자연어처리 기술 중 가장 각광받고 있는 GPT에 대해서 학습해보자.
GPT-3가 나오기 이전에, 이미 OpenAI에서는 GPT-1, GPT-2에 대해 발표를 했었다.
이 모든 모델들을 알아보자

지금까지의 핵심 모델 구조는 크게 BERT와 GPT로 나눌 수 있다. 이 둘은 모두 transformer의 encoder 구조를 사용하고 있다.
이 둘의 차이는 GPT는 pre-training task를 language modeling(다음 단어 예측)을 사용한 것이다. ELMO와는 달리, 오른쪽 단어만을 예측하도록 한 것이지, 왼쪽 단어도 예측하는 것이 아니다.
BERT도 language modeling에 기반해서 pre-training한 모델이지만, Maked Language Modeling task를 통해서 pre-train된 transformer기반의 encoder 모델이다.
따라서, GPT는 standard하게 오른쪽에 나올 단어를 예측하는 것이다.

GPT-1 구조는 위와 같다. 이는 transformer 모델에서 제안된 구조를 그대로 가져온 것이다.
next word를 predict하는 task였지만, downstream task가 무엇이냐에 따라 여러 가지를 수행할 수 있도록 만든 모델 아키텍처이다.
GPT 계열 모델에서는 Masked multi self attention을 사용한다. 이를 사용하는 이유는, language modeling을 수행할 때, transformer의 decoder구조를 사용하는데, 현재 입력으로 들어온 단어는 자기자신만 볼 수 있고, 그 뒤의 단어를 볼 수 없기 때문에, 사용된다.
GPT는 다양한 형태의 downstream task에 대해서도 통합된 모델 구조를 제안한다.
여러 개의 text를 delim token을 통해 구분하고, 이를 통해 나온 값으로 출력을 구성해나간다.
이런식으로, 다양한 형태의 자연어처리 downstream task에 잘 대응할 수 있도록 가이드라인을 제시해준 모델이 GPT-1이다.

다양한 task들에서 기존의 모델들보다 더 좋은 성능을 낸 것이 pre-train된 모델의 성능향상의 결과임을 보여주고 있다.

GPT-2는zero-shot setting이 특이한 점이다. 이는, 특정 task를 하기 위해서 어떠한 학습데이터도 제공하지 않는 것이다.
zero-shot이 있다면, ML에서는 one-shot learning, few-shot learning등이 있다. 이는 학습데이터를 요약하기 위해서 단 하나의 데이터를 주거나, 아주 소수의 학습데이터를 주고도 taks를 잘 수행할 수 있는지 본다. 이들은 범용적으로 설정된 task를 미리 학습해놓은 후, transfor learning을 했을 때, 데이터가 많이 필요하지는 않을 setting이다.
예를 들면, 고양이와 강아지를 구분할 수 있는 모델이 있다고 할 때, 호랑이나 치타 사진 몇 장을 더 학습시켜서 이들도 구분할 수 있게 하는 것이다. 치타나 호랑이는 고양이와 비슷한 종이기 때문에, 고양이 사진으로부터 학습된 특징을 이용하여 추가적으로 호랑이, 치타에서 나타난 특징만을 빠르게 학습하여 구분한다.

앞에서는 GPT-1, GPT-2 생성모델들의 사전학습 모델 이야기를 했다.
GPT-3는 자연어 처리 뿐만 아니라, AI 전체에서 아주 핫한 모델이다. 이 모델은 성능이 아주 뛰어나서 많은 사람들을 놀라게 하기도 했다. 그러나, GPT-3도 GPT-1, 2의 다음 모델일 뿐이고, 결국 GPT-3도 transformer self attention의 encoder layer로 쌓여있을 것이다.
GPT-3는 OpenAI에서 낸 모델이다. GPT-3가 발표된 논문은 Language Models are Hew-Shot Learners이다.
GPT-2의 논문 제목처럼, GPT-2가 multi-task에 타겟을 맞추었다면, GPT-3는 few-shot 혹은 zero-shot으로, sample이 적은 경우의 task를 진행하는 논문이다.
달라진 점은, GPT-3는 모델 크기를 아주 많이 키웠다. 이를 통해서 few-shot 성능을 많이 올렸다. 하지만, 모델의 크기가 너무 큰 관계로 GPU하나에 모델 한 layer가 들어가지 않는 단점도 있다. 모델이 이처럼 너무 크기 때문에 huggingface에서도 따로 제공하지는 않고 있다. 만약, GPT-3를 사용하고 싶다면, OpenAI에 API를 신청해서 사용해야 한다.
GPT-3는 모델 크기가 너무 크기 때문에, fine-tuning이 사실상 불가능하다.
GPT-2의 경우에 fine-tuning을 하려면 다음과 같이 할 수 있었다. 예를 들어, 긍정, 부정으로 나누는 task를 진행할 때, GPT-2의 맨 앞에 문장을 넣고, 뒤에 [sep] token을 넣은 후, 이 token에서 나온 라벨을 projection을 시키는 구조를 구성한 후, fine-tuning할 수 있다.
하지만, GPT-3는 모델 크기 때문에 학습 자체가 불가능하지만, few-shot으로 학습할 수 있는 방법을 제공한다.

prompt는 모델에 prefix를 주어서 모델의 output을 맞추는 것이다.
예를 들어, 영화 리뷰를 맞추고 싶을 때, prompt를 제시한다면, GPT-3에 학습모드가 아닌, GPT-2 inference 상태에서 ' 영화 리뷰 + this review is ( ) ' 을 GPT3에 넣고 빈칸에 넣을 것을 맞추라고 한다. positive, negative 둘 중 하나의 단어가 나올 확률을 비교하는 것이다. 이런식으로 하면, 따로 학습을 시키지 않더라도, 원하는 답을 얻을 수 있을 것이다.
이런 식으로 직접적으로 학습시키지 않고, prefix를 주고 푸는 것을 zero-shot prompt라고 한다.
zero-shot prompt의 예시를 위 그림으로 살펴보자.
prompt가 들어간 후, GPT-3에게 다음에 나올 token을 맞추라고 하는 것이다. GPT-3가 잘 학습이 되었다면, 당연히 프랑스어가 나올 것이다. 이는, GPT-3가 이렇게 task를 매핑하는 것을 배웠다면, 아무런 sample을 주지 않고도 맞출 수 있다는 의미이다.
하지만, 모델 입장에서는 아무런 정보가 없다면 task를 알맞게 수행하기 힘들 수도 있다. 이를 보완하는 방법은 예시를 넣어주는 것이다. 이렇게 나온 것이 one-shot이다.
one-shot은 example을 하나 넣어주고, 다음 단어를 예측 하라고 넣어주는 것이다. 모델 입장에서는 이 예시를 학습한 것은 아니지만, 이 하나의 예시를 가지고 규칙을 파악해서 다음 단어를 예측할 수 있을 것이다.
만약, 예시가 너무 부족하다면, 몇 가지 예시를 더 넣어준 후 task를 실행할 수 있다. 이것은, few-shot이라고 하고, 이러한 방식이 GPT-3에서 꽤나 잘 되는 방식이다.
prompt를 만드는 방법은 다양하다. 자연어로 주기 때문이다. 어떤 prompt를 사용하느냐에 따라서 성능이 매우 달라진다. 이러한 연구 주제로 prompt tunning이 존재하기도 한다.
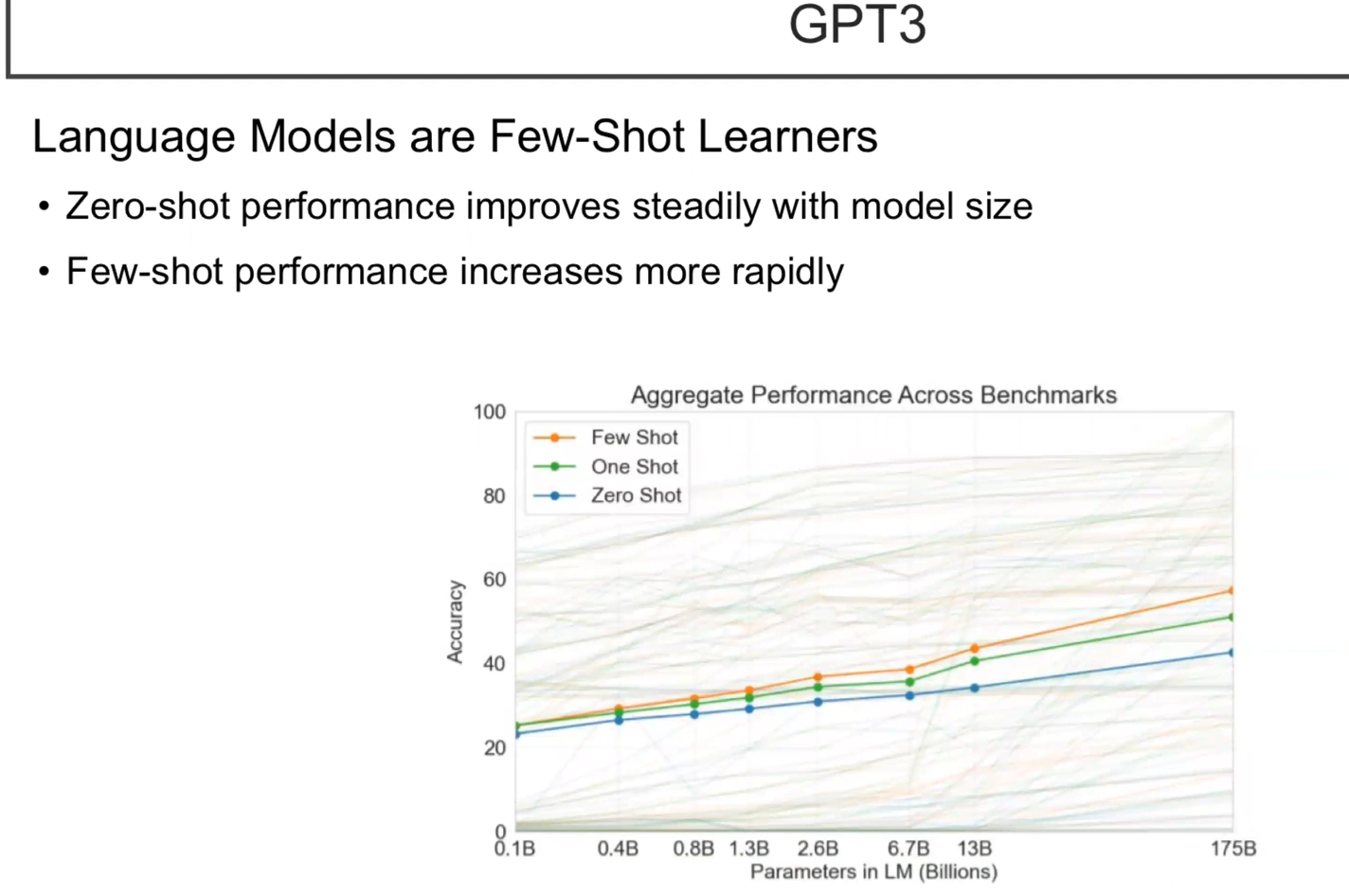
모델 사이즈를 실험이다. zero-shot과 few-shot이 모델 사이즈를 키우면 키울수록 학습이 더 잘됨을 알 수 있다. 또한, sample이 늘어날 수록 좋은 성능을 보임을 알 수 있다.
GPT-2를 가지고 위와 비슷하게 코딩을 해보자.
huggingface의 GPT를 사용하자. Language Modeling을 할 것이기 때문에, GPT2LMHeadModel과 tokenizer를 사용하자
다음과 같이 모델과 tokenizer를 불러오자
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
우리는, 나라를 넣으면 수도를 맞추는 task를 해볼 것이다. 다음과 같이 코드를 작성해보자.
prompt = """ \
The capital of England is\
"""
encodings = tokenizer(prompt, return_tensors = 'pt')
print(encodings)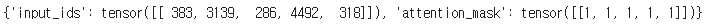
encoding이 잘 된 것을 확인할 수 있다.
생성하는 메소드를 사용할 것이다. huggingface에서의 generate라는 함수를 사용해보자.
outputs = model.generate(**encodings)
print(outputs)
노란색 부분은 위의 질문과 같고, 나머지 부분을 모델이 생성한 것이다. 이것을 보고 싶다면, decoding을 하면 될 것이다.
print(tokenizer.decode(outputs[0]))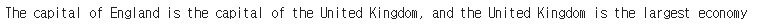
모델이 답을 잘 생성해주었다. 하지만, 의도한 대로 단어만 나타나지는 않는 것을 볼 수 있다.
이처럼 GPT-2는 zero-shot은 잘 작동하지 않는다.
예시를 다음과 같이 바꿔보자.
prompt = """ \
The capital of England is London
The capital of France is\
"""
encodings = tokenizer(prompt, return_tensors = 'pt')
outputs = model.generate(**encodings)
print(prompt)
print(tokenizer.decode(outputs[0]))
출력을 살펴보면, 우리가 원하는 것처럼 단어만 나오는 것을 확인할 수 있다. 다만, 길이 지정을 해주지 않았기 때문에 다음 문장까지 생성된 것을 알 수 있다. 이것이 one-shot 방법이다.
더 완벽하게 output을 내고 싶다면, few-shot을 사용할 수도 있을 것이다.
prompt = """ \
The capital of England is London
The capital of China is Bejing
The capital of France is Paris
The capital of Korea is\
"""
encodings = tokenizer(prompt, return_tensors = 'pt')
outputs = model.generate(max_length = 30, **encodings)
print(prompt)
print(tokenizer.decode(outputs[0]))
이처럼 알맞은 결과를 볼 수 있다. 이는, GPT-2가 사전학습 과정에서 어느정도 학습이 되었기 때문에 이렇게 잘 나온 결과를 볼 수 있다.
만약, 사용자가 국가를 입력할 때, 자동으로 수도가 나오는 시스템을 제작한다면 다음과 같이 모델만을 사용하고도 만들 수 있다.
while True:
nation = input("국가를 입력해주세오: ")
prompt = f"The capital of England is London\nThe capital of {nation} is"
encodings = tokenizer(prompt, return_tensors = 'pt')
outputs = model.generate(**encodings)[0, encodings['input_ids'].shape[1]:]
generated = tokenizer.decode(outputs).split('\n', 1)[0].strip()
print(generated)
그러나, GPT가 일반상식을 전부 알고 있지는 않다. 문장의 구조와 단어의 의미만 보면 그럴듯하지만 정확한 의미는 잘 맞추지 못하는 경우도 많다고 한다.
'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 50. Text Generation (0) | 2022.07.12 |
|---|---|
| Day 49. Applications (0) | 2022.07.07 |
| Day 47. Transformers (0) | 2022.07.06 |
| Day 45. NLP Quiz2 (0) | 2022.06.20 |
| Day 44. Transformer (0) | 2022.06.19 |