오늘은 자연어 처리 데이터를 전처리 하는 과정을 배워보겠습니다.
전처리하는 파이프라인과 전처리하는 과정에서 활용할 수 있는 모듈을 배우고, 다룬 모듈을 활용해 간단하게 데이터를 크롤링하여 전처리하는 실습을 진행해보겠습니다.

text data를 모델이 encode 할 때에는 아래와 같은 파이프라인을 거치게 된다.
Normalization -> pre-tokenization -> tokenization -> post-processing
먼저, raw string이 덜 랜덤하고 깨끗해지는 과정을 통틀어 Normalization이라고 말한다. 예를 들면, white space(여백)을 제거하고, 특수기호를 제거하거나, 대소문자가 섞여있을때 하나로 통일해주는 과정이 있다.
이렇게 normalization 과정을 통해서 1차적으로 정제된 데이터는 pre-tokenization 과정을 통해서 더 작은 단위로 쪼개지게된다.
pre-tokenization이라는 이름에서도 알 수 있듯이, tokenization 알고리즘을 수행하기에 앞서서 token의 upper bound를 정하는 과정이다. 즉, pre-tokenization 과정을 통해 문장을 단어 단위로 나누면, 나누어진 pre-token이 하나의 word로 취급이 되고, 이 word를 tokenization에서는 sub-word로 쪼개지거나 whole-word 자체로 존재하게 된다.
그 다음, tokenization 단계에서는 Byte Pair Encoding(BPE)와 같은 알고리즘으로 전체 코퍼스를 참조해서 단어를 단어보다 더 작은 단위로 쪼개게 된다. 그리고 End Of Setence(EOS), Start Of Sentence(SOS) 와 같은 special token을 사용해서 후처리 과정을 거치게 되면, 비로소 모델의 input으로 활용할 수 있는 data set의 형태가 된다.
text data는 용도에 맞게 정제, 정규화하는 과정을 거쳐야 더 좋은 성능을 낼 수 있다. 이를 영어로 말하면 cleaning, normalization이라고 한다.
cleaning은 noise data를 corpus로부터 제거하는 과정이고, normalization은 같은 단어이지만 표현 방법만 다른 경우, 이를 정규화해서 같은 단어로 통합시키는 과정을 의미한다.
cleaning, normalization 기법으로는 여러 가지가 있다.
첫 번째로, 규칙에 의해서 표기가 다른 단어들을, 모두 같은 의미임을 명시함으로써, 통합하는 것이다.
예를 들어, '간다' 라는 문장은 문장표현에 따라서 '가는', '감', '갔다'로 표현이 가능하다. 이런식으로 바뀌는 것은 모두 어간이라는 '가' 뒤에 문법적으로 어떠한 의미를 덧붙이는 어미가 변하면서, 동일한 뿌리를 가지고 있지만, 다양한 다른 단어들로 표현이 되고 있다.
이러한 어간을 추출하는 기법에는 stemming, lemmatization이 있다.
두 번째로는, 영어 데이터의 경우 대/소문자를 통합하는 과정이다. ( Cased / Uncased )
예를 들어 'Table' 과 'table' 이라는 단어들은 모두 '책상'이라는 의미를 가지는 것은 동일하다. 하지만, 컴퓨터의 경우에는 형태가 다르기 때문에 다른 단어라고 인식한다. 따라서, 모두 대문자로 통합하거나 소문자로 통일하는 과정이 필요하다.
세 번째로는, 불필요한 단어를 제거하는 것이다. 불필요한 단어란, 특수문자와 같이 자연어가 아니고 아무런 의미가 없는 단어이기도 하고, 분석에 있어서 큰 도움이 되지 않는 단어도 포함된다.
등장 빈도가 너무 적은 단어같은 경우에는 전체 데이터 셋을 분석할 때, 큰 도움이 되지 않을 수 있으며, 영어에서 길이가 매우 짧은 단어도 불필요한 단어에 포함될 수 있다. (ex, 'in', 'on'은 큰 의미를 가지고 있지 않음) 따라서, 큰 의미가 없는 단어 및 전치사와 같은 한글자짜리 단어를 제거할 수 있다. 그러나 한국어에서는 영어와 다르게, 언어적 특성이 다르기 때문에, 단순히 한글자짜리 단어를 제거하는 것이 큰 도움이 되지는 않는다.
마지막으로, 제거하고자하는 noise data를 특정 패턴을 통해서 잡아낼 수 있다.
예를 들어, html 문서를 크롤링 한 후 html tag나 원본 텍스트 이외에 규칙적으로 반복되는 단어들을 잡아내는 것이다.
Regular expression(정규 표현식)이 무엇인지 알아보도록 하자.
Regular expression은 text data에서 특정 패턴을 인식하는데 아주 유용한 도구로 사용된다. python에서는 정규표현식 모듈로 re 를 지원한다. re 패키지와 NLTK라는 자연어처리 패키지를 활용하여 정규 표현식을 활용할 수 있다.
위 식은 대/소문자로 a부터 z까지의 문자가 아닌 것은 모두 빈칸으로 대체하는 명령어이다. 이러한 명령어를 통해서 위 문장에서 대괄호 또는 숫자가 빈칸으로 대체된 것을 볼 수 있다.
정규 표현식에는 여러 특수문자를 활용한 문법이 있다.
.(온점)은 one length character를 나타내고, ?, *, +, {} 같은 경우에는 글자가 몇 번 반복되는지 횟수를 정의해주는 특수 기호이고, ^, $는 문장의 시작과 끝을 정의해준다. [ ] 는 대괄호 안의 문자 중 하나의 문자와 매치하는 경우를 이야기한다. ^표시가 대괄호 안에 있다면, ^ 다음에 오는 문자를 제외한 문자를 매치하는 의미를 지닌다. | 는 or의 역할을 한다.
역 슬래쉬를 사용해서 정규 표현식을 활용할 수 있다.

정규 표현식 모듈에서 지원하는 함수는 위와 같다.
우리가 여기서 많이 쓰는 것은 re.complie(), re.search(), re.match(), re.sub() 일 것이다.
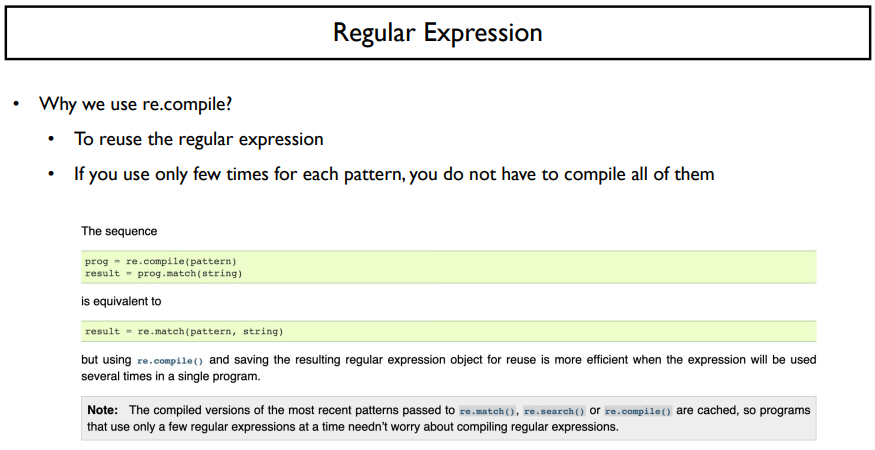
왜 우리는 re.compile을 써야하는가? 재활용하기 위해서이다. 예시는 위의 예제를 보면 알 수 있다.

간단한 예시이다. 위 정규 표현식은 어떤 의미를 가지고 있을까?
이는 한 글자 혹은 한개의 숫자로 이루어진 string문자열에 매칭이 된다.
^(캐럿) 과 $(달러) 표시로 해당 표현이 둘러싸여 있고, [ ] (대괄호) 안에 하나의 글자 또는 하나의 숫자 ( \w = [a-zA-z0-9] )이고, 대괄호 안에서의 * 는 * 그대로를 의미한다.
즉, 글자나 숫자나 *를 포함한 1개의 패턴을 의미한다.
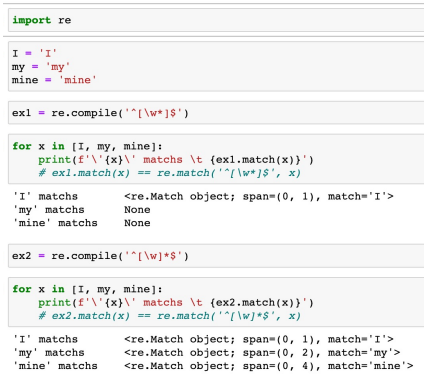
예시는 위와 같다. re 패키지를 import 해주고, ' I ' (한 글자), 'my' (두 글자), 'mine' (네 글자)를 가져왔다.
위에서의 regular expression을 ex1로 compile을 해준다. 그 후 가져온 글자들을 하나씩 매칭해주도록 한다. 매치 결과로는 'I'가 들어왔을 때는 'I' 로 매칭이 되지만, 그 외의 나머지 단어들은 매칭이 되지 않는 것을 알 수 있다. 매칭이 되지 않는 이유는 글자의 수가 1개가 아니기 때문이다.
ex2에서는 *가 대괄호 밖에 있는 경우의 예시를 보여준다. 이 경우에는, 문자열의 처음과 끝 사이에 단어나 숫자가 등장하고, 이 패턴이 0번 이상 등장하는 경우가 될 것이다. 따라서 글자들을 매칭해보면, 전부 출력되는 결과를 볼 수 있다. 'my'같은 경우는 \w\w가 된 결과이고, 'mine'은 \w\w\w\w 와 같은 결과이기 때문이다.

정규 표현식 이외에 raw text를 정규화하는 방식으로는 tokenizer가 있다.
NLTK는 정규 표현식을 사용해서 단어 토큰화를 수행하는 모듈을 지원한다.
nltk.tokenize에서 RegexpTokenizer를 가져온다면, input으로 받는 정규 표현식에 매칭이 되는 것들을 하나의 토큰으로 구분을 하게 된다. 즉, 토큰의 기준을 input variable로 받게 된다.
위에서 쓰인 정규표현식은 다음과 같다. [ ] (대괄호) 안에 \w는 문자 또는 숫자를 매칭하게 되고, +를 넣어줌으로써 1회 이상 반복되게 한다. 즉, 문자 또는 숫자가 한 개 이상 등장하는 것을 하나의 토큰으로 보고, 그렇지 않은 경우에는 다른 토큰으로 분류하게 된다.
위의 예문에서 보면 Don't 에서 ' 는 문자나 숫자가 아닌 특수기호로 표기하기 때문에, Don과 t가 따로 나뉘게 된다. 이것처럼 특수 문자는 다 사라지고 다른 토큰으로 구분된 것을 볼 수 있다.

이제부터는 raw text를 정제하는 normalization 작업이었다. 지금부터는 그 다음 단계인 pre-tokenization을 보도록 하자.
pre-tokenization은 tokenization 이전에 가장 큰 토큰의 형태로 나누는 것이다.
가장 basic approach는 , . ! ? 와 같은 특수 기호를 제거해주고, 여백을 가지고 나눠주는 것이다. 이때, aren't 나 don't 같은 경우에는 ' 는 특수 기호이지만, not이라는 줄임말을 가지는 단어로 중요한 의미를 지닌다. 이렇게 특수기호가 의미를 지닐 수도 있기 때문에, 단순하게 다 지워버린다면 정보를 잃어버릴 수도 있다.
한국어 같은 경우에는 '교착어'라는 것이 있다. 이는 실질 형태소인 어근에 형식 형태소인 접사를 붙여 단어를 파생시키는 것이다. 예를 들어 '간다', '가고', '가는데' 와 같은 말들은 '가' 라는 어근과 접사를 붙여 하나의 단어의 형태를 이루게 된다. 이들을 자세히 보면, 전체적으로 단어의 형태가 바뀌는 것을 볼 수 있다. '간다'에서는 '가'에 'ㄴ' 받침이 들어가면서 현재형의 의미를 지니게 되는 것과 같은 특징이 있다.
그렇기 때문에, 단순히 띄어쓰기만을 이용해서 한국어 문장이나 데이터를 나누게 된다면, 조사 혹은 어미 변환에 의해서 같은 단어임에도 불구하고 다른 토큰으로 분류될 수 있다. 문제는 이렇게 분류되면 안된다는 것이다. 따라서, 형태소를 조금 더 신경써야한다는 특징이 있다.
또한, 한국어의 경우 영어보다 띄어쓰기가 철저히 지켜지지 않는 경우가 많다. 이러한 특성들도 고려를 해야할 것이다.
한국어 데이터의 pre-tokenization 틀에 대해 살펴보자. 한국어 text preprocessing tool로는 supervised와 unsupervised 두 가지로 나눌 수 있는데, 각각 KoNLPy와 Khaiii, soynlp가 있다.
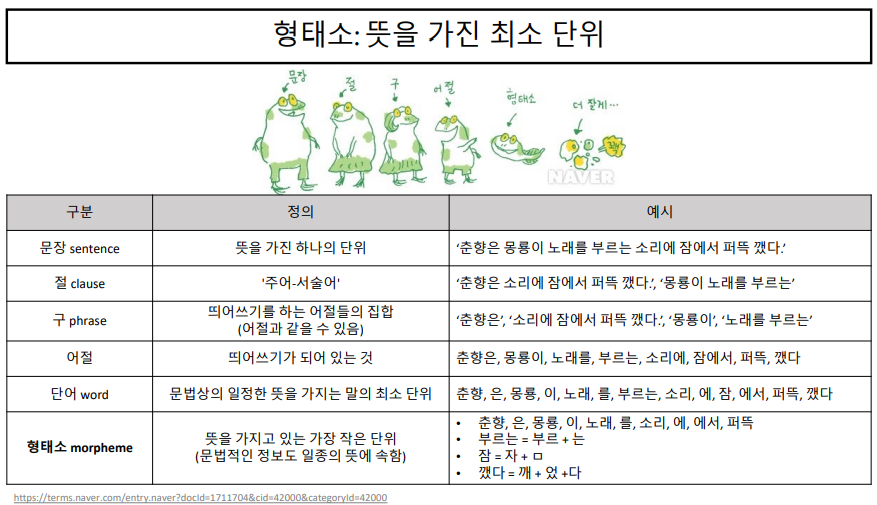
문장은 뜻을 가진 하나의 단위이다.
이 문장안에서 주어와 서술어로 이루어져있는 절이라는 것으로 나눌 수 있다.
구는 절보다 작은 단위로써, 의미를 가지고 있는 작은 단위이다.
어절은 구를 띄어쓰기를 전부 한 것이다. 이 어절을 의미를 가진 단어로 나눌 수 있다.
단어란, 문법상의 일정한 뜻을 가지는 말의 최소 단위이다. 따라서, 조사와 같은 (은, 는, 이, 가, 을, 를) 도 하나의 단어로 볼 수 있다. 이러한 단어를 형태소로 나눌 수 있다.
형태소란, 뜻을 가지고 있는 가장 작은 단위이다. 형태소보다 더 작게 쪼개는 것은 불가능하다. 춘향, 은, 이, 노래 와 같은 단어는 그대로 형태소이지만, 부르는 이라는 단어는 부르 + 는 으로 나눌 수 있게 된다. 이렇게 나눈 형태소들은 각각의 일정한 뜻을 가지고 있다. 형태소는 과거를 나타내 주거나, 서술을 해주는 등 문법적인 뜻을 가지고 있다. (문법적인 뜻을 가지고 있는 것도 의미를 지닌다고 본다.)
만약, 한국어를 띄어쓰기를 기준으로 구분하게 된다면, 같은 의미를 가진 단어도 다른 의미로 분류될 수 있다. 따라서, 한국어는 형태소 단위로 조금 더 신경써줘야 하는 부분이다. 아마 우리는 '자다', '잤고', '잠', '자는데' 라는 단어들은 모두 'sleep'이라는 같은 의미를 지닌 단어로써 단어를 그대로 사용하지 않고 형태소 단위 중 어근을 사용해서 구분해야할 것이다.

이러한 처리를 해주는 구조화된 모델은 KoNLPy가 있다. 이는 한국어 자연어처리 파이썬 패키지이다. 총 5개의 class를 지원한다. Hannanum, Kkma, Komoran, Mecab, Okt 이다. 이 5개의 class는 공통적으로 text를 형태소로 나누어주는 morphs라는 함수가 있고, nouns라는 문장의 명사를 추출하는 함수, pos라는 품사를 태깅해주는 함수가 있다.
예시로는 위와 같다.
또한, 위의 그래프는 5개의 class가 처리하는 문자의 수에 따라서 걸리는 시간을 비교한 것이다. Mecab은 글자수에 상관없이 가장 빠르게 작동함을 확인할 수 있다. 각각의 class는 형태소를 나누는 기준이 조금씩 다르다. 이는 나중에 자세히 알아보도록 하자
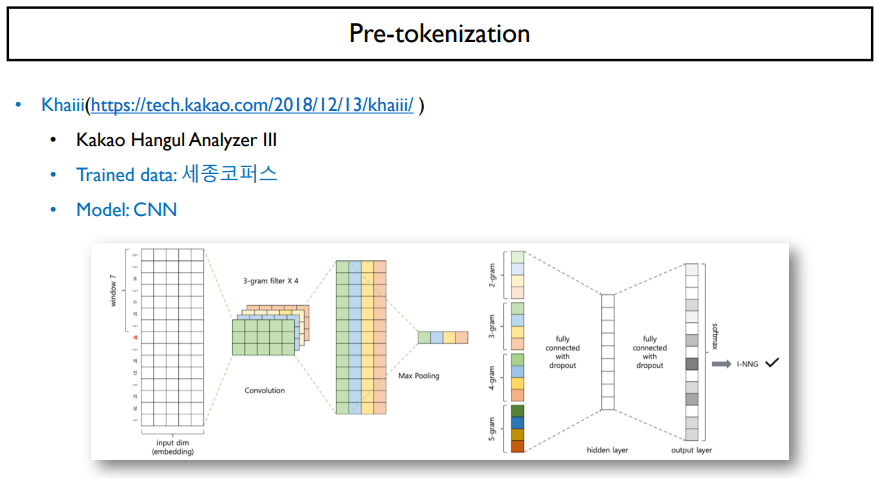
다름으로는 Khaiii라고 불리는 카카오 한글 analyzer 3는 카카오에서 발표한 세종코퍼스로 학습한 형태소 분석기이다. khaiii는 데이터를 기반으로 동작하기 때문에, 기계학습알고리즘인 딥러닝을 사용하였고, pos 태깅이나 pre-tokenization을 수행하는데 있어서, CNN 모델을 넣어 수행을 한다.
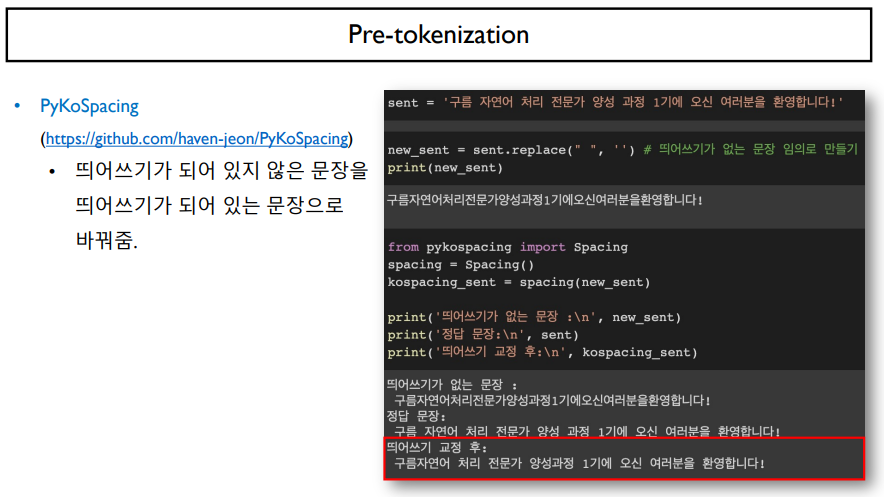
한국어 데이터는 특성상 띄어쓰기가 잘 되어 있지 않은 문장이 영어보다 많다.
하지만, 띄어쓰기는 tokenization을 하는데 아주 중요한 요소이다. 따라서, 띄어쓰기 교정을 하는 PyKoSpacing이라는 패키지가 존재하게 된다.

띄어쓰기 뿐만 아니라, 맞춤법을 교정해주는 모듈도 존재한다. Py-Hanspell이라는 패키지는 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지이다.

지금까지 살펴본 것이 지도학습 기반이라면, soynlp는 비지도학습을 기반으로 되어 있다. 주어진 데이터의 패턴속에서 띄어쓰기, tokenizing 등을 통해 패턴을 모두 학습하게 된다. soynlp에서는 어떤 단어들을 하나의 형태소로 인식을 할 때에는 단어의 통계량을 이용한다.
이 때, 단어 통계량으로 사용되는 수치는 두 가지가 있다.
Cohesion probability는 주어진 문자열이 함께 등장할 경우, 응집 확률이 높아지고, 따로 등장한다면 이 확률이 떨어지게 된다. Branching entropy는 단어 앞뒤로 다양한 다른 단어가 많은 경우에 수치가 많아지게 되고, 비슷한 단어들이 온다면 수치가 적어지게 된다.
이러한 통계량을 활용해서 어떤 단어의 score가 높으면 그 단어를 하나의 형태소로 인식하는 경우가 된다.
'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 44. Transformer (0) | 2022.06.19 |
|---|---|
| Day 43. Tokenization (0) | 2022.06.15 |
| Day 41. RNNs with Attention (0) | 2022.06.11 |
| Day 40. NLP Quiz 1 (0) | 2022.06.11 |
| Day 39. LSTM & GRU (0) | 2022.06.09 |