오늘은 모델이 자연어를 이해할 수 있도록 만들어주는 과정인 Tokenization에 대해 학습할 것이다.
Tokenization 이전의 전처리 과정은 자연어 형태에서의 noise를 줄여준다고 하면, Tokenization에서는 문자로 나타내는 단어를 컴퓨터가 이해할 수 있는 형태로 어떻게 바꿀 것인가?를 주로 배우게 된다.
Tokenization은 우리가 여태까지 학습했던 내용과는 달리 생소할 수 있지만, NLP에서 가장 중요한 분야 중 하나이다.
다양한 언어의 문자를 간결한 형태로 컴퓨터가 이해할 수 있게 하지 않으면 이후의 모든 과정에서 비효율성이 발생할 수 있기 때문이다.
Intro
Input을 ' I am a student ' 라는 문장으로 놓는다. 이러한 문장을 전처리과정을 통해 깨끗하게 만들어 준 후, 모델에 어떠한 단위(형태)로 넣어주게 될 것인지를 정해야 한다.
이렇게 tokenization이 끝나게 되면 무슨 일을 하게 되는가?

모델이 input(X1)으로 ' I am a student ' 라는 문장을 넣고, 우리는 이미 설정해 놓은 vocab이 5000개 정도 있다고 가정하자. 이는 어떤 dimension을 가지게 될 것이다. (dimension = 1024라고 가정하자) 이것을 word-based vocab이라고 부르자. 이것은 하나하나의 index가 단어단위이고, 이미 생성된 vocab이다.
여기서 내가 i번째 index를 선택했다고 하면, 1 by 1024 라는 vector는 i번째 단어(ex. student) 의 의미를 담고 있는 word embedding vector일 것이다.
그렇다면, input 문장 하나가 들어왔을 때, 단어 단위로 문장을 끊어주고, 각각의 단어가 word-based vocab에서 몇 번째에 위치하는지 알 수 있을 것이다. 이는, word를 index로 바꾸는 과정이 된다.
예를 들어, I는 80번째, am은 10번째, a는 50번째, student는 100번째 index에 존재한다고 하자. 우리가 student를 전체 5000 by 1024라는 dimension (vocab)에서 뽑아내려면, 어떻게 해야할까?
바로, word-based vocab에서 100번째 index에만 1을 넣어주고, 나머지에는 0을 넣어준다. 이러한 과정을 Look up 이라고 한다. 이는 여러가지 정보가 같이 존재할 때, 내가 원하는 정보(vector)만 가져오게 되는 것을 말한다.
가져온 index를 가지고 우리는 word embedding을 할 수 있게 된다.
이렇게, 처음 input 문장에서의 단어들은 각각 대응되는 1 by 1024라는 dimension의 word vector를 갖고 있게 된다. 이것이 모델의 input으로 들어가게 된다.
pre-tokenization과 tokenization은 input에 대해서 어떻게 전처리를 하고, input을 어떻게 설정하느냐에 대한 방법론이 될 것이다.

이제, NLP의 전체적인 pipeline을 살펴보자.
예를 들어서, 문서 분류 하는 api를 만든다고 가정하자. 이것은 input text가 들어왔을 때, 이것이 문어체(0)인지 구어체(1)인지 classification해준다. 이 때, 문서분류라는 task를 수행하기 위해서 다양한 방법을 시도해 볼 수 있을 것이다.
첫 번째로, 데이터를 수집해야 한다. 데이터 수집을 한다는 것은, 딥러닝 모델을 학습시키기 위한 training dataset을 구축하는 것이다. training dataset은 text와 그것에 대한 label로 이루어질 것이다. text는 크롤링을 통해 수집할 수 있지만, label은 직접 만들어야 할 것이다.
예를 들어, 신문, 방송에서 가져온 글을 모두 문어체로 포함시키고, 블로그나 sns에서 가져온 글들은 구어체로 포함하는 class를 정의했다고 가정하자.(label해줌) 총 데이터는 1만개라고 해보자.
두 번째로, preprocessing을 거치게 될 것이다. 모델의 input 직전까지 거치는 일련의 과정을 말한다. 이것은 학습용 데이터를 구축하는데 사용이 될 것이다.
예를 들면, 문어체라는 class에 일괄적으로 신문이 source인 text를 모아놨는데, 여기에는 인터뷰가 포함되어 있다. 하지만, 인터뷰 내용은 문어체에 해당하지 않으므로 제외하거나 구어체라는 class로 바꾸어 주어야 할 것이다. 이렇게 바꾸어주는 것도 pro-tokenization의 일부이다. 블로그나 sns에 욕설이 너무 많아 이를 제거해주는 것, 맞춤법 교정 등도 포함된다. 우리는 이것을 노이즈를 제거했다고 표현한다.
이렇게 전처리 과정을 거친 후, 모델링 과정으로 들어서게 된다. 모델링이라는 것은 내가 어떠한 아키텍처 구조를 쓸 것인지를 결정하는 것이다. 예를 들면, RNN, LSTM, GRU 중 무엇을 사용할 것인지 고르는 것과 같다. 그 후, 코드를 구현해야 할 것이고, 여기서 training과 inference(test) step의 셋팅을 해주는 것이 중요하다.
training은 self supervised learning, unsupervised learning이라고 하더라도, label이 있어야 loss를 흘리고 모델을 학습할 수 있다. 즉, 모델이 얻는 값은 loss인데, 이 loss는 정답 값과 예측 값의 차이를 구분함으로써 생기는 것이기 떄문에 정답 값(GT)이 반드시 필요하다. 예를 들어, word embedding 같은 경우에도, 'I like to play'라는 문장에서 like가 input이면, output으로는 I, to, play가 나와야 할 것이다. 이들은 각각 y1, y2, y3 으로써 정답 값이 될 것이다.
그러므로, 학습을 할 때에는 정답 값(ground-truth label)과 예측 값(prediction label)의 차이로 loss를 얻게 되고, 이것으로 모델이 back propogation과 learning rate를 update하면서 학습을 하게 될 것이다. 학습을 한 후에는 모델이 unsigned dataset에 대해서 어떠한 성능을 내는지 보아야 할 것이다. 이 때, test 는 loss를 흘릴 필요가 없기 때문에, predicted label을 얼마나 잘 나왔는지 평가하기만 하면 된다.
이런식으로 training과 test를 모두 고려하여 코드를 짜게 되면, 앞의 data collection, preprocessing을 통해서 data가 processing이 되었고, modeling 과정을 통해서 model이 준비되었다. 이들을 가지고 training을 진행해야 한다.
training을 할 때, training monitoring을 진행하게 된다. 우리가 GPU가 없다면, AWS의 GPU 대여 서비스, GCP 등의 서비스를 이용하게 될 것이다. 이것들은 한 시간에 약 4달러 정도로 매우 비싸기 때문에, model을 효율적으로 학습시켜야 할 것이다. 이것은 data, AI engineer로써 유의해야 할 점이다. Monitoring은 overfitting이나 bias 등의 상황을 체크하는 것이다. 그 뒤로 여러가지 분석을 진행하게 된다. ( ex. 모델의 결과 값으로 어떠한 평가 지표를 사용해야하는지 실험하고, 정한다.) 또한, 모델의 hyperparameter를 세부적으로 조정하면서 학습하게 된다.
학습을 마친 후, 학습이 잘 되었는지 판단하기 위해서 acc, f1 score, precision, recall 등을 사용할 수 있다.
이렇게 생성된 model이 실제 사용되는데 맞게 수정이 되어야 할 것이다.
하지만, 아무리 성능이 좋더라도 완벽할 수는 없을 것이다. 그렇기 때문에, 이것이 실제 서비스화 된 후에도 계속해서 monitoring하는 단계가 필요할 것이다.

Tokenization을 한 결과는 결국, model의 input이 되는 것이다.
Tokenization이 생각하는 방법에 따라서, model이 text sequence를 이해하는 단위가 달라지게 될 것이다.
예를 들어, ' It's sunny today Let's go out ! ' 이라는 문장이 있을 때, ① It's / sunny / today / Let's / go / out ! 이러한 상태로 tokenize할 수도 있지만, ② It / ' / s / sunny / today / Let / ' / s / go / out / ! 이렇게 조금 더 구체적인 형태로도 tokenize할 수도 있을 것이다. 또한, 여기서 더 세분화하여 ③ It / ' / s / sun / ny / to / day / Let / ' / s / go / out / ! 이러한 형태로도 tokenize가 가능할 것이다. ① 일 때 model이 고려하는 길이는 6이지만, ② 일 때의 길이는 11이 된다. 이렇게 되면, model이 input으로 받는 길이와 문장이 갖고 있는 특징도 달라지는 것을 볼 수 있다.

우리가 Tokenizer를 사용할 때는 일반적으로 세 가지를 사용한다.
Word based Tokenizer는 기본적으로 단어를 보는 것이고, Character based Tokenizer는 기본적으로 글자를 보는 것이고, Subword based Tokenizer는 단어보다 조금 더 작은 단위인 ( ex. 형태소 )를 보는 것이다.
여기서 주로 사용하는 것은 Subword based Tokenizer이다.
위의 예시를 보자. input text는 '나와 쇼핑하자.' 이다. 이를 character 단위로 바꾸게 된다면, 모음과 자음 단위로 나누게 되고(space는 *로 표시하였다), syllable은 음절 단위로 나눈 것이고, Morpheme(형태소) 단위로 나누게 되면 '쇼핑'이 하나로 묶이게 된 것을 볼 수 있고, subword은 나뉜 것을 보면, _가 있는 것이 있는데, 이것은 시작점을 의미한다. 그외 등등 나눠진 것을 볼 수 있다. 이렇게 다양한 token에 따라서 각각 model의 input으로 들어갔을 때, 경우가 다른 것을 알 수 있다.
Word-based Tokenizer는 단어 단위로 쪼개주는 것을 의미한다. 그 예시는 위와 같다.
. (온점)도 단어로 구분되기 때문에, 따로 사용해주는 것을 유의하자.
영어의 경우에는 대부분 띄어쓰기로 단어가 구분되지만, 한국어의 경우에는 그렇지 않기 때문에 조금 더 어려운 경향이 있다.

Character-based Tokenizer는 글자 단위로 쪼개는 것을 의미한다.
영어의 경우에는 한 글자로 나뉘어지지만, 한국어는 보통 음절을 기준으로 나눈다. (초성 - 중성 - 종성)

Subword-based-Tokenizer는 빈도수가 높거나, 의미가 있는 것을 기준으로 나누어주는 것이다. word-baed와 동일할 수도 있지만, 이보다 더 자세히 나눌 수도 있다.
위의 예시를 보면, 'This', 'is', '.' 은 word level과 동일하다. 하지만, 'tokenizing'을 'token'과 'izing'으로 나눈 것을 볼 수 있다.

위의 예시를 살펴보자. 한국어로는 띄어쓰기나, 조사를 통해 나누어야 할 것이고, 영어로는 대소문자를 구분해야할 것이다.
이러한 pre-tokenization은 왜 필요할까?
model의 성능을 높이기 위해서이다. 전처리를 잘 할수록 model이 특징을 더 잘 잡아내고, 이후의 결과가 잘 나오게 될 것이다.

우리는 Word, Character, Subword 중 Subword를 주로 사용한다.
Word 같은 경우에는 대표적으로 out-ot-vocabulary 문제가 있다. 이는 단어 사전에 없는 것이 들어올 때 생기는 문제를 뜻하며, 신조어가 들어오면 잘 처리가 안되는 문제가 이러할 때 생긴다. word level에서는 vocab에 많은 단어를 넣으면 메모리에 문제가 생기고, vocab에 단어가 적으면 성능에 문제가 생긴다.
Character의 경우에는 다음과 같다. 알파벳은 총 26개이다. 그러면 vocab은 50 x 1024 가 될 것이다. 이 경우에는 word보다는 vocab이 가벼워지지만, 성능이 전혀 나지 않는다는 문제점이 발생한다. 같은 문장이 주어지더라도 word보다 character level에서 훨씬 길게 input이 들어가기 때문에, 처리하는 시간도 길게 들 것이다. 이렇게 sequence length가 점점 길어지면 성능이 떨어진다는 문제점이 있다. 이 문제는 가설일 뿐이지만, 많은 논문들에서 나타낸 결과이므로 설득력 있는 가설이라고 볼 수 있을 것이다.
또 다른 문제점은 한 글자가 하는 정보를 잡아내는데 생긴다. 예를 들어, 'e' 라는 글자는 'the', 'visited', 'write' 등의 단어에서 나타난다. 그렇다면 'e'에는 각각의 단어에서 쓰이는 온갖 의미가 다 들어가야 할 것이다. 그렇게 되면, word embedding이 길어지더라도 성능이 잘 나오지 않게 된다.
그렇게 해서 나온 것이 subword이다. 이는 기본적으로 character보다는 short sequence가 될 것이고, character보다는 훨씬 더 좋은 성능을 보여줄 것이고, out of vocabulary의 문제에서 자유로워질 수 있을 것이다. (ex. 줄임말에 대한 신조어 해결 가능)

Subword-based Algorithms에는 여러 가지가 있다.
Byte-pair Encoding(BPE)은 GPT에서 사용하고 있는 방법론이다.
이외에도 나머지 algorithm들은 비슷한 방식을 가지고 있다.

위 코드는 BPE 논문에 있는 알고리즘이다. 이 알고리즘은 상당히 간단한 편으로, python으로 구현되어 있다.
자세히 살펴보면, get_stats와 merge_vocab이라는 두 가지로 형상으로 이루어져 있다. 그 밑이 코드를 실행시키는 부분인데, vocab은 dictionary 형태로써, 단어 단위로 나뉘어져 있다. 이것을 num_merge를 사용해서 for문을 돌려보자. pair에서는 vocab이 어떤 단어와 그 단어가 등장한 횟수임을 알 수 있으며, 단어를 글자 단위로 쪼개서 글자쌍의 빈도 수를 순서를 고려하여 pair로 반환하고 있다. ( ex. [l, o] += 5, [o, w] += 2) 이런식으로 글자쌍에 대한 frequency를 갖게 된다. pairs에서 빈도수가 높은 것들부터 합쳐주도록 하자. 대략 [l, o], [e, s]가 있고, 순서대로 빈도수가 높다고 할 때, 하나씩 합치면 이는 새로운 단어가 되고, 이 단어는 vocab에 추가될 것이다. 이렇게 계속해서 update하게 되는 식으로 vocab을 새로 만들게 된다.

이렇게 합친 것을 한 글자 단위에서 새로운 vocab으로 만들어주는 것이 BPE이다.
BPE란, Byte는 글자라는 뜻으로, 앞에서와 같은 글자쌍을 A라고 할 때, 이 글자쌍은 A라는 의미를 가지는 것으로 encoding을 한다는 의미이다.
Byte-Pairn Encoding을 NLP에 tokenization method로 사용하게 되면서, BPE tokenization이 된 것이다.
즉, BPE는 가장 자주 등장하는 단어 혹은 글자쌍을 하나의 token으로 처리하고, 가끔 등장하는 것들은 subword token(한 글자)으로 처리하는 것이다. 이렇게 frequency를 기반으로 하기 때문에, 통계적인 방법이라고 할 수 있다.
그러나, BPE의 문제점은 빈도수로 구분하기 때문에, 의미로 구분하는 것보다 성능이 떨어질 수 있다. 이렇게 frequency를 기준으로 하는 방법의 한계는 '빈도수가 높은 것은 많이 사용할 것이므로 추론하는데 용이할 것이다'라는 가설에 의존한다는 사실이다. 예를 들어, '보는중', '가는중', '오는중' 이라는 단어들이 있을 때, 의미가 있는 것은 '보', '가', '오'이다. 하지만, BPE를 사용한다면, '는중'이 하나의 pair가 될 것이다. 하지만 이렇게 구분하는 것도 실질적으로 의미가 있는 것들끼리 구분하는 것이 되기 때문에 어느정도는 맞는 사실이지만, 미심쩍다. 이러한 부분을 해결해주기 위해 Morpheme-aware Subword가 등장하게 되었다.

BPE의 예시로써, aaabdaaabac라는 단어가 있다고 가정하자. 이를 글자쌍으로 나누면, aa, aa, ab, bd, da, aa, aa, ab, ba, ac로 나눌 수 있다. 여기서 aa는 총 4번으로 가장 많은 횟수로 등장한다. 이 aa를 Z로 바꿔주도록 하자. 그렇게 되면, 이 단어는 ZabdZabac가 될 것이다. 여기서는 ab가 가장 많이 등장하고, 이를 Y라고 한다면, 단어는 ZYdZYac가 될 것이고, 여기서는 ZY가 가장 많이 등장하므로 이를 X라고 할 것이다. 결국, 단어는 XdXac가 될 것이고, X는 이미 정의된 상태이다. 여기서는 더이상 압축할 수 없게 된다.
이러한 순서로 encoding을 진행하게 되고, decoding은 반대로 진행해주면 원래의 단어를 복구할 수 있게 된다.
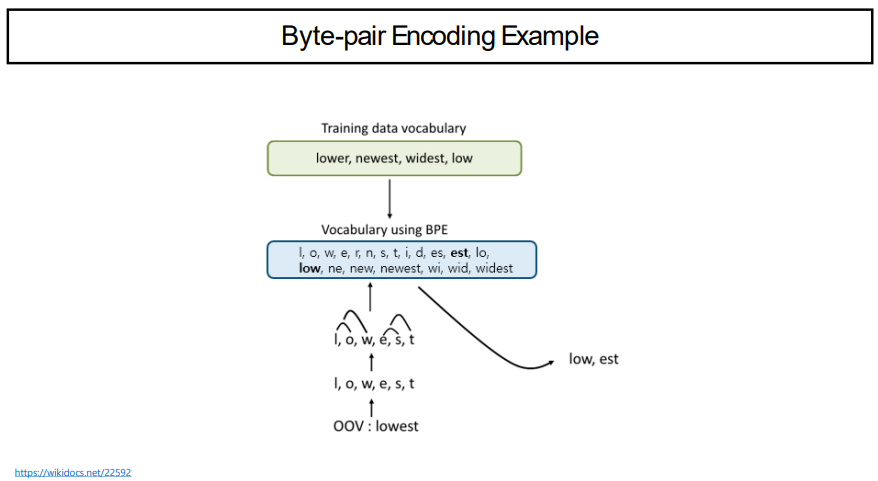
위 그림은 앞에서의 BPE를 더욱 간단하게 나타낸 예시이다.

BPE는 여러가지 issue를 가지고 있다.
Token after space는 _로 표현되었던, space바 다음으로 표현된 token에 대한 issue이다. 예를 들면, 위의 예시 문장에서 'one', 'of', 'resource'안에는 'o'가 공통적으로 들어가 있다. 이 'o' 들을 동일하게 보는지, 구분해야하는지의 문제이다. 보통 sentence level에서는 구분하는 것이 옳다고 생각한다. 구분하는 방법으로는 _로 해주는 것이다. 그렇게 되면 이 단어들은 '_one', '_of' 등이 될 수 있다.
다음으로는 Substring match problem이다. 예를 들어 '학교에'라는 단어가 현재 갖고 있는 vocab에 없다면, 다음과 같이 처리를 할 수 있다. 왼쪽에서 오른쪽으로 하는 처리와, 오른쪽에서 왼쪽으로 하는 처리가 있을 것이다. 예를 들어, 오른쪽에서 왼쪽으로 들어가게 된다면 '교에'라는 글자쌍이 많이 등장하므로 [학,교에] 로 나눌 수 있을 것이고, 왼쪽에서 오른쪽으로 들어가게 되면 '학교'라는 글자쌍이 많이 등장하므로 [학교, 에]로 나눌 수 있을 것이다. 일반적으로는 왼쪽에서 오른쪽으로 들어가는 메소드를 사용하곤 한다.
'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 45. NLP Quiz2 (0) | 2022.06.20 |
|---|---|
| Day 44. Transformer (0) | 2022.06.19 |
| Day 42. Preprocessing (0) | 2022.06.14 |
| Day 41. RNNs with Attention (0) | 2022.06.11 |
| Day 40. NLP Quiz 1 (0) | 2022.06.11 |