앞에서 나왔던 내용들은 자연어 이해를 돕는데 근간이 되는 Encoder에 대한 설명으로 주를 이루었습니다.
오늘은, 자연어 처리 분야에서 어떤 방식으로 문제를 정의하고, 이를 해결하는지에 대해 말해봅시다.
오늘은 encoder 기반의 주어진 text를 이해하는 taks들을 살펴볼 것이다.
understanding이라는 것은, natural language understanding이라고 하며, NLU라고 불린다.

encoder, BERT모델을 어떻게 사용하는지 알아보자. 또한, 각각의 task에 따라서 input과 output이 무엇인지 간단하게 살펴보자.
BERT가 있을 때, input의 처음으로는 [CLS] token이 들어가고, 문장의 token들이 들어가게 된다. 이렇게 모델의 input으로 어떠한 sequence가 들어가게 되면, 첫 번째 output이 embedding vector인 z가 나타나게되고, 이것이 classifier 모델의 fully-connected layer에 들어가서, predict-class를 내뱉게 된다.
이렇게 했을 때, 이 모델은 input이 주로 sentence(sequence classification task)이다.
sequence라는 것은 token, sentence, document로 나눌 수 있다. input에 이러한 sequence들이 들어갔을 때, 어떠한 형태를 나타내는가?
sequence classification(sentence classification)은 input이 sequence(sentence)가 되고, output이 우리가 원하는 class가 될 것이다. class는 전체의 input sequence에 대한 하나의 예측 값이다.
input이 sequence of token일 때, output이 sequence of prediction인 것은 token classification이다.
NLP는 여러 가지 기준으로 나눌 수 있다.
Task는 우리가 풀고자 하는 문제이다.
sentiment classification(감정 분석), machine reading(주어진 document를 이해하게 하고 원하는 정보를 뱉어내게 하는 것), machine translation(기계 번역), language model을 첫 번째 기준으로 나눌 수 있다.
두 번째 기준은, 우리가 어떤 문제를 풀 것인지를 정한 후, 어떠한 형태로 나눌 것인지이다. (Formulation) 수학적, 알고리즘 적인 형식으로 나누어주는 것을 말한다.
text classification(어떤 sequence가 들어왔을 때, 하나의 class로 예측하는 것), token classification(여러 개의 sequence가 들어왔을 때, 각각에 대응되는 output을 하나씩 내뱉는 것), retrieval(어떠한 document들을 특정한 이미지 feature dimension으로 매핑 시키는 것. 유사한 것들을 가져오는 것), text generation(어떤 벡터가 주어졌을 때, 원하는 sequence로 만들어내는 것)
첫 번째와 두 번째 기준은 어떤 문제를 어떤 형식으로 풀 것인지에 대한 것이다. 즉, problem setting의 영역이었다. 이렇게 정의된 문제를 다양한 모델을 사용해서 해결 할 수 있을 것이다.
세 번째 기준은, 모델이다.
RNNs, Encoder-Decoder model, Attention model, Transformer model 중에서 하나 혹은 여러 개를 조합해서 사용할 수 있을 것이다.
네 번째 기준은, 학습 방법이다.
크게 세 가지로 나눌 수 있다. vanilla는 모델의 초기화를 random으로 파라미터를 설정하는 것이다. 즉, random initialization이다. 처음부터 학습을 진행하는 것이다.
pretraining & finetuning은 이전의 큰 데이터에서 사전학습된 A라는 모델을 가져와서 내가 가진 task에 맞게 한 번 더 학습을 시켜줌으로써, A의 정보는 그대로 가지고 있지만, 나의 데이터셋에 조금 더 어울리게 맞추어진 모델을 만들어내는 것이다. 보통 Bert pretrained를 많이 사용한다.
In-context learning은 GPT와 같은 거대모델에서 많이 사용된다.
모델의 input과 output에 따라 다양한 형태가 존재한다.
이것을 BERT version으로 본다면, 오른쪽 그림과 같이 생각할 수 있다.
sentence pair classification task는 문장이 두 개 들어왔을 때, 이것들이 같은 class인지를 예측하는 것이다. 따라서, input에서 [SEP] token으로 두 문장을 구분하게 되고, 처음에 [CLS] token을 넣어서 들여온 뒤, output으로는 하나의 class를 내뱉는 것을 볼 수 있다.
나머지 task들은 이제부터 알아가도록 하자. 이 세 가지 task들을 보면, many-to-one와 many-to-many에 대응이 된다.
Bi-directionals RNN의 경우에는 순서대로 input이 들어갔을 때, forward와 backward를 concat을 해서 최종적으로 output들을 만들어낸다. 이것이 classifier에 들어가서 모델의 input으로 들어가게 된다.
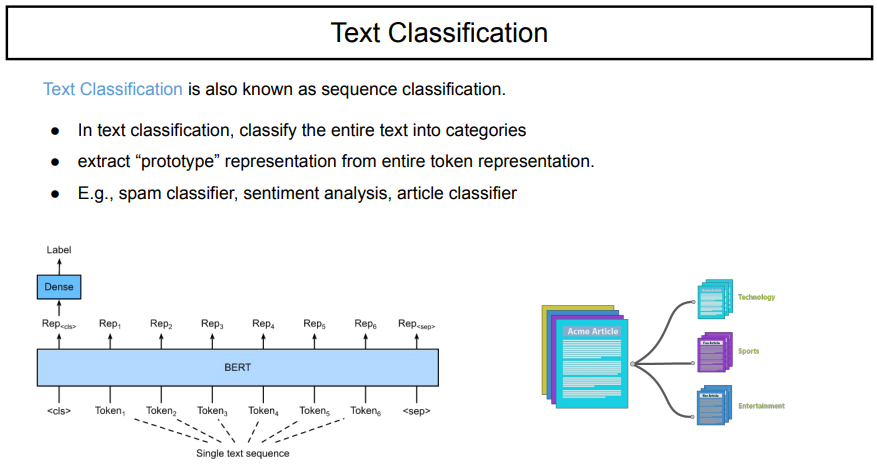
문장 전체를 보고 이것에 대해 classification을 하는 것이 text classification이다.
이러한 text classification은 sequence classification이라고도 알려져 있다. 이것은 text 전체를 사전에 정의된 카테고리 class로 구분하는 것이다.
모델 구조는 many-to-one으로 구성되며, 대표적인 예로는 스팸 분류기, 감정 분류기, 기사 분류기 등이 있다.
예를 들어, 기사 분류기를 진행한다고 했을 때, 주어진 text를 하나하나 읽어보면서 word가 IT, AI, IOT를 다루고 있다면, technology로 분류를 하게 되는 것이고, 배구, 야구 이야기를 한다면 sport로 분류하게 되는 것이다. 이처럼 전체 맥락을 파악하여서 하나의 dense(형태가 flat함) 로써, 전체 문장의 의미를 포함하는 representation이다. 이것을 가지고 classifier를 거쳐서 예상한 predict class를 하는 것이다.
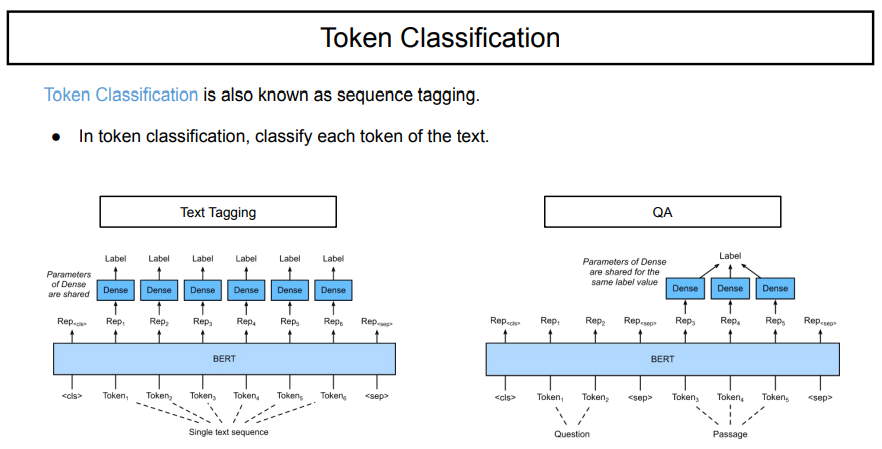
token classification은 token을 분류하는 모델이다. text를 구성하고 있는 token 하나하나를 특정 class로 구분해 주는 것이다.
token classification의 다른 모델로는 sequence tagging이라고도 한다. tagging은 어떠한 객체, 혹은 input이 있을 때, 이것을 하나씩 tagging해준다는 의미를 지닌다. 이는 각각의 요소에 따라서 라벨을 부여해준다는 task가 될 것이다.
어떤 것을 tagging하고 싶냐에 따라 token classification을 두 가지 형태로 나눌 수 있다.
먼저, text tagging은 token 각각에 대해서 class를 구분하는 것이다. 이것은 input token 하나 당 하나의 label을 붙여주는 것이다. 이 모델 구조는 실시간 many-to-many이다. 대표적인 예로는 NER이 있다.
QA(Question answering)는 질문과 문단이 주어졌을 때, 질문에 대해서 답으로 낼 특정 부분에 대해 labeling을 해준다. 아키텍처의 형태를 보면, many-to-many이다.
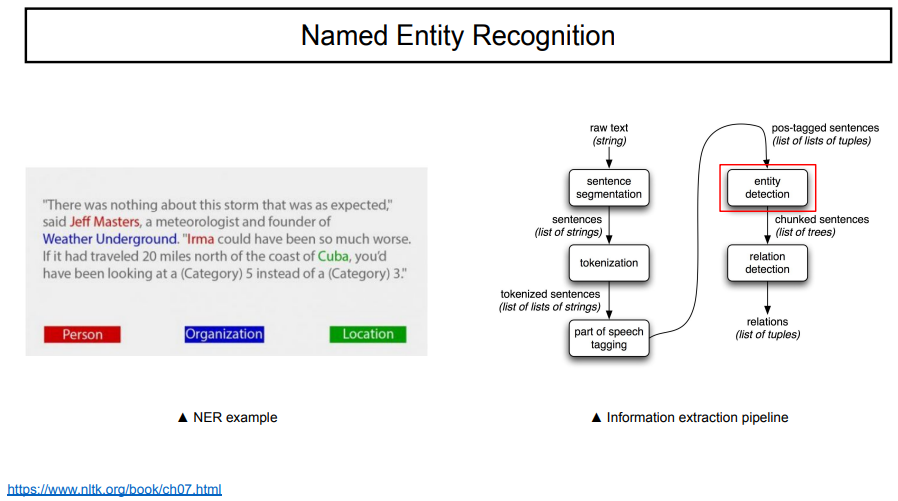
NER은 Named entity recognition으로, 전체 text에서 일부분의 named entity를 찾는 것이다. 이것을 tagging해주는 것이다.
보통 NER을 혼자 쓰지는 않는다. 어떤 text가 주어졌을 때, 이를 document(multiful sentence), 즉, 문단이라고 하자. 이를 문장별로 나눈다. 그 후, 문장을 token으로 나눈다. 이것을 POS tagging을 해준다. 이는 token이 문장에서 어떤 의미를 갖는지 알려준다. 이 각각의 token에 대한 객체를 인식한 후, 객체 간의 관계를 예측한다. raw text로부터 관계를 뽑아내는 과정까지 이러한 순서대로 이루어진다. 우리가 지금 공부하는 NER은 위 과정 중 entity detection에 해당한다.
위 예시에서 보면, Jeff Masters라는 사람이 weather underground의 founder라는 관계를 뽑아낼 수 있다. 이러한 것은 지식그래프라고도 불린다.

Named entity는 실존하면서, 고유의 의미를 가지고 있는 모든 것을 말한다. 쉽게 말해, 고유명사이다.
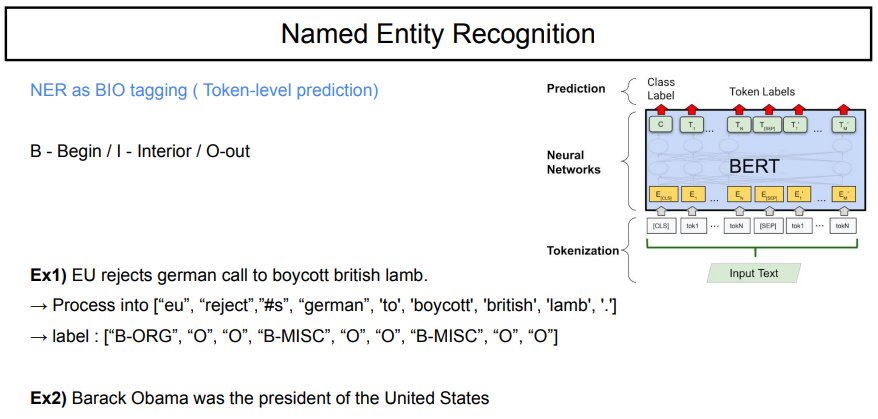
이 때, NER을 BIO tagging이라고 하여 begin, interior, out으로 태깅을 해서 구분을 한다.
위의 예시를 보면, tokenization을 통해서 나눈 후, 'eu', 'german', 'boycott'을 태깅한다.
두 번째 예시를 본다면, 'Barack'을 'B-PER'로, 'Obama'를 'I-PER', 'United'를 'B-MISC', 'States'를 'I-MISC'로 태깅할 수 있고, 나머지는 'O'로 태깅될 것이다.

QA모델을 살펴보자.
QA모델은 machine reading comprehension의 하위버전이라고 생각할 수 있다. QA는 기본적으로 input으로 context와 질문이 주어졌을 때, output으로 context에서 예상되는 정답의 영역을 내뱉는 모델이다.
extractive는 가정을 가지고 있는데, 이는 정답 값이 항상 주어진 context에 포함되어있다고 하는 것이다.
오른쪽 예제를 보면, Reader가 QA모델이라고 하자. input으로는 question, context를 받는다. output으로는 답을 내뱉는다.
BERT에서 question과 context가 들어가는 형태는, ' [CLS] question [SEP] context '로 들어가게 된다.
output으로는 start_token과 end_token을 맞춰서 나오게 된다.
Reader 모델이 있을 때, [CLS] Q1 Q2 Q3 ... [SEP] C1 C2 C3 ... C25가 input으로 들어갔다고 하자. 각각의 token에 대해서 이것이 start token인지, end token인지 맞추는 classifier를 진행해야한다.
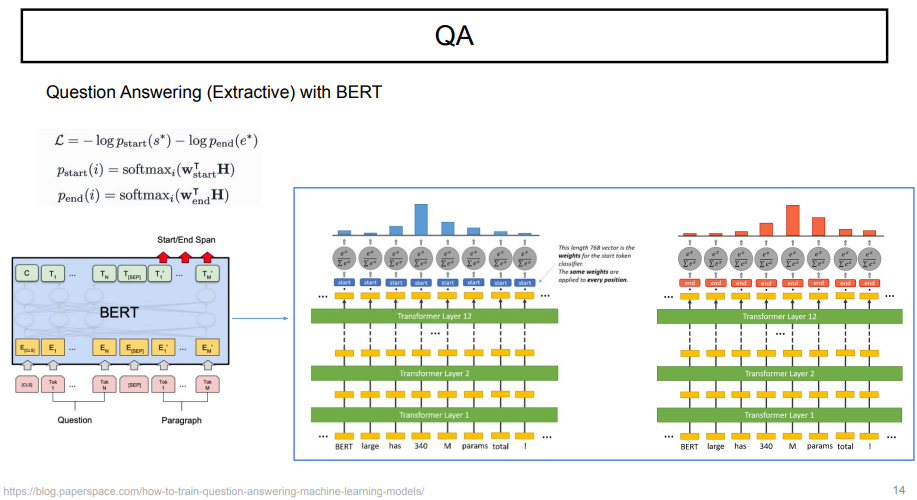
실제 BERT를 사용할 때, 어떤 식으로 start, end index를 구하는지 살펴보자.
모델의 input이 sequence로 들어갈 때, output은 start와 end점만 구분할 수 있으면 된다.
보통 Bert-based extractive QA 모델은 supervised learning으로 학습이 된다. start, end의 weight를 곱해져서 학습이 이루어진다. 그리고, softmax를 취해 i 번째 index가 각각 start, end일 확률을 구해준다.

QA에서 가장 자주 사용하는 데이터셋은 SQuAD, CoQA가 있다.
데이터셋을 보면, dictionary형태로 이루어져 있으며, context, question, answers가 들어가 있다.

pre-trained BERT를 사용해서 QA 모델을 돌려보았을 때, answer로 #이 들어간 답을 내는 것을 알 수 있다.
이는, likelihood가 최대가 되는 방향으로 하나의 vocab token을 합치기 때문에, 자주/중요한 단어만 합치게 되기 때문에 그 결과로, input에서 unknown token을 구분하고, 유사한 것 끼리 뭉칠 때, rare words는 subword로 나누어지게 된다.
karingu는 한 단어이지만, karin은 자주 사용되는 단어이고, gu는 따로 떨어진 단어이다. 하지만, 이 둘이 같은 단어임을 의미하기 위해 ##을 붙이며 표현한다.

BERT의 input sequence length는 512보다 작아야 한다. 즉, BERT의 max length는 512 token이다.
QA task를 진행할 때도, context가 너무 길다면, 한 번에 BERT 모델에 넣을 수 없다.
또한, long term dependency의 문제가 생긴다. 가지고 있는 질문에 대한 대답이 문단의 뒤쪽에 있을수록, 앞의 내용을 까먹는 문제점이 발생한다. 이로 인해, 성능이 저하된다.
context가 매우 길 때, context를 나누어서 관련있어보이는 부분만을 넣어준다면, 성능이 저하되는 현상을 조금 방지할 수 있을 것이다.
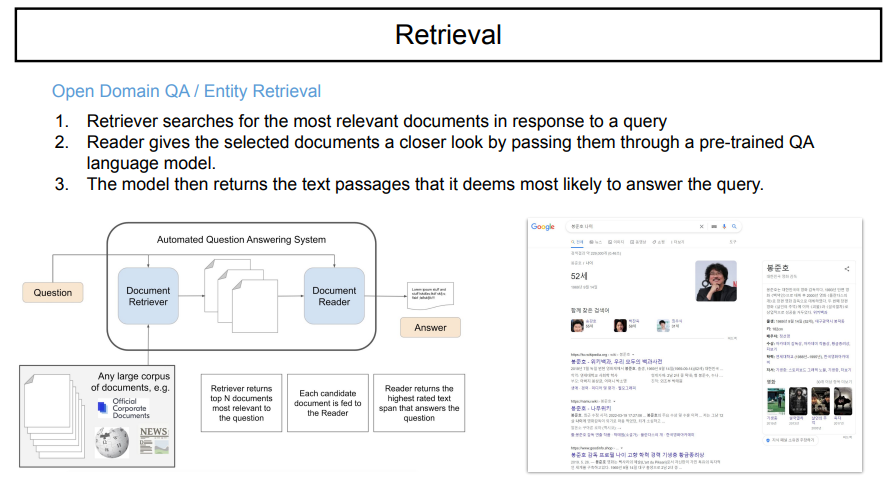
어떤 input source를 줄여주고, 적정한 text를 찾아오는 것을 retrieval이라고 한다.
retrival이라는 것은, 즉, information search라고 할 수 있다. 구글이나 네이버에서 주로 많이 사용하는 테크닉이다.
QA 중 open domain QA가 있다. 이는, 인터넷에 있는 정보를 전부 사용할 수 있는 QA 시스템이다. 이는 내가 어떤 검색 키워드 question에 대응하는 유사한 것만 가져오는 document retrieval이다. document retriver 와 document reader가 결합된 것으로 answer를 내는 것이다.
예를 들면, 구글에 '봉준호 나이'라는 question을 치면, 구글이 '52세'라는 answer를 내보낸다. 이는, 구글이 가지고 있는 수많은 context들 중에서 관련 있는 답들을 모아서 하나의 답으로 내보낸 것이다. 이것이 open domain QA의 대표적이 예시이다.
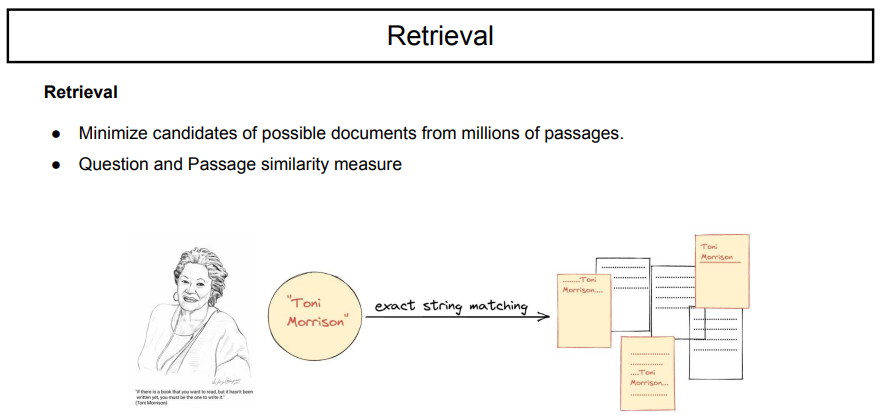
retrieval을 어떻게 할 수 있을까?
'toni morrison'이라는 단어를 검색할 때, 찾을 수 있는 정보는 무엇일까?
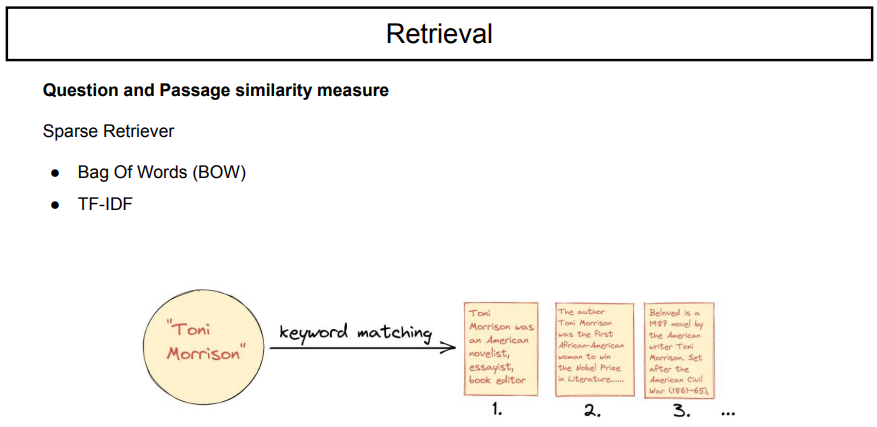
이를 찾을 수 있는 방법 중 하나는 sparse retriever를 사용하는 것이다.
sparse는 비연속적인 값(숫자 하나하나)이고, dense는 연속적인 값(범위)이다.
sparse는 이러한 특징으로, frequencey를 기준으로 한다.
sparse retriever는 bag of words(단어 각각이 서로 등장할 확률은 독립이다. 즉, 순서 고려하지 않는다.) TF-IDF는 frequencey기반이지만, documnet에서 대부분 등장하면 중요도를 낮추고, 특정 document에서 자주 등장하는 것을 높은 중요도를 주는 것이다.
'toni morrison'에 대한 정보를 찾을 때, similarity를 계산해서 관계를 찾아낼 수 있다.
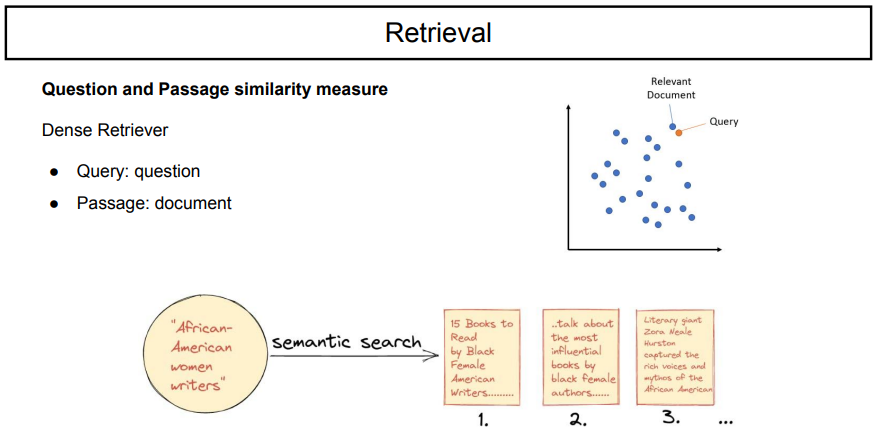
그러나 dense retriever를 사용하면, 딥러닝 메소드를 사용해서 encoded text vector를 기준으로 text를 추출할 수 있다.
우리는 document를 가졌을 때, 이것이 어떤 의미를 갖고 있는지를 기준으로 가져오게 된다.
수많은 document들 중 무엇을 선택할 것인가에 대한 기준은 query(질문)이고, 결과(passage)로는 question과 유사한 document가 나와야 한다.
고차원 공간에 text를 embedding하고, 2차원으로 맵핑할 때, query가 위치한 곳에 가장 가까운 document를 가져오는 것이다.
dense retrieval은 어떻게 하는 것일까?
question과 document들의 similiarity를 softmax로 취한 값 중에서 높은 값을 가진 것을 output으로 내놓는 것이다.
dense retrieval을 사용해서 좋은 점은, hidden representation을 쓰기 때문이다.
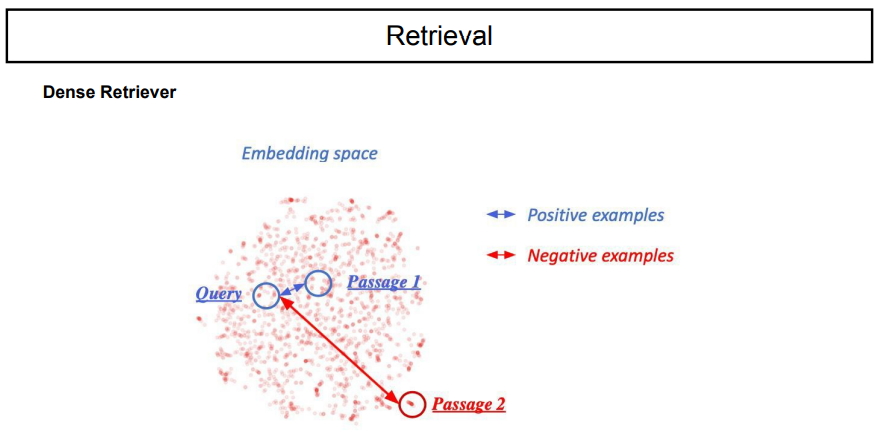
documnet들을 embedding한 결과이다. 의미있는 것들끼리는 가까이, 의미없는 것들끼리는 멀리 존재한다.
bert의 output dimension은 B x S x D이다. 이를 시각화를 하기위해서는 하나의 점을 위치시키는 문제이기 때문에, batch는 1로 평균을 내어준다. S x D는 dimension을 기준으로 평균을 내어준다. 결과적으로, mean pooling을 통해 D라는 dimension으로 압축이 되고, 이를 dimension reduction이라는 기술을 통해 시각화를 하는 것이다. reduction의 대표적인 예로는 PCA가 있다.
embedding space에서 주의할 점은, positive와 negative의 의미이다. 이는 학습된 환경에 따라 달라질 수도 있으며, 반대의 의미가 아니다. 예를 들면, article classification을 수행할 때, sports와 technology는 반대의 의미는 아닌 것처럼 말이다.

'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 51. Machine Translation (0) | 2022.07.13 |
|---|---|
| Day 50. Text Generation (0) | 2022.07.12 |
| Day 48. GPT (0) | 2022.07.06 |
| Day 47. Transformers (0) | 2022.07.06 |
| Day 45. NLP Quiz2 (0) | 2022.06.20 |