들을 전부 더하자. 이를 가중평균을 낸다고 말한다. 그렇게 되면, 가장 높은 값을 가지는, 97%의 가중치가 곱해진 vector가 우리가 원하는 정보라고 할 수 있는 것이다.
이렇게 만들어진 vector를 RNN에 추가적인 입력으로 사용하게 된다. 이는 decoding에서의 RNN의 각 time step의 입력은, 이전에 만들어진 단어('나는') 가 xt과 gt-1이 들어온다. 그 뿐만 아니라, 앞에서 가중평균으로 구한 vector까지 입력으로 넣는다.
따라서, attention 기반의 모델은 decoding 단계에서 input으로 총 3개를 받는다. 이것으로 다음 단계의 gt를 생성하게 되고, output을 생성하게 된다.
내적이라는 것은 결국, 곱셈을 기반으로 similiarity를 구하는 것이다.
이것을 곱셈 기반이 아닌, 다른 형태로도 attention weight를 구할 수는 없을까? 밑의 예시처럼 할 수 있다.
이는 concatnation 기반, 혹은 additive model이라고 한다. 이 방법은 h1, h2, h3를 하나씩 비교하는 방식이다.
먼저, g1과 h1을 입력으로 받아서 fully connected neural net을 구성하게 된다. 이를 노드 하나로 뽑는다. 이 노드가 softmax에 들어가게 되는 similiarity의 역할을 하게 된다. 이런식으로 나머지도 구한다.
이렇게 concat을 기반으로 vector를 neural net의 입력으로 넣는 것이다.

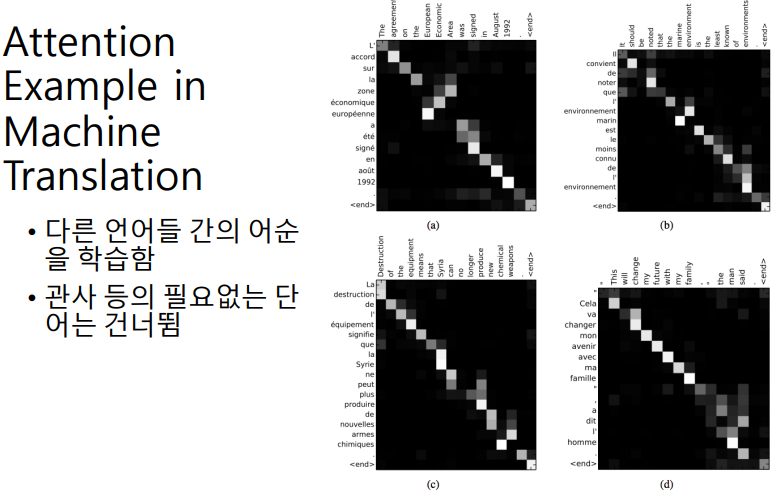
이렇게 attention 모델을 돌려보고 난 후, 내부적으로 어떤 단어에 가중치를 걸었는지를 시각화 한 것이다. 가로축이 입력 sequence이고, 세로축이 출력 sequence이다.
이렇게 Attention이라는 것은 결국 비슷한 벡터를 찾고, 그 비슷한 벡터끼리 좀 더 집중하는 것이다.
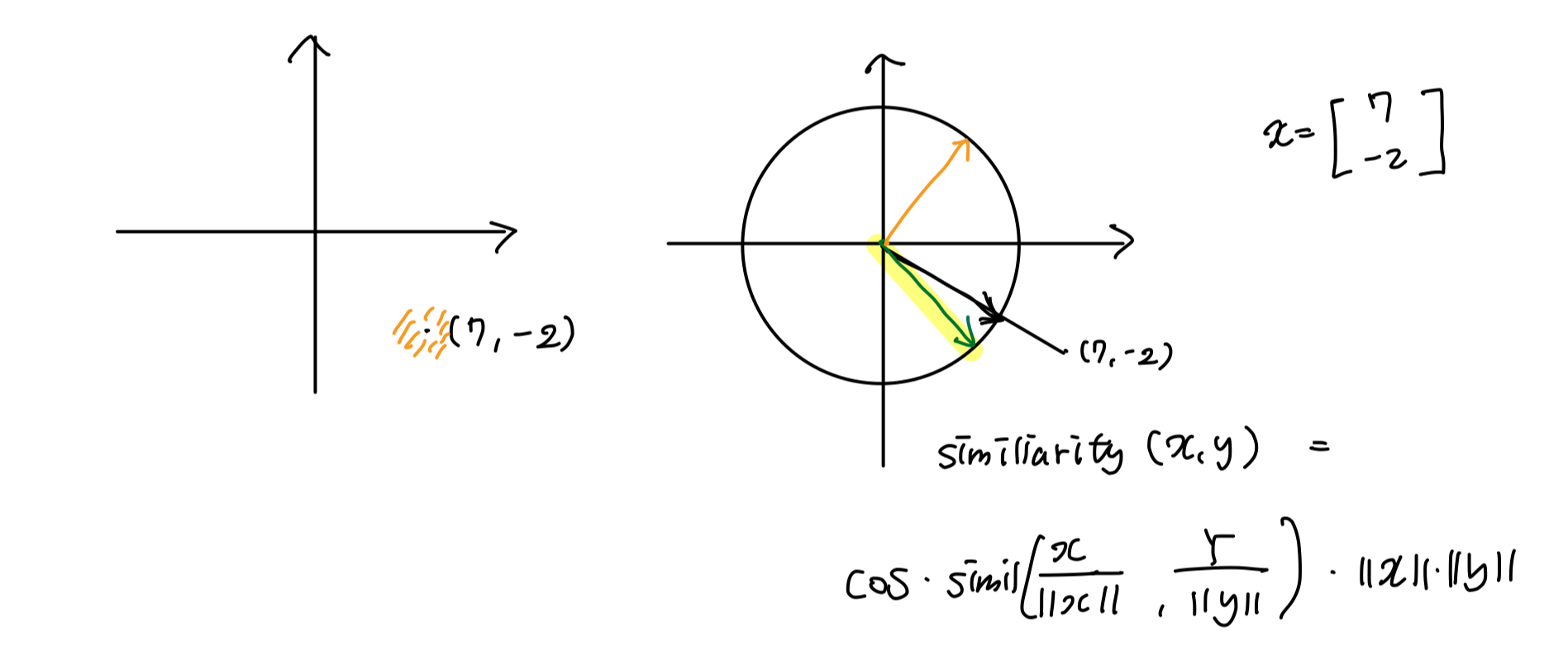
예를 들어, 2차원 벡터인 [ 7 -2 ]가 있다고 하자. 이것은 좌표평면 상에서 표현을 할 수 있을 것이다. 이 벡터와 유사한 벡터는 과연 무엇일까? 그것은 그 벡터 주변을 비슷하다고 말할 수 있을 것이다. 우리는 이렇게 비슷한 것에 집중해서 attention을 걸 수 있을 것이다.
또한, 벡터가 비슷하다는 것은 다음과 같이 정의할 수도 있다. 좌표 평면 위에 반지름이 1인 원을 그린 후, (7, -2) 벡터를 그린다. 이 벡터는 원 위의 벡터와 같은 방향을 갖는다. 이런 경우에는 비슷한 벡터를 찾을 때, 원 위의 벡터를 가지고 비슷한 방향을 가리키는 벡터가 비슷하다는 것에 가까울 것이다. 이 벡터에 길이를 곱해서 정의할 수도 있을 것이다.
이렇게 similiarity를 정의하는 방법은 다양하다.
Trends of Attention

NLP의 역사는 Machine Translation과 큰 연관이 있다.
이 Machine Translation이 NLP의 꽃이라고 생각할 수 있을 것이다. machine translation은 가장 중심에 있으며, machine translation의 발전이 곧 NLP의 발전이라고 봐도 무방할 정도라고 생각한다.
이 MT의 경우에는 딥러닝이 나오기 전까지는 통계기반의 machine translation을 많이 사용했다. 이러한 확률론 모델이 많이 나왔지만, 그 이후로 neural machine translation model이 굉장히 각광받게 된다. NMT가 성능이 매우 좋아진 이유로는 computer power가 굉장히 좋아졌다는 점과 데이터가 많아졌다는 점을 꼽을 수 있다.
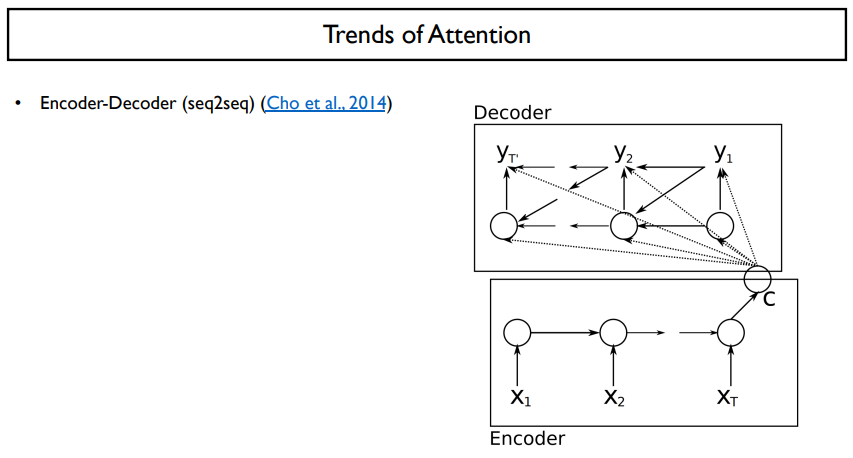
neural machine translation에서 가시적인 성과를 보인 모델은 encoder-decoder 모델이다. 사실상 NMT의 기초가 되는 모델일 것이다.
encoder-decoder model의 구조는 위에서 설명한 것과 같다.
Machine translation의 가장 큰 문제는 두 개의 sequence가 있을 때, 이 두 개의 길이가 맞지 않는 다는 것이었다. 이 문제는 LSTM을 사용한 seq2seq 모델의 구조로 해결되었다. (이는 NMT에 사용되었다.)
하지만, 입력 문장이 너무 길어지면, hidden state vector가 정보를 저장하는데 한계가 생기게 되는 문제점이 발생하였다.
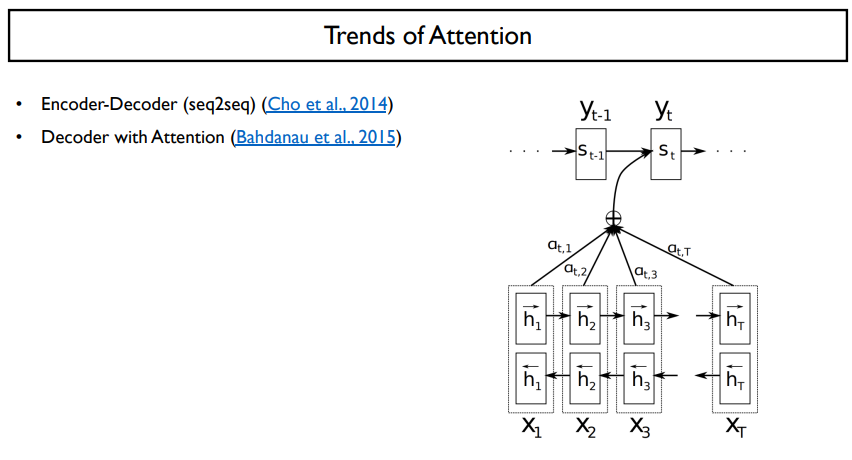
그래서, 이러한 한계점을 극복하고자 decoding을 할 때, attention을 적용하게 되었다.
그러면, 길이가 다르더라도 원하는 부분을 예측할 수 있게 되었다.

encoding을 할 때 attention을 적용할 수는 없을까?
이는 MRC task에서 많이 쓰인다.

MRC는 machine reading comprehension의 줄임말로, paragraph를 보고, 질문에 맞는 답을 예측하는 task이다.
paragraph는 많은 문장으로 이루어져 길이가 매우 길기 때문에, encoding을 할 때 attention을 적용해주어야 할 것이다.
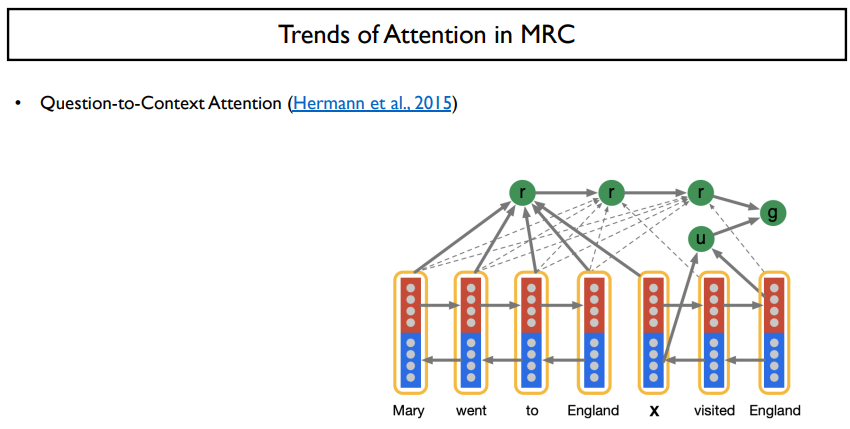
이 때, 나온 아이디어는 Question-to-context attention으로, 질문에서 context를 attention하는 것이다.
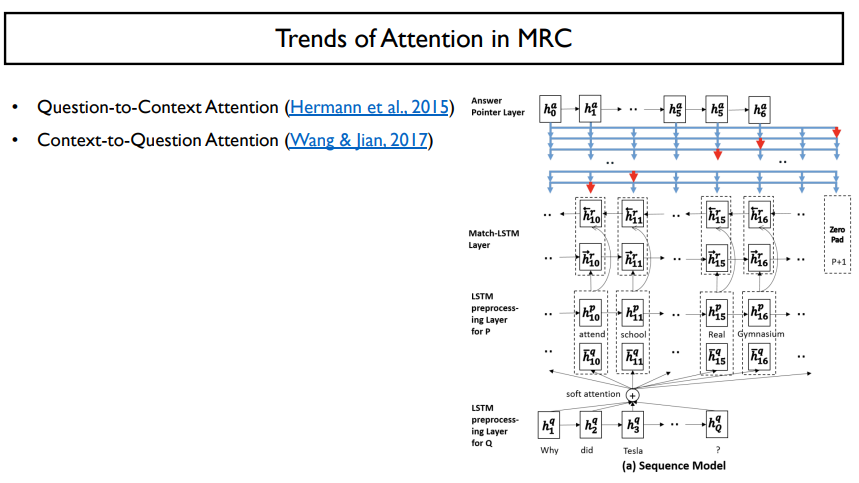
두 번째 나온 방법은 거꾸로 context에서 question을 참조하는 것이다.
이 context-to-question attention은 squad dataset을 처리할 때 매우 유리하다.
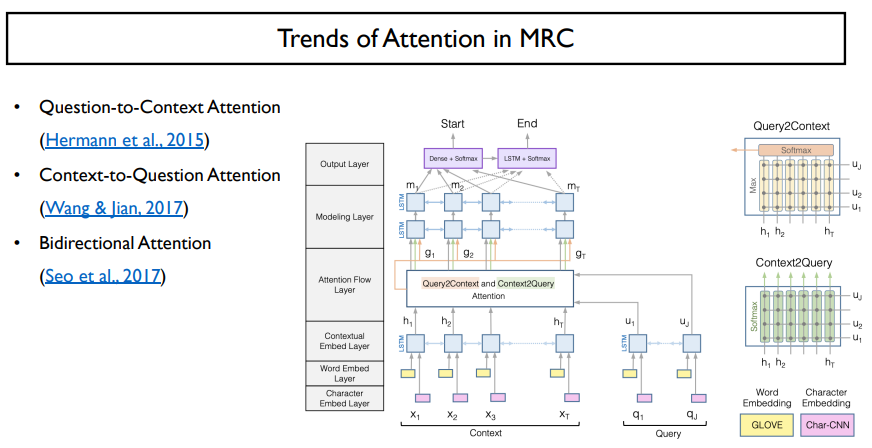
그렇다면, 둘 다 하는 것도 가능하지 않을까? 라는 생각에서 나온 것이 bidirectional attention이다.
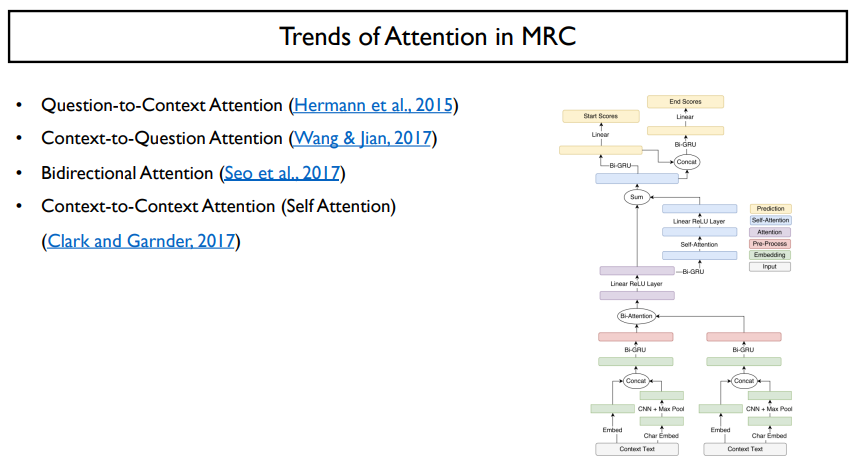
최근에는 가장 성능이 좋은 context-to-context attention을 사용한다.
이 self attention은 transformer라는 지금까지 최고인 모델까지 발전되었다.

'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 43. Tokenization (0) | 2022.06.15 |
|---|---|
| Day 42. Preprocessing (0) | 2022.06.14 |
| Day 40. NLP Quiz 1 (0) | 2022.06.11 |
| Day 39. LSTM & GRU (0) | 2022.06.09 |
| Day 38. RNN (0) | 2022.06.09 |