자연어처리 기술 적용 분야인 자연어 생성(text generation) 관련 내용입니다.


무엇이 text generation인가? text generation은 텍스트 생성하는 것이다.
지금까지 해온 것은 NLI(자연어 이해)이다. 문장을 받았을 때, pos, neg를 classification하는 것 등을 말한다.
NLG는 문장 자체를 생성하는 것을 중점에 두고 있다.
text generation은 다양한 분야에서 쓰일 수 있다.
챗봇, machine translation, 문장을 자유롭게 생성하는 것, 문장 요약 등에 쓰인다.

open-ended generation에 대한 예시는 위와 같다.
prompt로 단어 3개를 줄 때, 그 단어들에 대한 하나의 story가 생성되는 것이다.

또 다른 예시는, application의 document summarization가 있다.
이것은 extractive summarization, abstractive summarization으로 나뉜다.
extractive generation은, source 문장이 존재할 때, 그 안에서 몇 가지 단어만 뽑아내서 그 단어를 이어붙여 문장을 요약하는 task이다.
abstractive summarization은 source text를 읽고 말그대로 summary를 생성하는 것이다. 이것이 더 자유롭게 생성 가능하지만, 제대로 된 결과를 보는 것은 어려울 것이다.

챗봇도 또 하나의 예시가 될 것이다.
챗봇이 말하고 사람이 말하는 과정을 이어가면서 대화의 문맥을 유지해야 할 것이다.


text classification은 예측해야할 값들이 정해져있다.
하지만, text generation은 생성될 수 있는 종류들이 너무 많다. 예를 들면, 같은 문장을 말하더라도 영어로 말하기, 반말로 말하기, 사투리로 말하기 처럼 말이다.
이러한 text generation을 쉽게 하기 위해서 연쇄적으로 조건부 확률을 적용하는 방법을 사용한다.
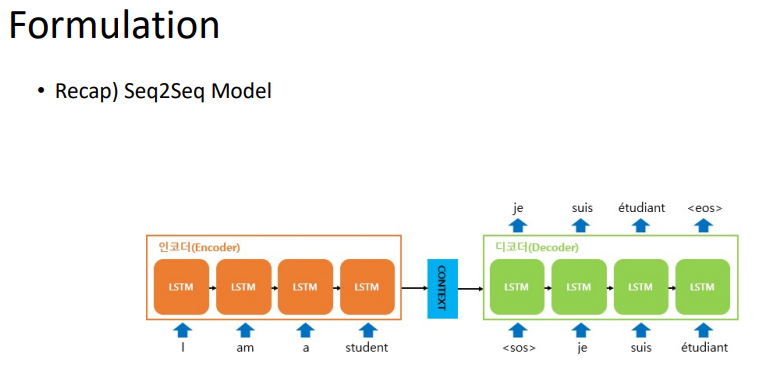
결국, 어떤 모델을 구성하는지가 가장 중요할 것이다.
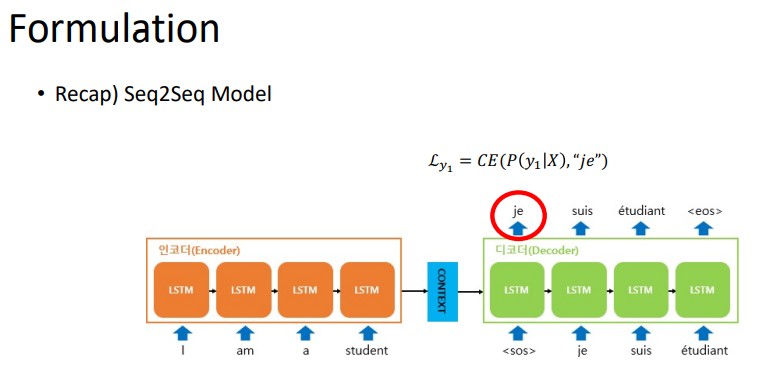
맨처음 input이 들어가고, <SOS> token의 위치의 출력까지 나왔다고 할 때, 위 식에서 y1이 나올 확률을 maxmize하는 것을 말한다.
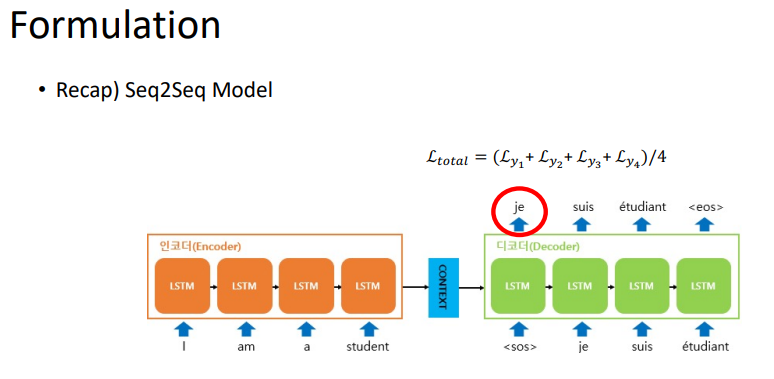
이렇게 각각의 token에 대한 loss를 구하고, 이것을 평균을 내어 총 loss를 구할 수 있을 것이다.
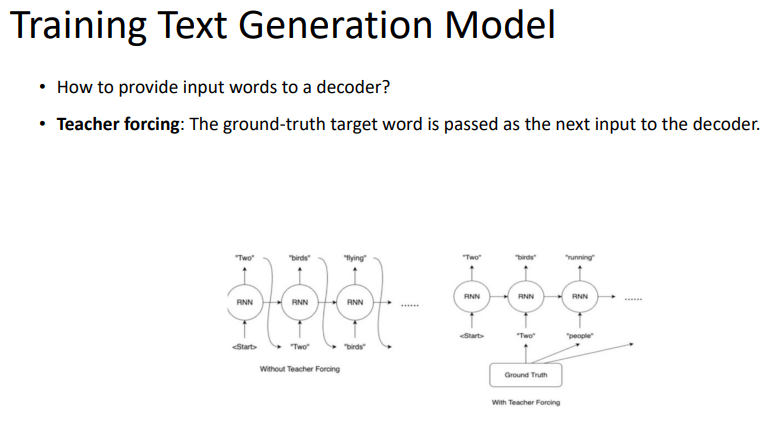
target을 생성하기 위해서는 input을 집어넣어야한다.
첫 번째로는, 생성된 결과를 다음 input으로 집어넣는것이고, 두 번째로는 ground truth를 input으로 집어넣는 것이다.
두 번째 방법을 teacher forcing이라고 부른다.
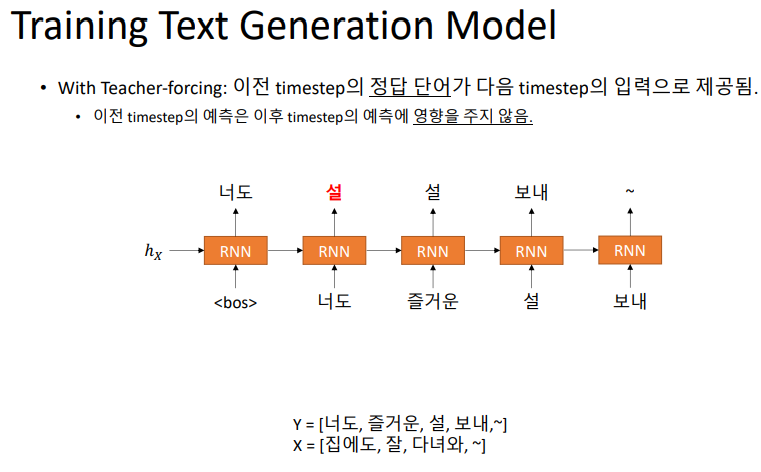
teacher forcing은 출력으로 오답이 나오더라도 다음 time step에 영향을 주지 않는 효과가 있다.
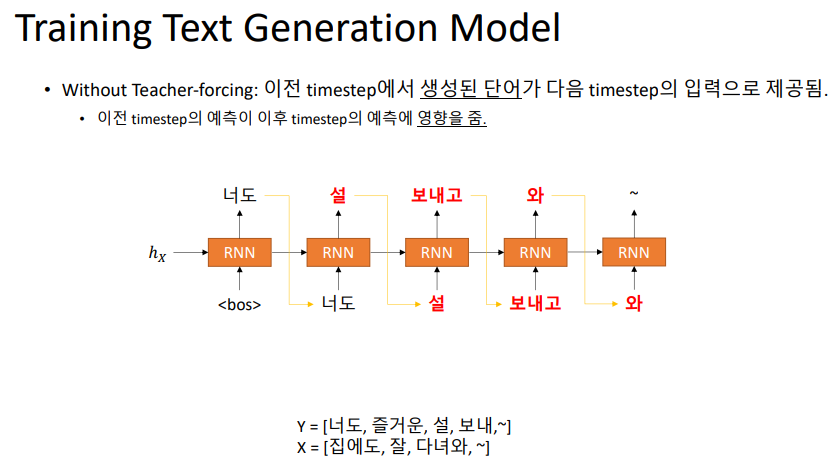
teacher forcing을 사용하지 않는다면, 이전 time step에서의 예측이 다음 time step에서의 예측에 큰 영향을 끼칠 것이다.

이들은 장단점이 있을 것이다.
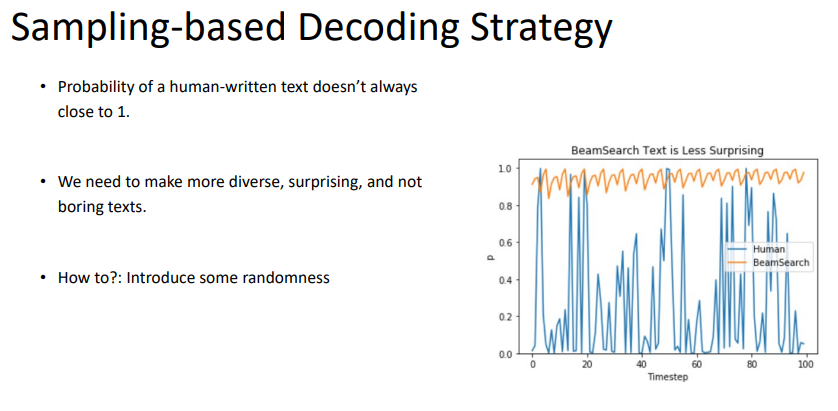
teacher forcing을 하게 된다면 exposure bias(이상하게 예측을 하더라도 테스트 단계에서는 답을 알려줄 수 없기 때문에 time step이 지날수록 더 엉뚱한 결과를 내뱉게 되는 것) 문제가 생길 수 있다.
만약, teacher forcing을 쓰지 않는다면, 어느정도 모델이 이상한 예측을 할 것이라고 예상하기 때문에 exposure bias가 어느정도 줄어들 수 있다.
teacher forcing을 쓰지 않아 생기는 단점은, GPU 연산이나 병렬화를 할 때 굉장히 비효율적이다. 뒤의 결과를 얻기 위해서는 맨 앞에서부터 하나하나 계산을 전부 다 해야하기 때문이다.
최근의 모델은 teacher forcing을 사용해서 학습을 더 오래 시키는 것을 이득이라고 판단하기 때문에, teacher forcing을 많이 적용하는 편이다.
huggingface에서 제공하는 모든 loss계산들은 teacher forcing이 적용되어 있다.


모델 생성은 어떻게 할까?
generation을 할 떄에는 ground truth가 없기 때문에 teacher forcing을 쓸 수는 없을 것이다. 그렇기 때문에 이전 time step의 output과 hidden state를 같이 받아서 다음 time step의 input으로 넣어주어야 한다.


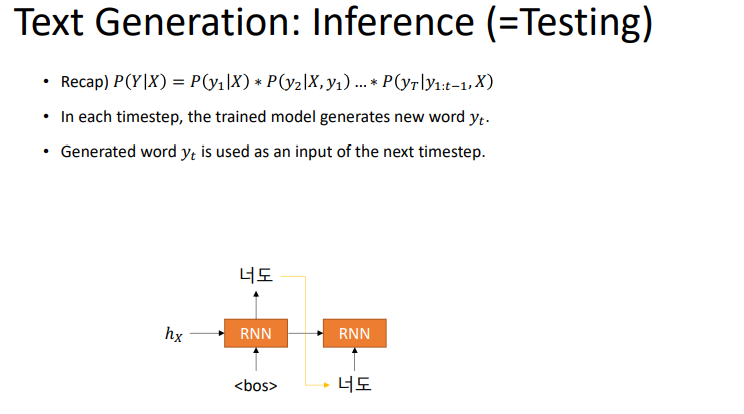



위의 그림처럼 어떤 token을 고를 것인가를 고려하여 다음 input을 주면된다.
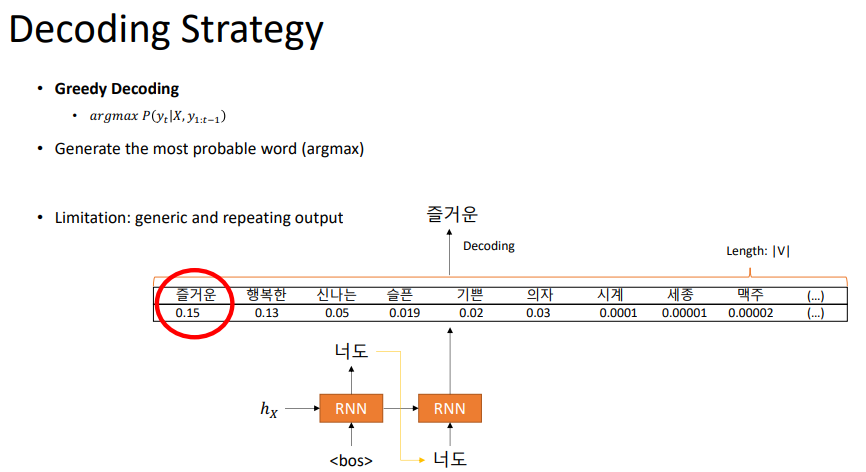
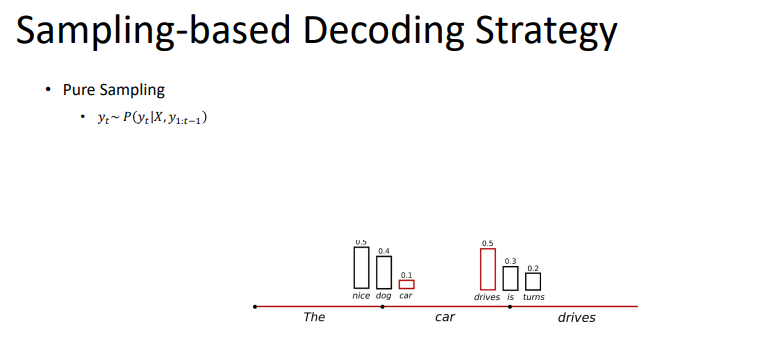
단순한 방법은 확률이 높은 것을 넣어주는 것이다. 이를 greedy decoding이라고 부른다.
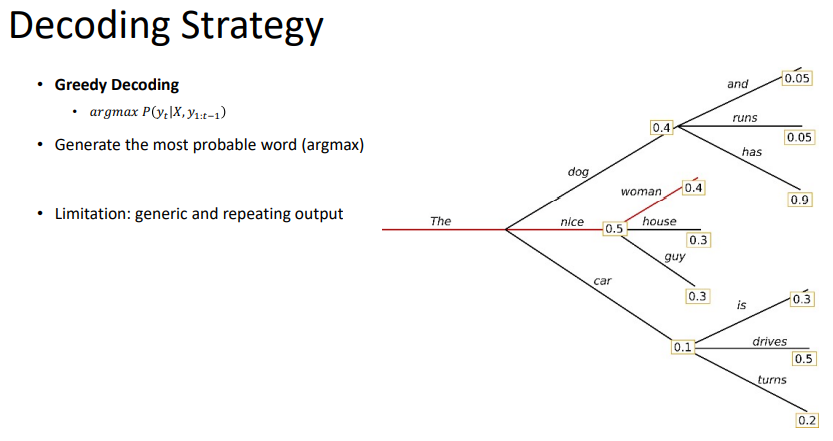
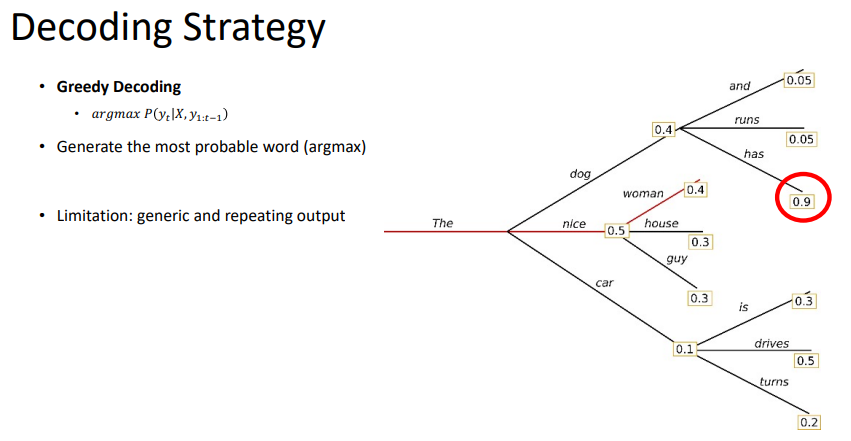
하지만, greedy가 최적은 아니다. 위 그림처럼의 경우도 있을 것이다. 이러한 경우는 greedy decoding을 할 수 없다.

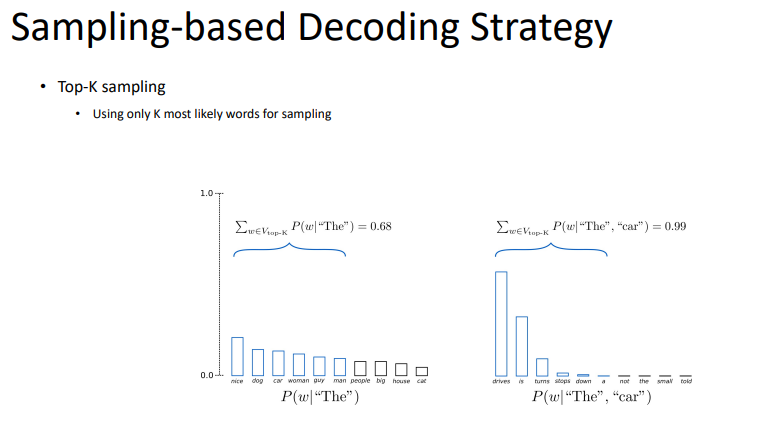
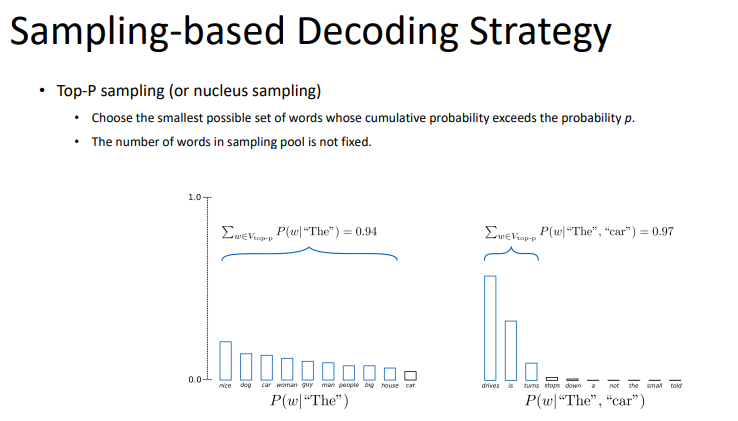
greedy decoding이 항상 좋은 것을 고르는 것이 아니기 때문에, 몇 개의 괜찮은 경우의 수도 고려하는 것이다.
k가 1이면 greedy지만, k가 2이상이면, beam search라고 할 수 있다. 다음 과정은 beam search를 보여주고 있다.

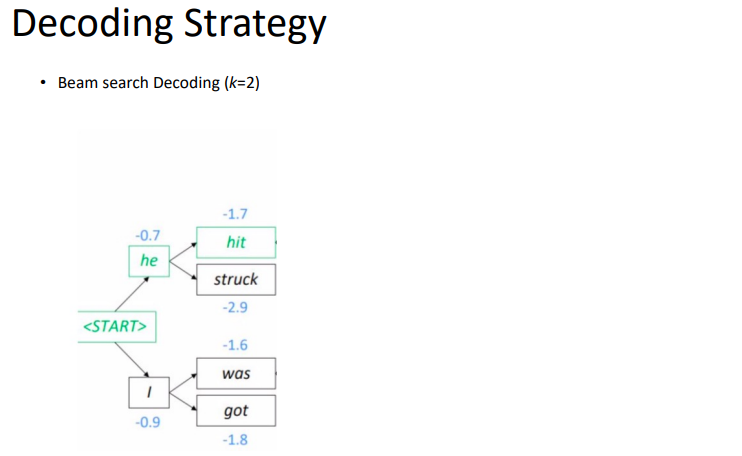
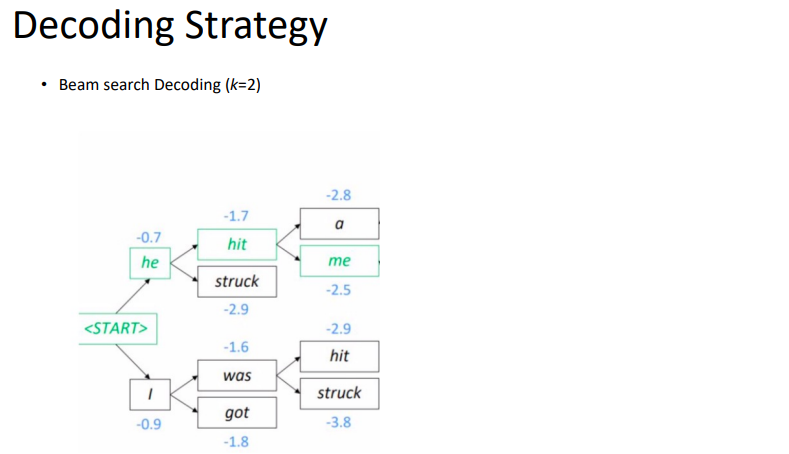





'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 52. Training Multi-Billion Parameter LM (0) | 2022.07.14 |
|---|---|
| Day 51. Machine Translation (0) | 2022.07.13 |
| Day35. NLP intro (0) | 2022.03.22 |