오늘은 현재 자연어처리, 비전 분야를 막론하고 가장 많이 사용되고 있는 transformer에 대해서 다시 한번 복습합니다.
'Attention is all you need'로 transformer가 소개된 이후 아주 많은 변형과 대체재들이 등장했지만, transformer block은 여전히 가장 널리 사용되고 있는 deep learning block 중 하나입니다.
현재 아주 많은 연구와 실무에서 사용되고 있는 알고리즘들이 이 transformer architecture를 기반으로 하고 있기 때문에 input부터 output까지 어떤 연산을 거치고, 각 연산에는 어떤 의미가 있는지 알아두는 것이 여러모로 좋을 것이라 생각됩니다.
Transformer : Intro

Transformer 모델이 처음 제안된 논문의 이름은 'Attention is all you need'이다.
이는 기존의 RNN 기반의 sequence encoding하는 모델 구조를 attention 기반의 모델로 완전히 대체를 한 형태이다.

'기존의 RNN이나 CNN 아키텍처를 attention 만으로 대체를 할 수 있었다' 라는 핵심 아이디어가 어떻게 구현이 되는지 살펴보자.

RNN의 Long-term dependency & gradient vanishing 의 예제를 살펴보았듯이, 정보의 흐름을 살펴보면, 정보가 왼쪽에서 오른쪽으로 가는 흐름을 가지고, 각각의 단어들은 word embedding vector로써 3차원 벡터로 이루어져 있다.
sequence를 encoding하는 과정에서는, RNN이라는 항상 같은 역할을 하는 공통의 모듈을 계속해서 통과해가면서, 'I'라는 정보가 'home'이라는 단어까지 정보 전달이 된다. 그렇게 되면, 'home'이라는 단어를 encoding한 hidden state vector에 'I'라는 정보가 담긴다. 어떤 단어의 hidden state vector가 어디까지의 정보를 encoding 하였는가를 연결관계로 나타낸 것은 다음과 같다.

오른쪽 위의 time step에서의 hidden state vector는 그 time step에 들어온 입력과 그 이전까지의 모든 입력에 대한 정보를 모두 저장한다. 그 과정은 RNN을 통과한 길을 통해서 정보가 전달이 된다.
RNN이라는 동일한 layer를 time step의 차이만큼 거쳐서 정보가 전달이 되는 경우에는 정보가 같은 모듈을 계속해서 통과하게 되면서, 정보의 변질이나 유실이 발생할 수 있다.

어떻게 하면, 다른 방식으로 현재 time step에서 단어를 encoding 할 때, 이전의 정보들을 직접적이고, 많은 단계를 거치지 않고 한번에 정보를 전달해 줄 수 있는지를 해결하기 위해서 attention model을 사용할 수 있게 된다.
attention 기반의 model에서는 왼쪽, 오른쪽에서 오는 단어들 모두 커버할 수 있게 된다. 이는 모두가 모두에게 dependency를 가지는 형태(모두 연결된 형태)로, 필요한만큼의 정보들을 encoding 할 수 있게 된다.
그 과정 중에 첫 번째 단어인 'I'에 대한 hidden state vector를 뽑기 위해서, 수행해야하는 연산 과정을 attention 관점으로 처리하는 예시를 살펴보자.
기본적으로 'I'를 encoding 할 때, 'I' 벡터(x1)가 q1(쿼리벡터)이라는 벡터로 변환이 된다. 이 때, linear transformation을 한 번 거치게 된다.

다시 말하자면, x1라는 벡터를 row vector로 나타내고, 여기에 linear transformation을 거쳐서 어떤 특정한 dimension vector로 변환하는 것이다. 이 벡터는 attention model에서 취사 선택을 하는 기준이 되는 정보를 제공하는 vector이다. (가령, decoder의 hidden state vector를 가지고 encoder의 벡터 하나하나와의 유사도를 계산한다. 이 decoder의 hidden state vector는 encoder의 어떤 벡터가 우리가 필요로 하는 정보인지를 정하는 기준이 되는 벡터이다.) 이 벡터를 '쿼리 벡터'라고 부른다.
결국, 어떠한 word를 query형태로 변환을 시켜주는 linear transformation을 거쳐서 쿼리 역할을 하도록 만들어주는 것이다. 이 벡터는 decoder의 hidden state vector로써 사용되는 것이다. 이 벡터(q1)를 가지고 encoder에서 word들 별로 존재하는 hidden state vector들의 유사도를 계산할 것이다.
결국 이 query vector(q1)가 주어진 하나의 sequence를 서로가 서로의 정보를 필요한 만큼 취사선택해서 encoding vector를 만들어낼 수 있게끔 해주는 용도로 활용을 한다. 이러한 용도로 활용하기 위해서, 취사선택을 해야하는 candidate vector set들은 자기자신을 포함한 vector들이 된다.(여기서는 'I', 'go', 'home' 이 candidate vector set이다.)
그래서, 우리는 이것을 self-attention이라고 부른다.
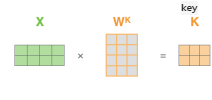
우리는 candidate vector들로 변환해주는 또다른 linear transformation 하나를 더 두게 된다. 이는 Wk이다.
이는, input vector들을 취사선택을 할 때 유사도가 계산이 되는 candidate vector들로 변환해주게 된다. 그렇게 되면, input vector 하나하나가 Wk라는 linear transformation matrix를 가지고 또 다른 vector set으로 변환된다. 이는 각각 k1, k2, k3 이다.
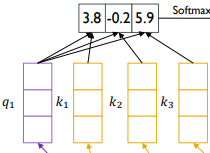
그 다음, 이렇게 구한 k1, k2, k3 vector들을 대상으로, 앞에서 구한 query vector를 내적하여 유사도 값을 구하게 된다. 유사도 값이 3.8, -0.2, 5.9라고 한다면, 이것을 softmax를 걸게되어 확률 값을 구할 수 있게 된다. 이렇게 구한 확률 값들은 정보를 몇 % 가져갈지를 나타내는 상대적인 확률 값이 된다.
구해진 유사도를 가지고, 정보를 가져가고자 하는 vector들에 가중치를 걸고, 가중합을 내어서 정보를 가져와 쓰게 된다.
그 후, 유사도를 구하는데 사용된 candidate vector들에 할당되는 가중치로 사용해서 이 벡터들의 선형결합을 통해 최종 정보를 가져갈 수 있었다. encoder의 hidden state vector는 두 가지 역할을 한다. 하나는, 유사도를 구해서 softmax의 최종 확률 값을 내어주는 용도로 사용하고, 다른 하나는 앞에서 구한 확률 값이 가중치로 부여되어서 이 encoder의 hidden state vector와 결합된 가중합에 해당하는 vector를 뽑는데 사용되는 재료 벡터로 사용되었다.
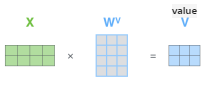
그리고 난 후, x1, x2, x3라는 vector set들을 가중치가 부여되는 재료 벡터들로 변환되게 하는 linear transformation이 Wv이다. vector set들을 동일한 Wv를 통해서 변환시킨 재료 벡터들(v1, v2, v3)에다가 앞에서 sofrmax를 통해 구한 가중치를 걸어주게 되어서 최종적인 가중합에 해당하는 결과 벡터를 낼 수 있게 된다.
우리는 이 결과 벡터를 최종적으로, 첫 번째 단어인 'I' 를 encoding한 hidden state vector로 사용하게 된다.
이러한 과정을 반복한다. 'go'라는 단어를 encoding하기 위해서도 wq라는 linear trasnform을 통해 query vector를 만들어주고, 이 query vector들을 각각의 key vector들에 내적하고 softmax를 취해 확률값을 구하게 되면, 이 확률 값과 Wv vector들을 내적하여 hidden state vector로 만들어주게 되는 것이다.
결국, 'I'라는 단어를 encoding하기 위해서는 input으로 들어온 세 개의 단어를 모두 사용하였고, 'go', 'home'도 마찬가지로 모두 사용하였다. 이는, 만약 'home'이라는 단어의 encoding vector는 time step이 아무리 멀리 떨어져있더라도, 유사도만 큰 값으로 계산된다면, 바로 그 정보를 가져올 수 있게 된다. (정보 변질 x) 이는 정보가 변질될 수 있는 한계점을 개선시킨 모델이다.
기본적으로 attention을 통해서 주어진 sequence를 encoding하는 방식은, RNN기반의 sequence 모델보다 훨씬 좋은 성능을 보이고 있다. 이는 최근까지 자연어처리의 기본 핵심 모델이 되었다.
RNN과 attention의 또 다른 차이점은, 가장 최초로 나타난 단어를 encoding 할 때, RNN의 경우는 단방향이므로 오른쪽에 있는 단어들을 볼 수 없었고, attention은 방향 구분없이 전체를 볼 수 있다. 그러나, RNN도 forward-RNN과 backward-RNN을 동시에 concat하여 쓴다면, 해당 단어에 대한 encoding vector로 사용하게 된다. 우리는 이것을 bi-directional RNN이라고 부른다. 이러한 방식은 기존의 단방향 RNN의 단점을 보완한 것이다. bi-directional RNN은 attention과 공통점이 있지만, attention은 유사도만 큰 값으로 계산된다면 해당 정보만 가져올 수 있지만, bi-directional RNN은 많은 단계의 RNN을 거쳐야한다는 단점이 있게 된다.
Transformer : Scaled Dot-product Attention

transformer를 수학적으로 정의하면 다음과 같다.
각 단어에 해당하는 query vector들이 존재하지만, 한 번의 attention 과정에는 query vector가 하나로 고정되어있다. 그리고, 앞의 그림에서 보았던 key라는 vector set(k1, k2, k3)과 value라는 vector set(v1, v2, v3) 들이 있었다. 여기서 k1 vector는 v1 vector의 가중치를 결정하는데 사용되고, 나머지도 이와 같다. 이러한 관계를 가지고, key-value는 항상 pair의 관계를 가지고 있고, 그 갯수는 동일하다.
Wq, Wk, Wv로 선형변환을 해서 만들어진 실제의 query vector, key vector, value vector들에 대해서 다음과 같은 수식을 얻을 수 있다.
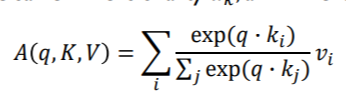
이 수식은 앞서 말한 과정이다. 이 결과는 한 query vector에 대한 encoding vector가 된다.
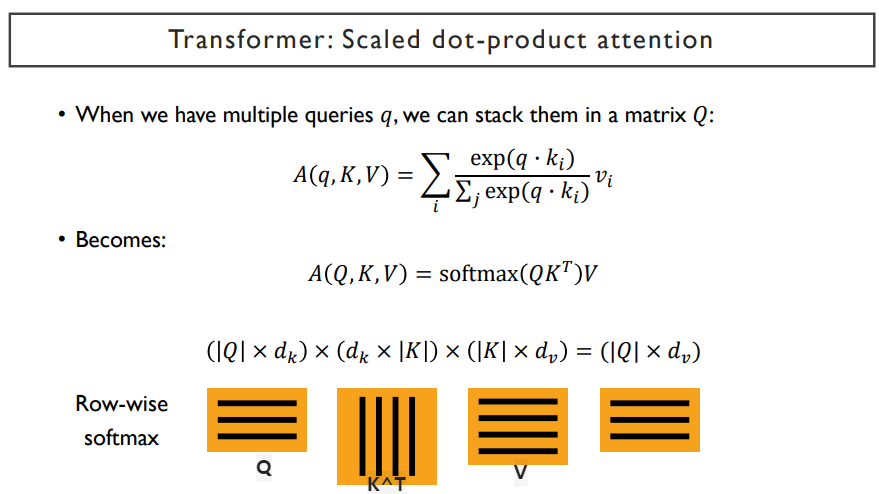
attention 가중치를 걸어서 만들어지는 encoding된 vector는 qurey하나에 대한 encoding vector이다. 우리는 많은 query vector들이 있기 때문에, 각 word들의 encoding vector를 구해야 한다. 이 전체 과정을 표현한 식은 다음과 같다.
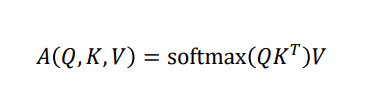
Q라는 matrix는 'I', 'go', 'home'에 해당하는, query vector이다. K^T에서 K는 구해진 key vector들을 row vector들로 구성된 행렬이다. 이를 column vector들로 만들어주기 위해 K^T라고 표현한다.
여기서 query vector는 세 개 인데, key vector들은 네 개가 주어진다. query는 query대로 따로 존재하고, key와 value는 그것들대로 따로 존재할 수 있다. 이 둘은 서로 다른 vector set가 제공될 수 있다는 전제하에 갯수가 다를 수도 있다. 예를 들면, 'I', 'go', 'to', 'the', 'school' 은 key와 value가 각각 5개씩 있을 것이다. 그러나 이것을 번역할 때, 출력은 '나는', '학교에', '간다' 로써, query vector는 결국 3개 밖에 없게 된다. 하지만 self-attention에서는 query와 key-value vecor set이 같은 vector set에서 출발하게 된다. 여기서는 예시처럼 조금 더 일반화된 상황을 고려한 점에서 갯수를 다르게 한 것이다.
Q와 K^T를 내적을 취하게 되면, 하나의 matrix가 생성될 것이다. 이 생성된 matrix에서 첫 번째 row는 첫 번째 query에서 주어진 key vector들의 similiarity 값들을 내적을 통해 구한 것이 된다. 이 matrix에 softmax를 걸어야 한다. softmax는 matrix의 각각의 row에 대해 normalize를 해준다.
V라는 행렬은 value vector들을 row vector로 저장하고 있는 행렬이다. 여기서는 key vector가 4개의 column이니, value vector도 4개의 row로 구성되어있을 것이다. (pair를 이루고 있기 때문) 앞에서 구한 matrix와 V를 곱해주면, output matrix가 생성되게 되고, 이 matrix는 (query 수) x (V의 dimension) 의 형태를 가진다.
이렇게 간단한 행렬식으로 바꿀 수 있게 된다. 행렬 곱을 병렬적으로 수행하는데 최적화된 GPU가 잘 수행할 수 있게 된다.
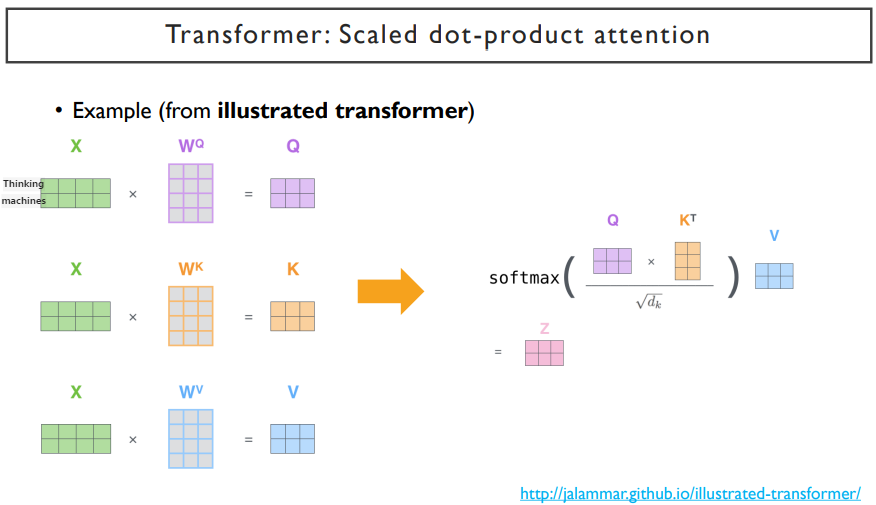
우리가 Q와 K^T의 내적을 한 것에서 softmax를 취하기 전에, √d 를 나누어 준다. 이것을 scaled dot-product라고 부른다.
scaled dot-product는
위 그림은 'Thinking' ,'machines'라는 두 개의 단어로 이루어진 sequence를 encoding 할 때의 예시를 들고 있다.
위에서 설명한 과정을 거치고 수식을 통해 알기 쉽게 설명한 것이다. 여기서 √dk 를 나누어 준다. dk는 Q나 K에 해당하는 차원을 말한다. 위 예제에서는 3차원이 dk가 될 것이다.
왜 √dk를 나누어주는가? 위 그림에서 dk는 query vector와 key vector들의 dimension으로, 이는 3차원이다. 그렇기 때문에 각각의 값에 √3 을 나누어주게 된다. 이 값들이 작아지게 되면(0에 가까운 값이 된다.), softmax를 취했을 때 나오는 결과는 확률값 간의 대소관계는 유지되지만, 그 차이들이 적어지게 된다.([0.2 0.1 0.7] -> [0.3 0.15 0.55]) 하지만, √3 을 나누어주지 않는다면, softmax를 취하기 전의 값들의 차이가 커질 것이다. 차이가 커지게되면, softmax를 취하고 나서의 확률 값의 차이가 매우 커지게 된다.(ex. [ 0.02 0.01 99.97] ) attention 연산에서는 정보를 적절한 비율로 배합해서 encoding을 해야하는데, 기하급수적으로 증가하는 과정(√3을 나누어주지 않아서 생김)때문에 정보를 조합하지 않고, 하나만 선택할 수 밖에 없는 상황이 오게 된다.
그렇다면, 언제 이렇게 값이 크게 나타나는가? dimension이 굉장히 큰 두 벡터를 내적하게 되면 dk가 커지게 된다.
그렇기 때문에, √dk로 나누어주어서 dimension이 커지더라도 scale이 일정한 값으로 유지될 수 있도록 한다. 따라서, 이렇게 √dk로 나누어 주는 것을 scaled dot-product라고 한다.
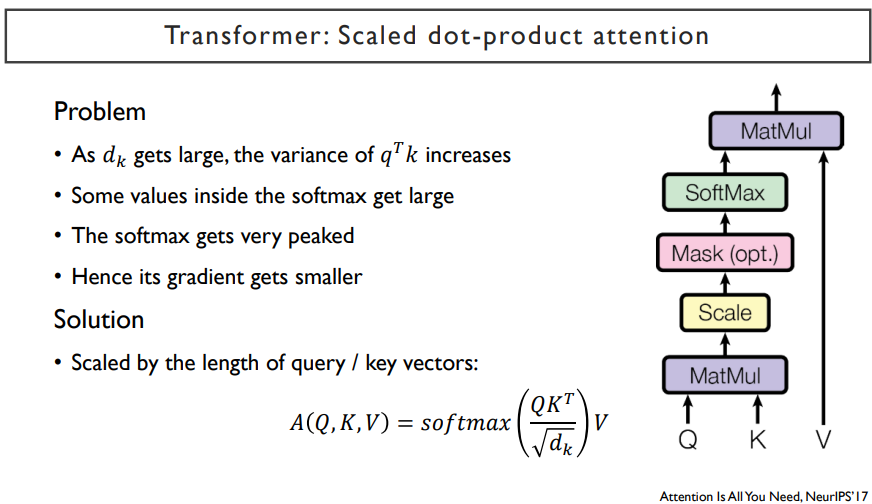
scaled dop-product에 기반한 attention이 위 식으로 최종적으로 나타난다.
key-value 개념은 해시테이블이라는 개념으로 표현할 수 있다. key값은 categorical value이고, value값은 categorical value가 될 수도 있지만, 숫자로 나타내어질 수도 있다. 이렇게 table에서 원하는 key의 value값을 꺼내오는 과정은 attention이라는 과정과 비슷하다. key에는 query vector가 들어가게되고, value에는 가중치가 들어가게 된다고 생각하자.
즉, 이렇게 table look up을 벡터화 한 것이 attention이라고 할 수 있다.
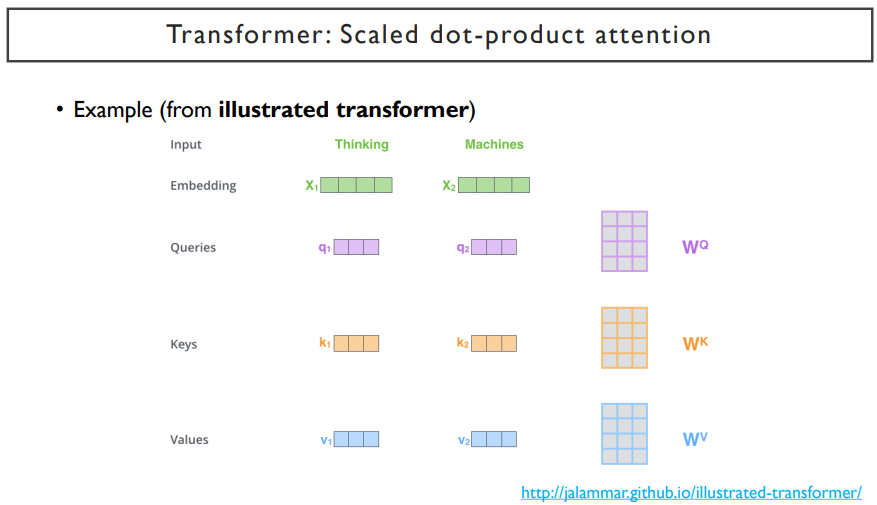
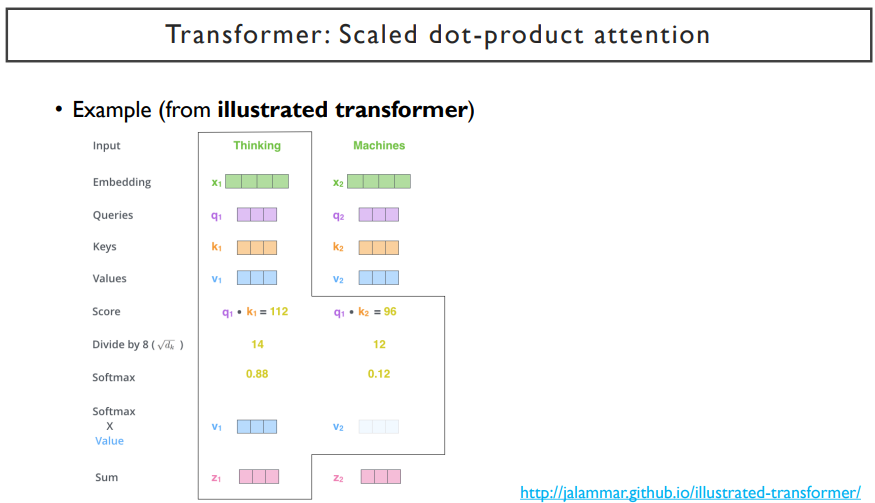
illustrated transformer라는 사이트에서 예제를 상세하게 나타내어주고 있다.
Transformer : Multi-head Attention
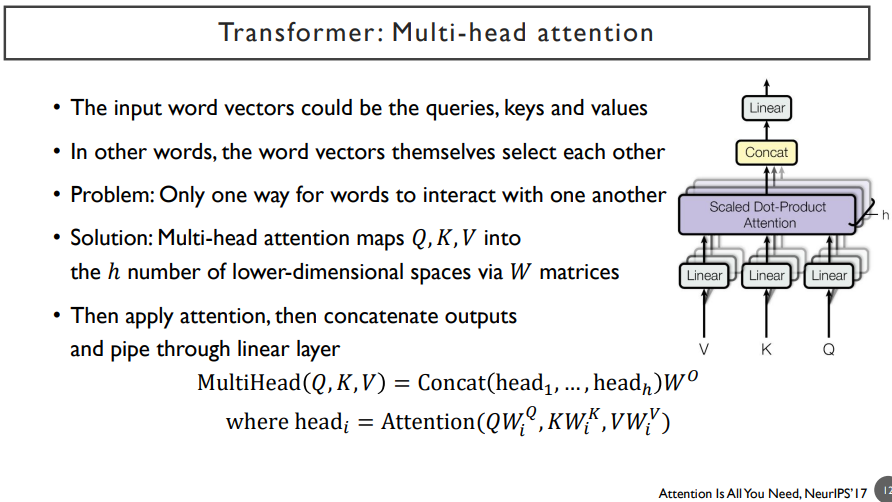
attention을 확장한 것 중에 하나는 multi-head attention이다.
위 그림에서, linear transform해주고 scaled dot-product attention해주는 과정을 attention 모듈이라고 하자. V, K, Q는 query, key, value 자격으로 들어가는 vector set들을 입력으로 받는 것이다. attention에서는 query, key-value가 필요하지만, self-attention(자기자신을 sequence encoding)에서는 query, key-value가 아닌, 하나의 vector set이 들어가게 된다. 각각의 linear는 Wk, Wv, Wq가 된다. 이들은 각각의 다른 행렬 세트들일 것이다.
다양한 각도에서 정보를 추출하고, 이것에 기반해서 attention을 수행하는 여러 개의 병렬적인 branch들이 multi-head라는 뜻으로써, 이렇게 가중합으로 나타나는 vector들은 추출된 정보들을 concat하는 것이다.
위 식에서 concat은 합친다는 의미이고, head들은 첫 번째, 두 번째, ... set의 query, key, value transformation이 된다.
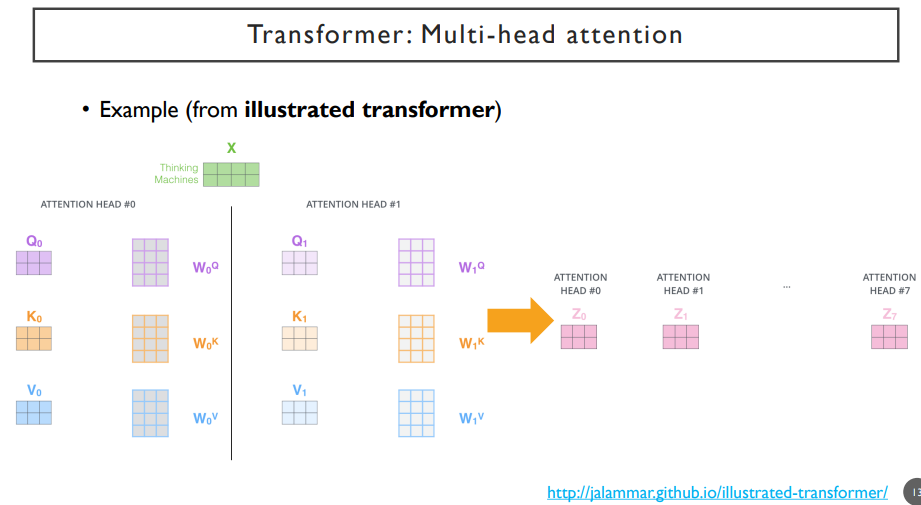
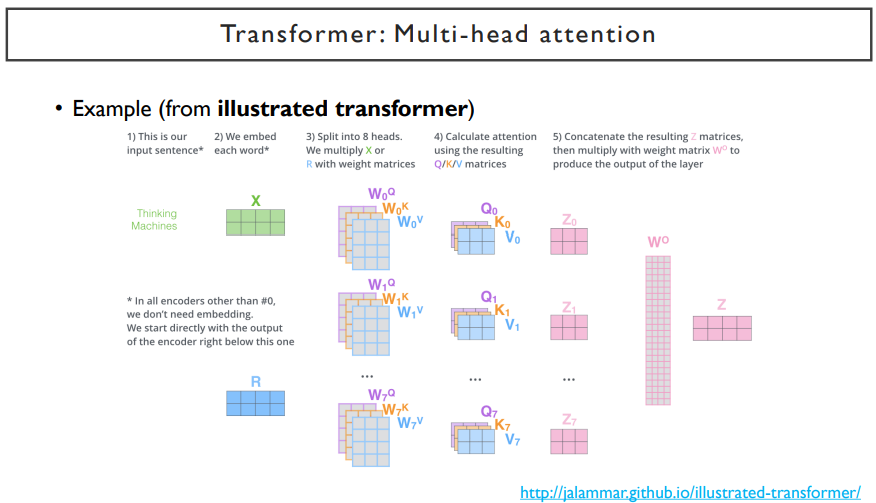
앞서 말한 과정을 그림으로 나타내면 위의 그림과 같다.
첫 번째, 두 번째 query, key, value로 만들어진 transformation에서 나온 각각의 attention head(value vector들)이 있다.
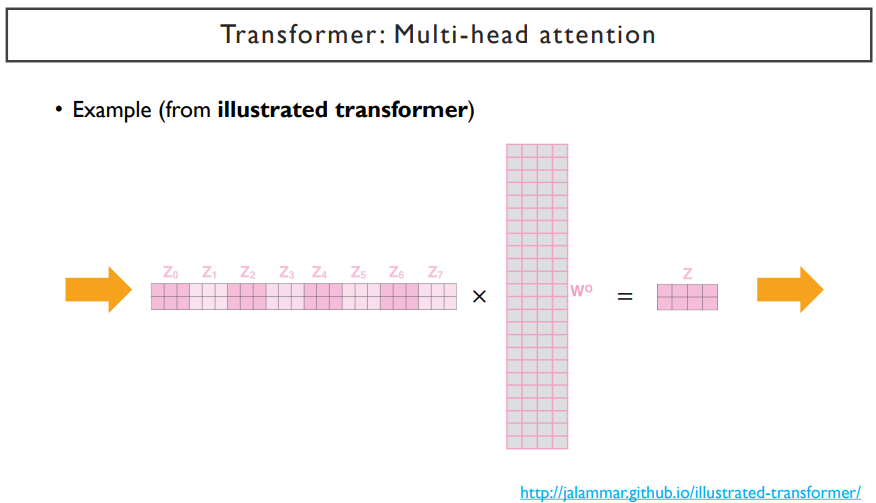
이러한 attention head들을 전부 concat해준 뒤(정보를 합쳐준다), linear transform을 통해 dimension을 줄여준다.
예를 들면, 각 head 별로 query vector의 dimension이 3이면, key vector의 dimension도 3이어야한다.(query와 내적해야하므로) value vector의 dimension은 달라도 된다. 여기서는 5라고 해보자. 가중합에 의해 나타나게되는 dimension은 5가 된다. 각 head에서 각각의 word들이 query로 쓰여져서 나타나는 각 word에 대한 encoding된 vector의 dimension은 value vector의 dimension과 같다.
만약, head가 2개 있다고하면, 두 번째 head는 위의 dimension을 그대로 쓰되, linear transformation인 Wq, Wk, Wv만 다를 것이다. 여기서도 5 dimension이 나타나고, head1에서 나왔던 dimension과 concat을 하게 되면, 10개의 dimension이 될 것이다.
이 dimension은 각 head에서 주어지는 value vector dimension에 head수를 곱해진 값과 같다. 따라서, head의 개수를 많이 쓰면 최종 dimension이 늘어나게 된다. 그렇게 되면, 한 word 각각을 encoding한 vector의 dimension이 너무 클 수 있기 때문에, linear transform(Wo)을 한번 더 거쳐서 dimension을 조금 줄여주게 된다.
여러 버전의 query, key, value로 변환을 시켜서 나온 vector들을 concat하고, 이것을 다시 linear transform을 통해 dimension을 줄여주는 과정을 통해 최종적으로 output encoding vector를 얻게 된다.
neural net은 행렬 연산을 병렬화해서 빠르게 할 수 있다. transformer 구조 또한 병렬연산을 통해 빠르게 학습한다. 하지만, RNN은 병렬화해서 연산하지 못한다. 그렇기 때문에, 학습이 굉장히 느리다.

self-attention은 병렬화가 가능하기 때문에, 학습이 훨씬 빠르다.
그러나 self-attention 기반의 모델이 RNN에 비해서 가진 단점은, 메모리를 많이 차지한다는 점이다. 메모리를 많이 차지하는 요인은 attention에서 가장 핵심이 되던 연산인 모든 query vector와 모든 key vector를 내적하는 과정에서 발생한다. 주어진 sequence길이가 n이라고 하면, (n^2)만큼의 메모리가 발생한다.
RNN은 재귀적으로 수행되기 때문에, 이후의 time step에서 이전의 vector를 계속해서 참조하지 않기 때문이다.
Transformer : Details in Transformer

위 그림에서 add가 residual connection, norm이 layer normalization에 해당한다.
2차원 벡터로 이루어진 입력들이 주어지면, query, key, value로 각각 몇 개의 dimension으로 이 벡터들을 변환해서 내적을 구해서 attention을 하고, dimension 크기를 줄여준 후 나온 최종적인 output은 2차원 벡터로 이루어진 입력들과 동일한 차원을 가져야 한다. 출력된 각각의 벡터들은 각각의 입력에 대해 encoding된 vector이다.
그리고 난 후, 이 입력과 출력을 더해주는 residual connection을 거치게 된다. 이것을 skip connection이라고 하는데, 이것을 만드는 이유는 다음과 같다.
input이 복잡하게 디자인된 모듈을 거치기 때문에, 정보가 좋은 방향(최적화되는 방향)으로 파라미터들이 변화하면서 학습을 할 수 있다. 하지만, 어떠한 training instance의 경우에는 layer를 100개정도 쌓아다고 할 때, 30번째 layer에서 필요한 정보를 뽑았다면 뒤쪽의 layer는 정보를 변질시킬 수 있다. 즉, dataset 전체적으로 보면, 좋은 역할을 할 수도 있지만, 어떤 data instance는 안좋은 역할을 할 수도있다. 이러한 현상을 방지하기 위해서 skip connection을 만들어서 네트워크가 필요없다고 생각하면, output을 0벡터로 만들어준 후, input을 그대로 더해줌으로써, layer를 skip하는 효과를 줄 수 있다. 이를 통해 전체적인 성능을 올리기도 한다. back propagation 측면에서도 gradient가 작아지는 단점이 생기게되는데, skip connection을 사용함으로써, vanishing이 일어날 수 있는 위험을 방지하고, 변질되지 않은 gradient가 전달될 수 있게한다.
또한, layer normalization을 통해서 약간의 변화는 생기지만 차원이 동일한 벡터들의 세트가 생기게 된다.
이러한 output이 feed forward라는 곳으로 들어가게 된다. feed forward는 encoding된 vector하나하나들을 동일한 fully-connected layer를 적용하는 것이다. 또한, 이전의 과정과 같은 과정을 거치게 된다.
이렇게 하나의 self-attention의 모듈이라고 볼 수 있는 block이 완성된다.
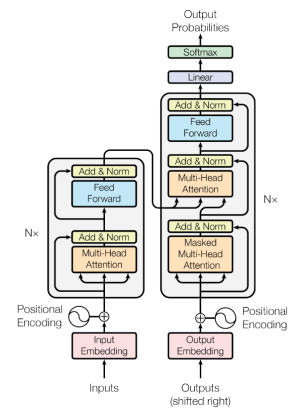
transformer 모델의 원래 구조는 위 그림과 같다. 왼쪽 박스부분이 위에서 말한 구조이고, Nx에서 N은 보통 6, 12, 24 정도를 쓴다. 이는 layer 수이다. layer를 쌓는다는 의미가 된다.
RNN에서 하나의 layer를 더 쌓을 때는, 전 layer에서의 RNN에서의 encoding vector가 word embedding으로써의 역할(xt)을 하고, 이것을 입력으로 받아서 다음 layer에 넣는 식으로 진행한다. RNN은 time step별로 동일한 파라미터들이 쓰이지만, 첫 번째 layer와 두 번째 layer의 파라미터는 다르게 된다.
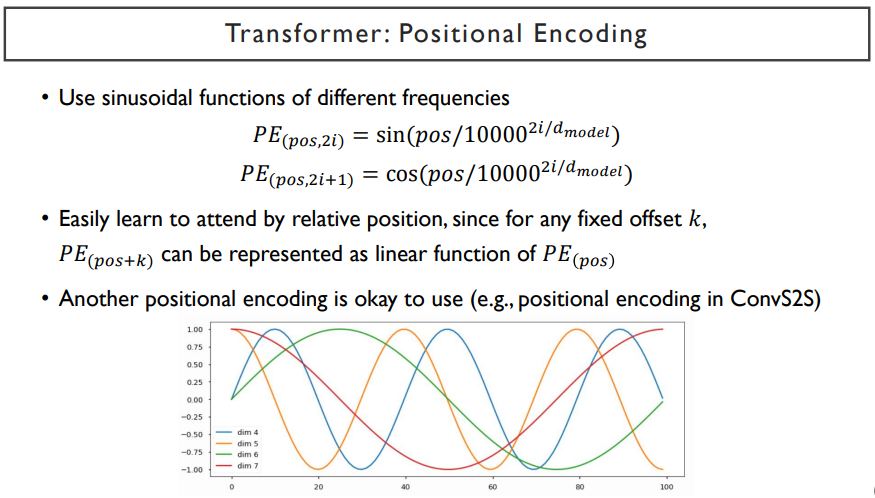
attention에서 순서가 무시되는 것을 방지하기 위해, positional encoding을 사용한다. 'I', 'go','home'으로 input을 넣었을 때와 'go', 'I', 'home'으로 넣었을 때 결과로 나타나는 encoding vector들이 순서에 따라 달라질 수 있게끔 만들어준다. 예를 들어, input vector가 3차원 벡터일 때, 첫 번째 vector의 첫 번째 dimension에 1000정도를 더해준다. 그리고, 두 번째 vector의 두 번째 dimension에도 1000을 더해준다. 이처럼 word들의 순서가 바뀌더라도 word들의 원래 순서를 규정할 수 있는 vector를 더해주는 것을 말한다.
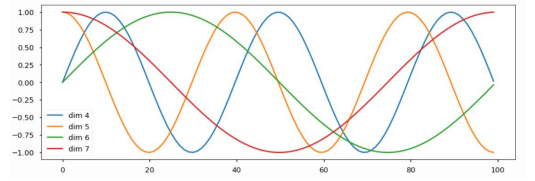
예시처럼 1000만이 아니라, sin그래프를 이용해서 각각의 x축을 순서라고 규정하고, x축에 수직인 줄을 그어서 sin함수와 접점이 되는 부분의 각각의 dimension의 값을 vector에 더해준다. 이렇게 sin 함수는 embedding dimension 만큼의 갯수만큼 있다.
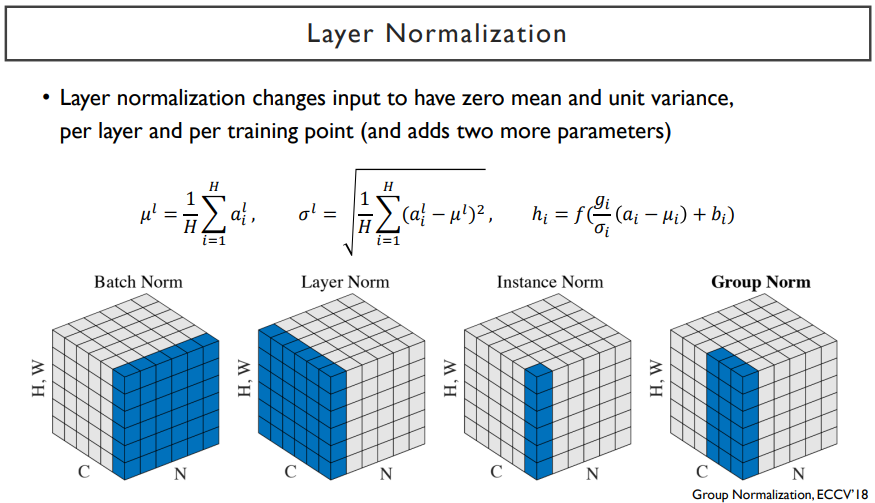
node 2개로 만드는 fully-connected layer가 있으면, 이는 선형결합을 통해서 만들어질 것이고, 만들어진 2개의 node는 ReLU나 tanh 등의 non linear을 거치게 된다. 이는 디테일한 정보를 없애고 상수값으로 나타내는 것이다. 비선형 변환으로써의 역할을 잘 하기 위해 적절한 값들의 range를 맞춰주는 것이 batch norm에서 하는 역할이다.
batch norm은 출력 node에서 발견되는 값들을 보고, 평균을 0, 분산을 1로 만들어주는 standardization을 거치게 되고, 이렇게 만들어진 값을 neural net이 필요로 하는 만큼 최적화된 값을 찾아나가는 변환을 해준다.
이러한 과정을 normalization layer가 해준다.
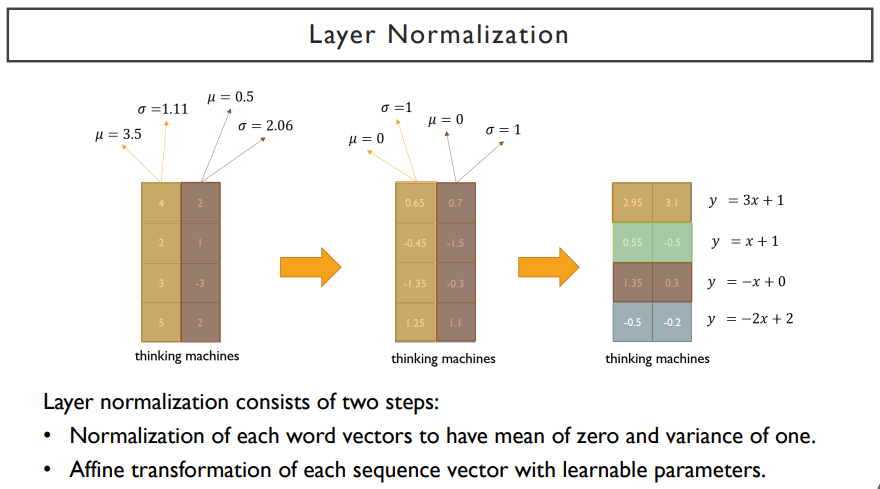
layer normalization은 각각의 word별로 한 layer 내에 있는 여러 node들에서 발생된 값들을 사용해서 평균, 분산을 구해서 normalization을 한다. 한 sequence내에서 여러 word들이 있을 때, 각각의 word들이 가지는 특정한 한 dimension내에서의 값들( ex. 위 그림에서의 [0.65 0.7] ) 을 y = ax + b 변환을 통해 최종적으로 거쳐지게 된다. 여기서 a, b값은 학습을 통해 얻어진 값들이다.
layer normalization은 batch norm과는 다른 기준으로 선정된 sample들로부터 얻어진 평균, 분산으로 normalization을 하지만, node 별로 동일한 affine transformation을 적용해준다. affine transformation에서 쓰이는 파라미터들은 학습을 통해 얻어진다.
결국, layer normalization은 학습을 안정화하고, non linear unit을 통과하기 전에, 값들의 범위를 적절하게 바꿔주는 역할을 한다.
RNN은 attention 기반의 모델로 바꿔서 sequence를 encoding하는 용도로 사용하는 경우,
예를 들어, 'I', 'go', 'home'이라는 input을 self-attention 모듈을 거쳐서 출력을 얻는다고 할 때, input의 순서를 바꾸게되더라도 self-attention 모듈은 이전과 같은 값을 낼 것이다. (key-value 간의 순서는 상관없기 때문) 이는 순서와는 상관없는 방식이다. 하지만, 순서 정보는 언어에서 중요한 요소이다.
다만, RNN은 순서를 처리할 수 있었다. 순서에 따라 encoding되는 정보가 바뀌기 때문이다.
이렇게 attention에서 순서가 무시되는 것을 방지하기 위해, positional encoding을 사용한다.
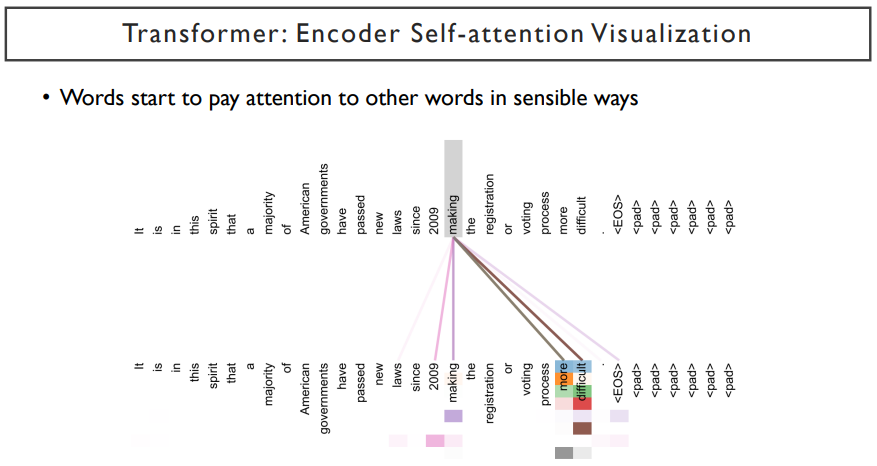
위 그림은 attention 패턴의 예제이다. 위쪽은 query word이고, 밑쪽은 key-value word이다. 이 예제에서는 making이라는 word가 어떤 attention을 가하고 있는가 를 나타낸다. more과 difficult에 많은 가중치가 더해지는 것을 볼 수 있다. 아래쪽의 head로 갈 수록 자기자신을 attention하기도하고, 시점에 attention을 가하는 것을 보여지기도 하다. 이렇게 서로 다른 head가 유사도를 추출해내는 기준이 다르다.
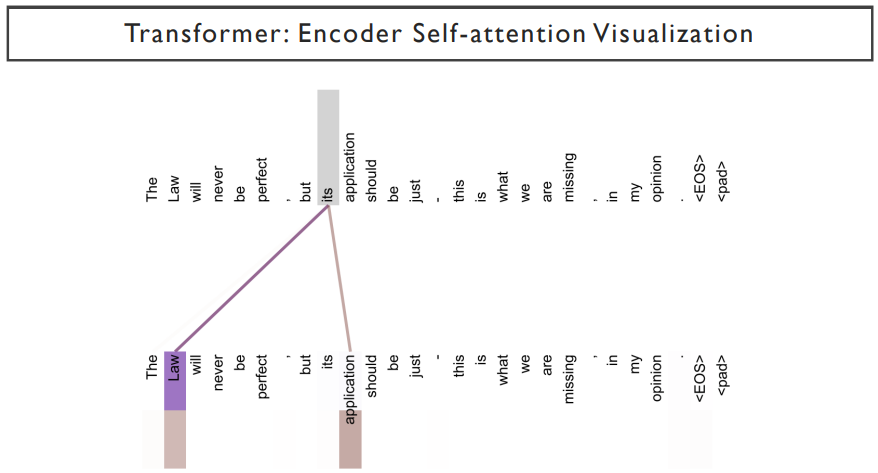
its가 attention을 통해서 어떤 정보를 받을지를 나타내고 있다.
Transformer : Decoder
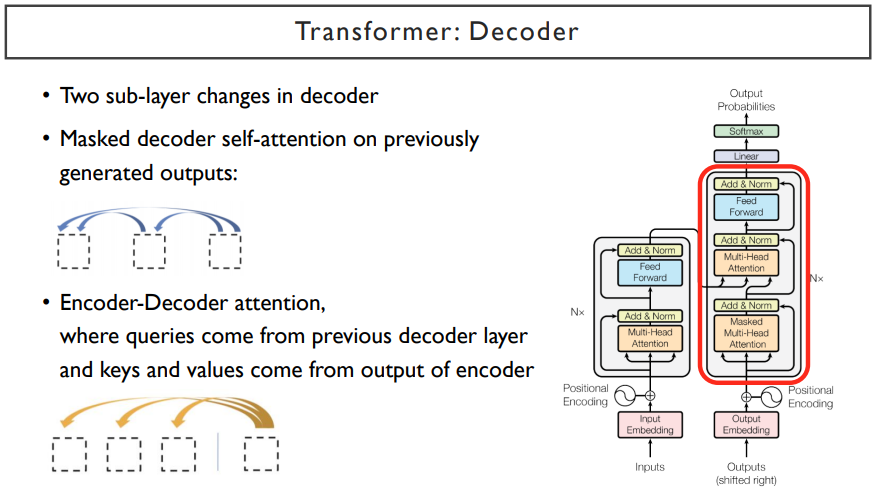
attention에서 마지막 단계에 해당하는 decoder이다.
위 그림은 original transformer 모델이다. 이는 seq2seq with attention 모델을 완벽히 대체하는 모델이다.
지금까지의 위에서의 설명은 encoder 부분이었다. 이를 통해 input을 encoding vector로 뽑는 과정이다.
다음으로는 decoding하는 부분을 살펴보자.
output은 <SOS>를 포함한 output word들의 embedding vector들이 input으로 들어오게 된다. 마찬가지로 position encoding도 지나게 된후, decoder과정을 지나고 <SOS> 다음 단어부터 output으로 나오게 된다.
decoder에서는 encoder에서 사용되던 self-attention block에서 masked 부분이 추가되었다. 이는, 현재 단어에서 self attention을 한다면, 앞쪽의 단어만 알고, 뒤쪽의 단어는 input으로 들어가면 안될 것이다. 뒤쪽의 단어는 예측해야하는 것이기 때문이다. 따라서, 앞의 단어만 참조하도록 뒤쪽의 단어를 mask로 막아주는 과정이다. 또한, 중간에는 입력으로 동일한 set가 들어간 것이 아니라, query는 decoder에서의 hidden state vector를 입력으로 받고, value와 key는 encoder의 hidden state vector를 입력으로 받는다. 그 후, feed forward 과정을 거치게 되면 decoder과정이 끝나게 된다. decoder도 N번의 layer를 쌓게 되고, 각각의 vector들을 output layer를 통과시켜줘서 다음 단어를 예측하는 과정을 거쳐서 최종 output이 나오게 된다.
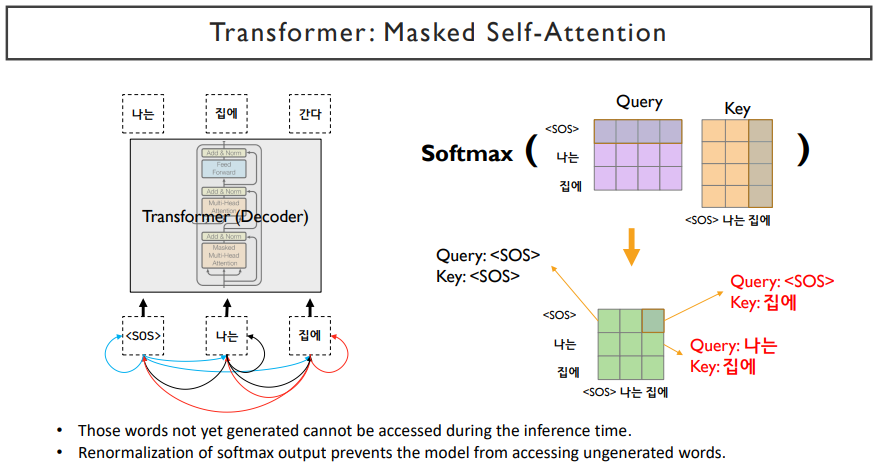
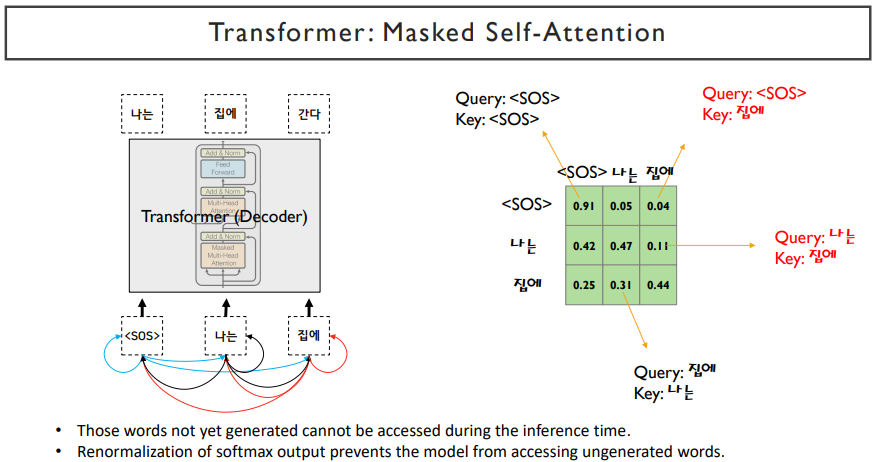
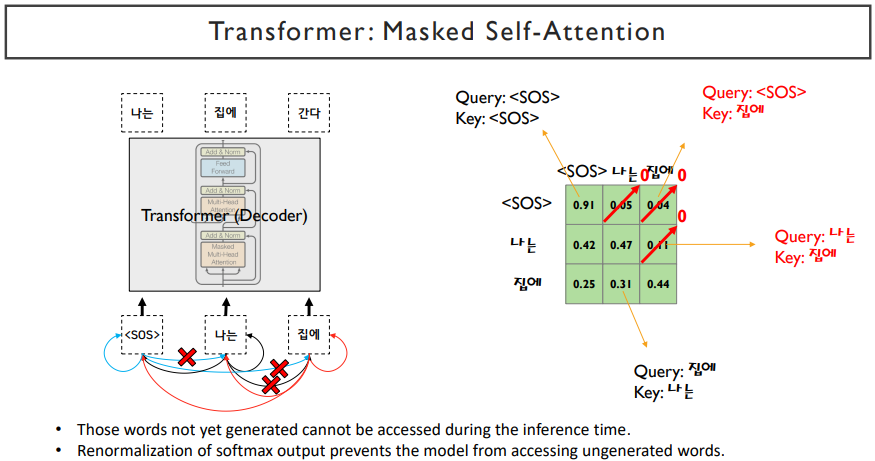
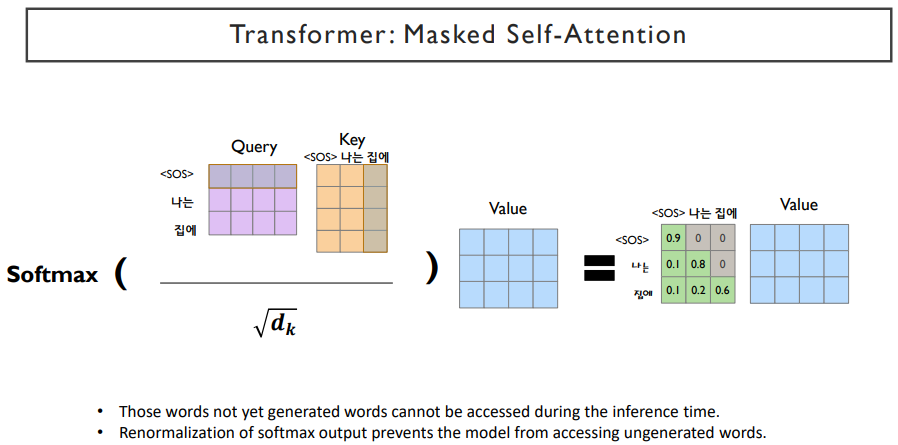
masked self-attention은 서로가 참조할 수 있는 attention에 mask를 씌어주면서 앞쪽의 단어들이 뒤쪽을 참조하지 못하게 한다. 뒤쪽의 단어들을 확률값을 0으로 하고, softmax를 취하고 나서 만들어지는 확률값이 0이 아니라면, 뒤쪽의 단어들은 전부 0으로 만들어주고, 나머지 확률을 re normalize해준다.
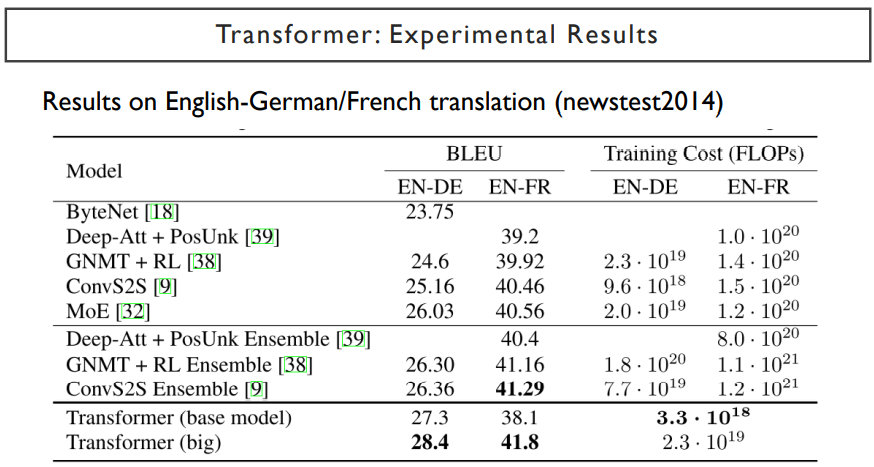
이렇게, transformer는 seq2seq모델보다 더 좋은 성능을 내는 것을 볼 수 있다.


'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 47. Transformers (0) | 2022.07.06 |
|---|---|
| Day 45. NLP Quiz2 (0) | 2022.06.20 |
| Day 43. Tokenization (0) | 2022.06.15 |
| Day 42. Preprocessing (0) | 2022.06.14 |
| Day 41. RNNs with Attention (0) | 2022.06.11 |