이번에는 조금 색다른 분야입니다.
언어 모델이 계속해서 커지면서, 이를 단순히 학습시키는 것조차 큰 문제가 되었습니다.
매우 큰 모델의 대명사인 GPT-3는 트랜스포머 디코더의 단 하나 레이어의 역전파를 계산하는 데에도 메모리 크기가 부족합니다.
이러한 거대 모델들이 어떻게 학습되었는지 알아보고, 우리가 사용해왔던 GPU가 가지는 특징 및 Multi-GPU의 활용 방법에 대해 알아봅시다.

최근 language model들은 데이터 크기와 모델 크기 모두를 늘리는 것이 추세였다.
이전에는 파라미터의 수가 그렇게 크지 않았지만, 모델의 크기가 크면 커질수록 성능이 좋아지는 것 때문에 GPT-3가 최종적으로 나오게 되었다. 175 billion
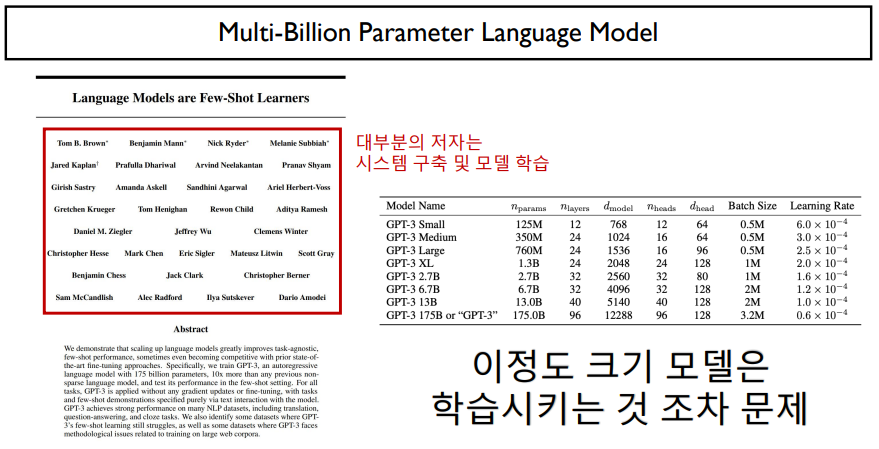
하지만, GPT-3 같이 너무 큰 모델은 학습시키는 것이 문제이다.
이 모델의 저자가 많아보이지만, 대부분의 저자는 시스템을 구축(GPU 서버 구축)하고, 모델 학습을 한 사람들이다.


CPU와 GPU의 차이는 무엇인가?
CPU는 컴퓨터의 header, GPU는 가속화장치라고 생각하면 편하다.

CPU와 GPU의 계산차이를 말할 때, CPU에는 대단한 코어들이 소수로 해내는 것이고, GPU는 일반 코어들이 굉장히 많아 다수로 일을 진행하는 것이라고 비유할 수 있다.
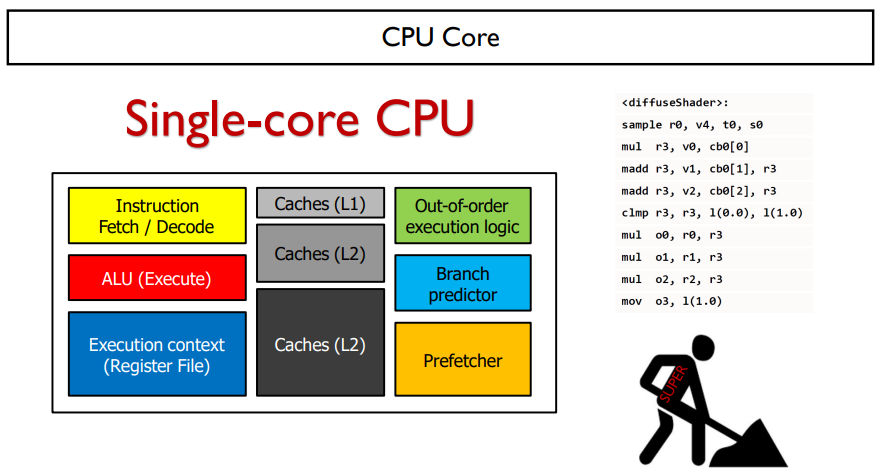
CPU의 구조는 위와 같다.
오른쪽 코드는 실제 컴퓨터에 들어가는 어셈블리 코드의 예시이다.
CPU의 핵심부분은 코드를 들고오고(노란색), 코드를 계산하고(빨간색), 코드의 결과를 저장(파란색)하는 부분이다.
나머지는 caches는 저장장치, 등 cpu의 연산을 가속화시켜주는 것이다.
이러한 것들이 하나의 single core CPU를 구성한다.

이러한 single core CPU가 여러 개 있다면, Multi-core CPU가 될 것이다.
core가 여러 개 있다는 것은, 실행시킬 수 있는 것이 두 개라는 것이다. 쉽게 비유하자면, 일하는 사람이 두 명이라는 뜻이다.
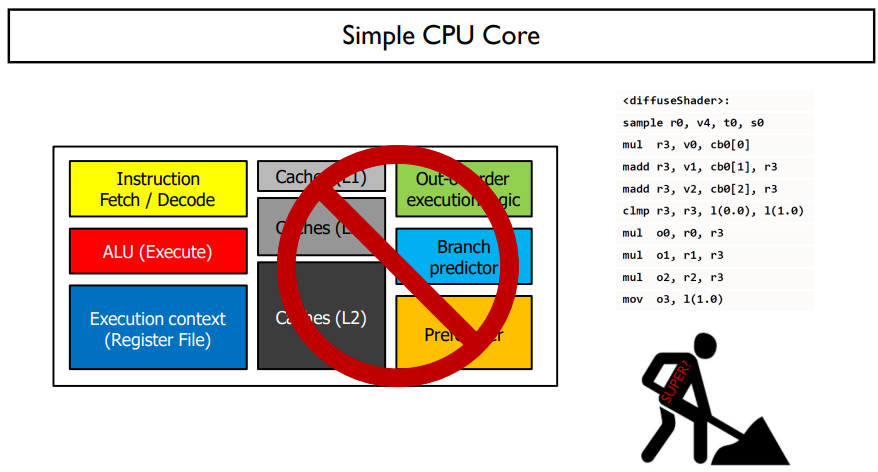

CPU의 핵심부분만을 가지고 이것을 여러개 붙여 강력한 CPU를 만드는 것이 때로는 더 효과적일 수도 있다.
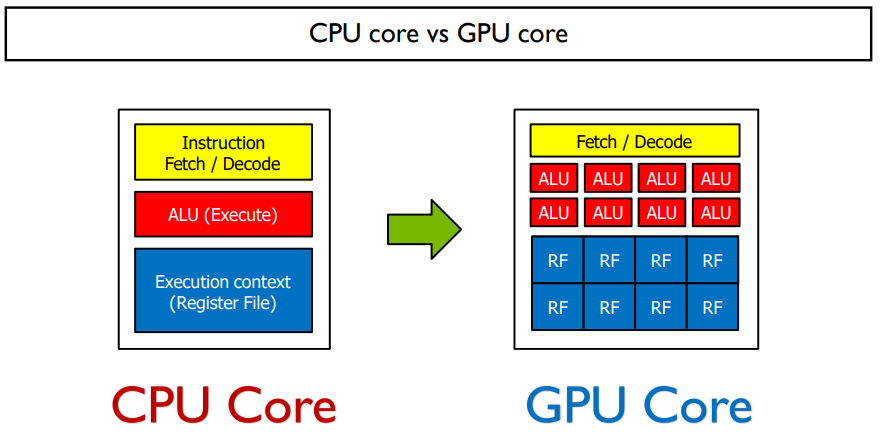
CPU core는 실제 계산되는 것은 따로 확인하지만, 코드를 하나만 보는 것이다.
GPU core는 모든 코어가 같은 코드를 읽고, 실제 계산은 다 다르게 하는 것이다.

SIMD를 가능하게 만들어 주는 것이 GPU이다.
예를 들면, 오른쪽 위의 코드가 있다고 하자. 이는 cuda core이며, SIMD processing은 모든 코어가 같은 instruction을 실행해야한다.
ALU 코드가 주어진다. 이 코드를 가져오는 건 하나이기 때문에, 모두가 같은 코드를 보아야 한다. 그 중에서 몇 개는 True code를 계산하고, 나머지 다른 것이 False code를 계산해서 하나의 코드를 계산할 것이다.
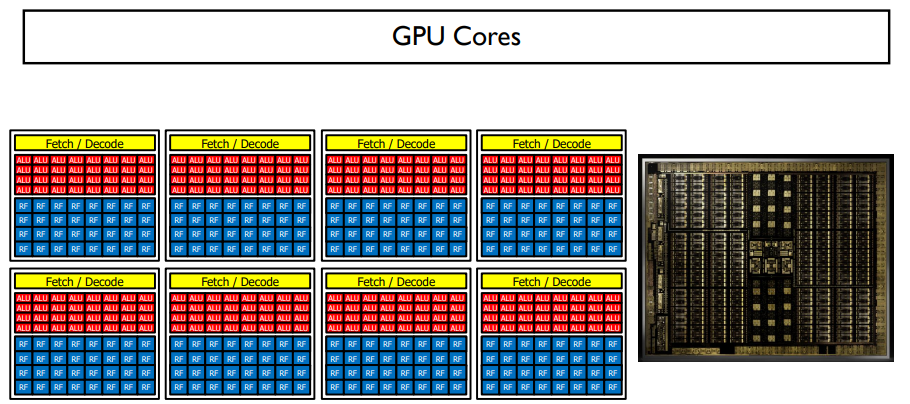
GPU에는 위 그림과 같이 코어가 구성된다. 한 코어에서는 같은 코드만을 바라보며, 이러한 코어가 여러 개로 구성되어 있다.

수 많은 코어들이 있는 GPU는 위 그림과 같은 모양을 띈다.
CPU는 순차적으로 연산해야하기 때문에 속도가 느릴 것이고, GPU는 속도가 빠를 것이다.

위 코드처럼 쓰면, cuda 연산이 가능할 것이다.
이는 머신러닝 라이브러리들에서 잘 지원해주고 있다. 이러한 API들을 사용한다면, GPU를 더욱 쉽게 이용할 수 있다.
CPU는 GPU에게 연산들을 보내주고, 커널을 만드는 역할을 하기 때문이다.
CPU와 GPU가 연산을 할 때, CPU에서 커널을 만들어 보내주면, GPU에서 연산을 한다. 하지만, 이 둘은 비동기식이기 때문에 print문으로 값을 출력하고 싶을 떄는 GPU의 연산이 모두 마쳐야 비로소 CPU에 값을 보내줄 것이다. 그렇기 때문에, for문을 돌릴 때 print문을 사용하는 것을 지양해야 한다. GPU값을 함부로 들고오면 동기화가 되기 때문에 속도가 너무 느려질 것이다.


Multi-GPU는 왜 필요할까?
multi-data에 대해서 한번에 연산하는 것은 GPU가 적합하다. 따라서, 코어 개수를 늘린다면, 연산이 훨씬 더 빨라질 것이다.
GPU가 많으면 많을수록 돌릴 수 있는 코어 수가 늘어나기 때문에 속도가 엄청나게 빨라져서 GPU를 여러 개 사용하는 것이다.

또한, 메모리 부족 이슈를 해결하기 위해서 GPU를 많이 꽂기도 한다.
주황색 박스가 GPU의 RAM이다. RAM은 CPU에도 있지만, 이는 GPU속의 RAM과는 별개이다.
GPU가 메모리 부족을 겪게 된다면, CUDA에러를 얻게 될 것이다. 이를 해결하기 위해서는 배치사이즈를 줄이던지, gradient를 적충시켜서 학습시켜야 할 것이다.

일반적으로 GPU는 한 보드에 8개정도 꽂힌다. 위 그림과 같다.
HPC가 multi gpu 연산에 최적화된 형태이다.
하지만, GPT-3같은 경우는 GPU가 8개나 존재하는 보드에서도 부족할 수 있다. 그 해결방법은 보드의 수를 늘리는 것이다.
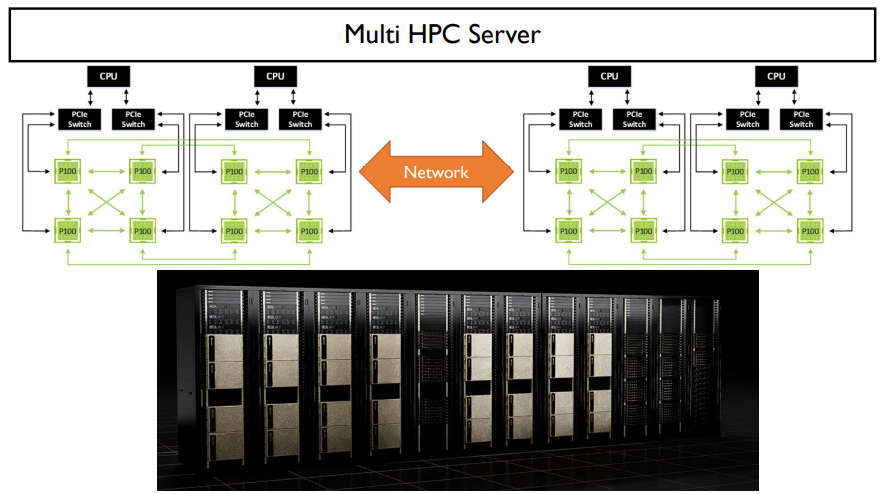
보드를 늘린 후, 내부 네트워크를 이용해서 통신해야한다.

super computer는 더욱 많은 GPU를 갖고 돌리는 컴퓨터이다. 선만 충분하다면, 네트워크로 이루어져있기 때문에 모두 다 이을 수 있다.

이러한 multi-gpu 코드는 위와 같다.
GPU 두 대라고 하면, 각자 device ID가 존재 할 것이다. 이것을 사용해서 특정 GPU의 연산을 지정할 수 있다.
위 코드를 보면, output으로 cuda 0과 cuda 1을 연결해 주었다. 그렇기 때문에, output.backward()를 하게되면, cuda 1뿐만 아니라 이어져있는 cuda 0까지도 되게 된다.
하지만, 이렇게 코드를 작성한다고해서 병렬화가 되지는 않는다. 단순히 실행속도가 빨라지지는 않는다.

그렇다면, 어떻게 해야 GPU 연산을 가속화시킬 수 있을까?
두 가지 방법이 있다.
첫 번째는 data parallelism, 두 번째는 model parallelism이다.
data parallelism은 거대한 batch를 다 쪼개서 데이터에 대한 병렬화를 통해 여러 개의 GPU가 각각 연산을 해서 최종 결과 값만 공유해서 업데이트 하는 것이다. 이렇게 되면, 병렬적으로 연산이 가능할 것이다.
model parallelism은 데이터는 그대로 있고, 한 모델에서 GPU들이 연산을 나누어 맡아 모델 자체를 병렬화 하는 것이다. 이는 모델을 나누는 것 자체가 문제이다. 한 GPU는 연산을 하고 있지만, 다른 GPU는 놀고 있는 불상사가 벌어질 수도 있다.
따라서, 일반적으로 data parallelism을 더 많이 사용한다. 이 방법을 pytorch에서도 강력하게 지원하고 있다.

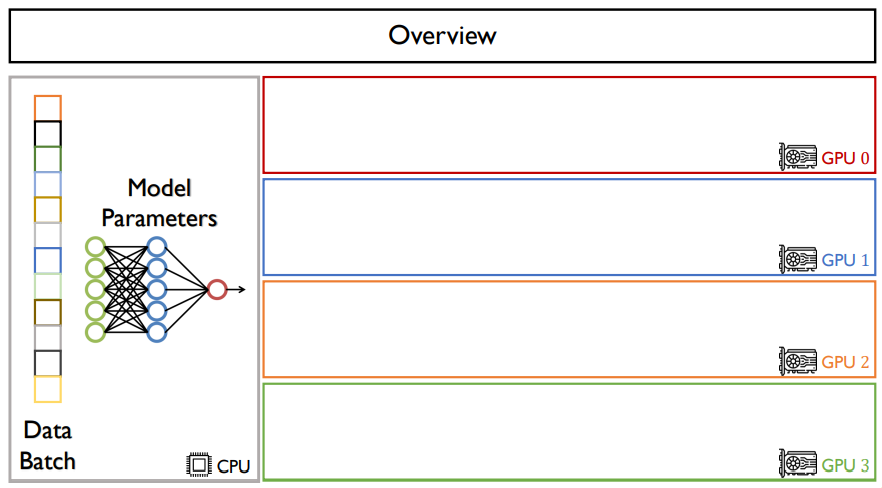
CPU가 한 대 있고, GPU가 4대 있다고 가정하자.
data batch와 model parameters는 CPU위에 있다.
data parallelism은 한 모델에 data를 나누는 것이다.
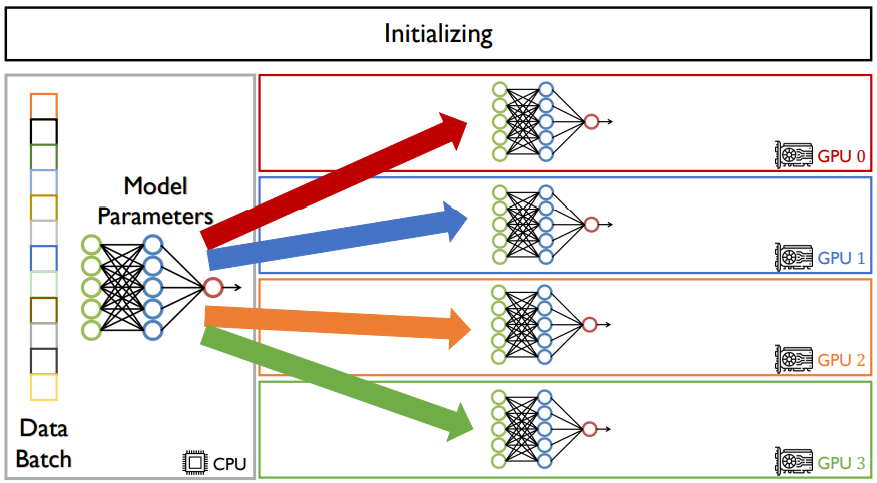
그렇기 때문에, 우선, CPU에 존재하는 모델을 모든 GPU들에 뿌린다. GPU들은 모두 같은 모델과 그 모델의 파라미터를 가질 것이다. 업데이트도 동일하게 될 것이다.

이제 forward path를 할 것이다.
data를 나누는 것이기 때문에, batch size가 만약 12라고 한다면, 각 GPU 당 3씩 나누어 가질 것이다. 그러면, batch가 3인 것들의 loss가 나올 것이다. 이렇게 나눈 batch를 sub batch 혹은 per-device batch라고 한다.

이렇게 나온 loss들을 가지고 backpropagation을 할 것이다.
backpropagation은 GPU안에서 계산이 될 것이다. 계산이 끝나면, 각각의 gradients 값이 나올 것이다.
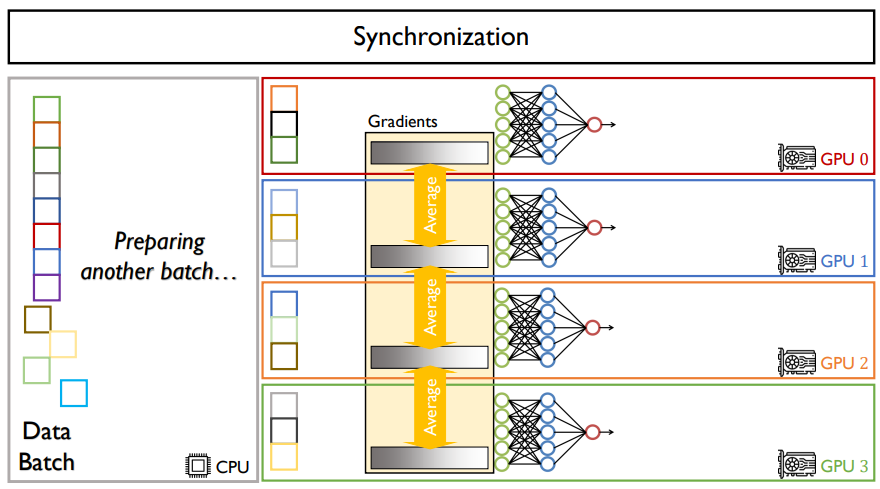
gradients들은 전부 다른 값을 가질 것이다. 그러나, GPU에서는 모델의 파라미터가 전부 같아야 한다.
그렇기 때문에, 결과로 나온 gradient들을 전부 평균을 낸 값을 모델에 업데이트 해준다. 이것은 원래의 batch size로 학습을 시킨것과 동일한 효과를 낸다.

이렇게 나누어 연산을 한다면, GPU가 4대가 있기 때문에, 속도도 4배 정도로 빨라지기는 한다.
다만, gradient를 평균내는 시간이 걸리기 때문에 속도가 4배보다는 조금 느리지만, 이 시간을 뺀다면 속도는 정확히 4배로 빨라질 것이다.
CPU가 하는 일은, GPU 4대를 관리하면서 다음 batch를 준비하는 역할을 한다.

코드도 간단하다.
torch.nn.DataParallel을 사용하면 위에서 한 과정을 간단하게 코드로 구현할 수 있다.
하지만, gpu-util이 100%가 아니기 때문에 GPU가 4대더라도 속도가 완벽히 4배가 되지는 않는다. 이는 CPU의 코어에서 감당하기에는 벅차기 때문이다. 결국 속도는 2배 정도 밖에 빨라지지 않을 것이다.
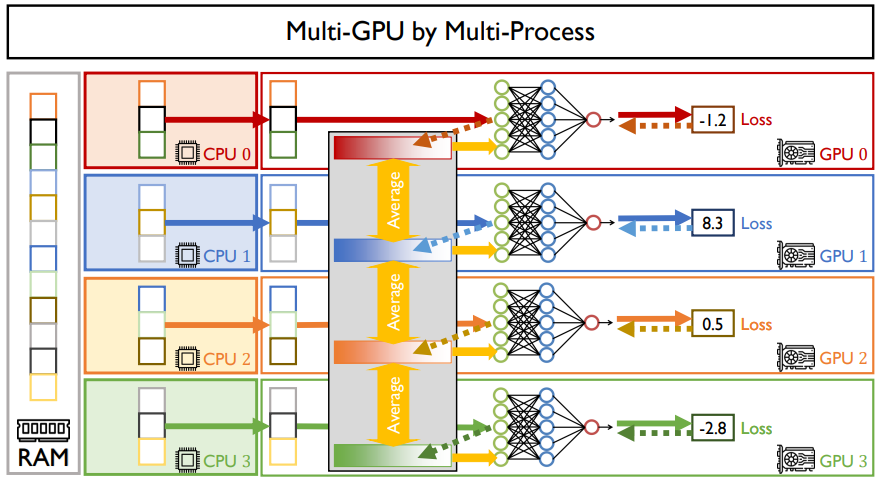
위와 같은 문제를 해결하기 위해서는 CPU의 갯수를 늘리는 것이다.
GPU 하나 당 processor를 하나씩 맡게 하면 된다.


def 부분은 학습 코드이고, if 코드는 initialize하는 코드이다.
python의 multi-processing(mp) 라이브러리를 사용해서 코드를 작성할 수 있다.
gradient accumulation은 gpu 한 대 밖에 없어도 큰 batch size를 사용할 수 있는 것이다. 병렬화와는 상관없지만, 아주 유용하니 찾아서 공부해보자!


data parallelism은 한계점이 존재한다. 이는, batch size가 1인경우에 data parallelism을 할 수 없다는 것이다.
모델이 아주 크다면, batch size가 1이더라도 GPU 연산이 벅찰 수 있다.
이럴 때에는, 모델을 잘라서 써야한다.
GPU에 모델의 layer를 다르게 나누어주어 연산을 진행시키는 것이다. 이론적으로는 가능하지만, 실제로는 버블이 생기게된다.

batch 하나를 계산한다면, forward -> backward -> optimize를 통해 batch를 계산한다.
이 때, forward와 backward를 계산할 때, backward를 전부 계산하기 위해서는 forward가 전부 계산된 후 다시 돌아와야 계산이 가능할 것이다. 이는, GPU 하나가 일하고 있을 때, 다른 GPU들은 놀고있기 때문에 이것은 GPU 하나만을 쓴 것과 같은 효과이다.
우리는 이렇게 연산되는 것을 원하지 않을 것이다. GPU들이 전부 동작하기를 원할 것이다.

이를 해결하기 위해서 batch를 쪼개서 pipline을 만들어주면된다.
위의 그림처럼 할 수 있다. 이를 pipelining이라고 한다. 이것도 bubble이 생기기는 하지만, 적당히 있는 정도이다.
sub batch 개수 자체를 더 늘린다면, bubble이 조금 더 줄어들긴 할 것이다.

다른 방법은 위와 같은 방법도 있다.
하지만, 끝나는 시간 자체는 똑같다.
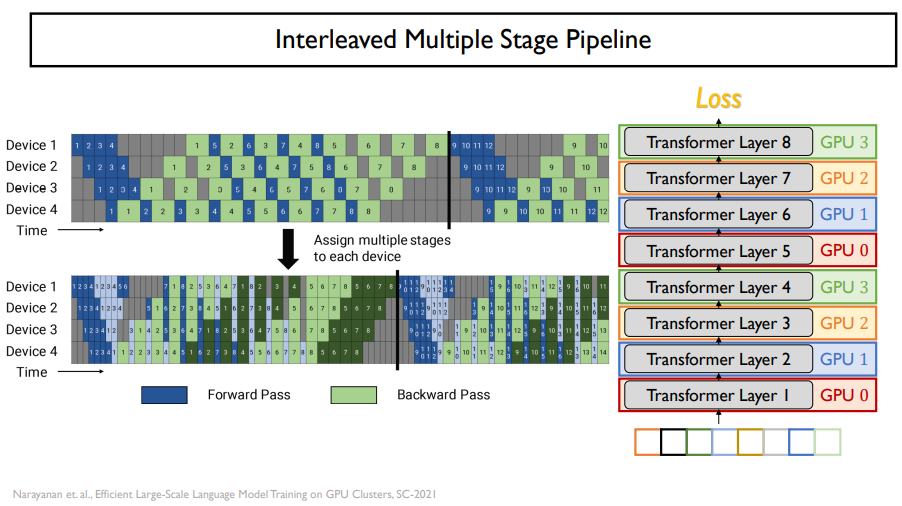
오른쪽 그림과 같이 GPU가 layer를 맡게 된다면, 이는 batch를 자르는 것과 같은 효과가 난다.
이와 같은 방법은 시간을 조금 더 단축시킬 수 있다.

pytorch에서는 pipe라는 라이브러리를 제공한다.
이를 통해 위와 같은 연산을 조금 쉽게 코드로 짤 수 있다.


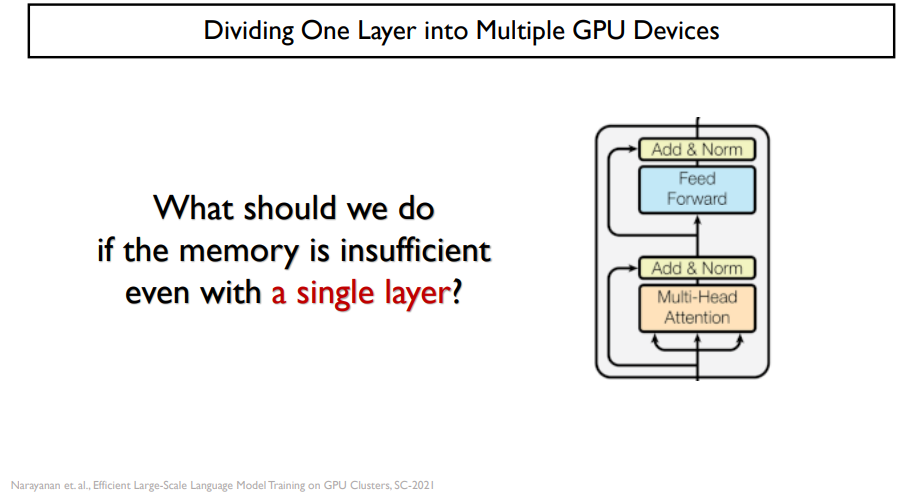
parallelism은 tensor parallelism이 있다.
만약, layer가 1개인데도 불구하고 메모리가 부족하다면 어떻게 해야할까?
이럴 때 tensor parallelism을 사용해야 할 것이다. 이는 model parallelism처럼 가로로 쪼개는 것이 아닌, 세로로 쪼개는 것이다.
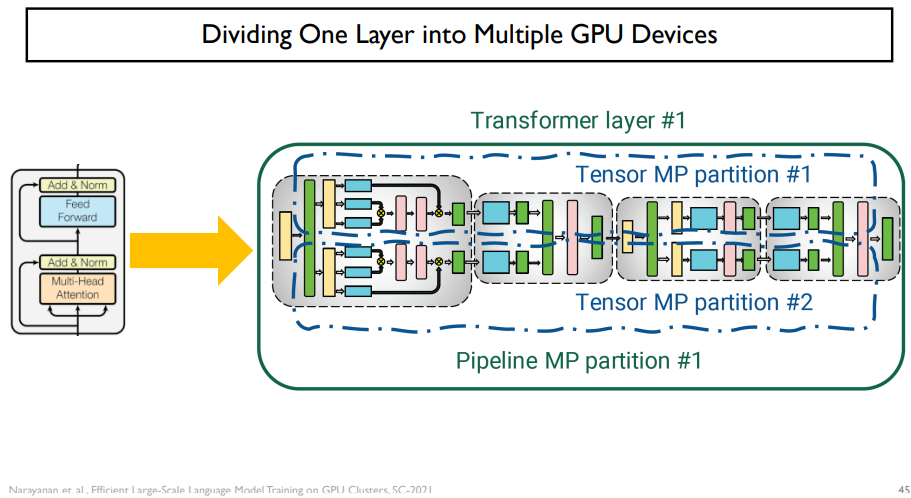
transformer encoder가 있을 때, 반은 GPU 0번이 맡고, 반은 GPU 1번이 맡는 것이다.
이것은 수학적으로 뜯어본다면, 가능한 연산이다.

linear layer는 위와 같이 쪼개는 것이 가능하다.
input이 들어오면, identity에 반으로 쪼개어 넣어준다.
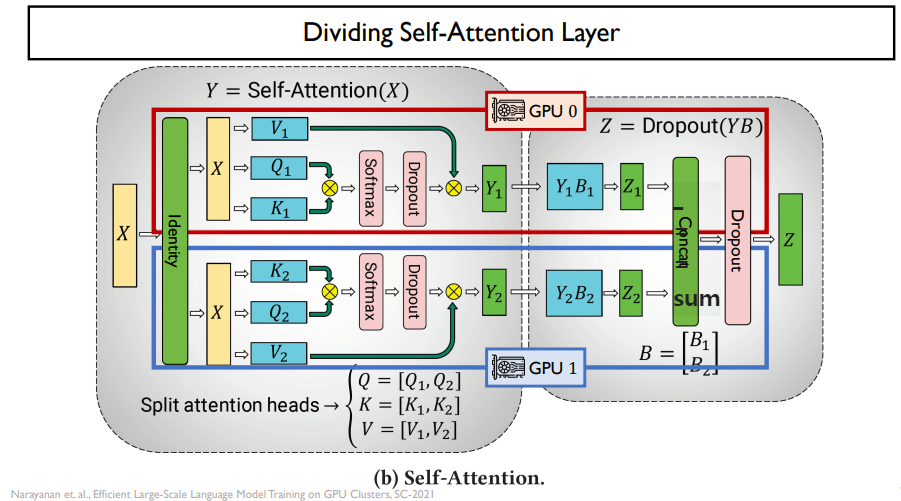
self-attention도 반으로 나눌 수 있다.

tensor parralelism이 bubble이 없기 때문에 더 좋을 수는 있지만, communication 비용이 비싸다는 단점이 있다.
반대로, pipeline parallelism은 선형결합이기 때문에 비용이 적게 든다.


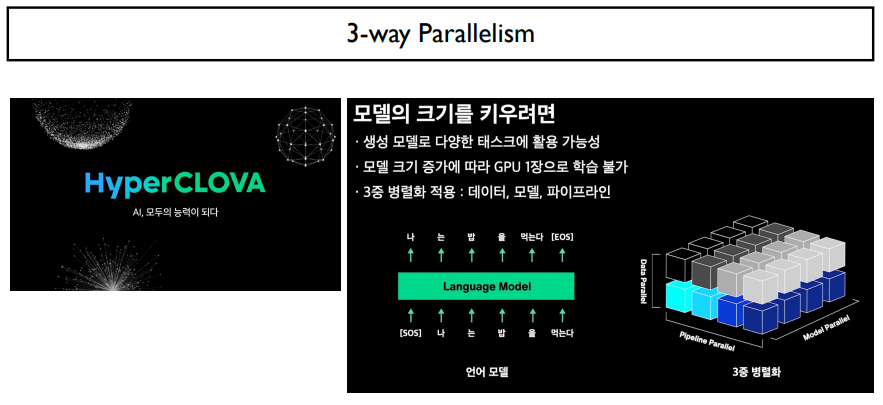
대형모델을 쓴다면, 위의 세 가지 parallelism을 다 사용해야 할 것이다.

3중 parallelism은 위 그림과 같다. 이들은 전부 특성이 다르기 때문에, 적절하게 사용하여야 할 것이다.


'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 51. Machine Translation (0) | 2022.07.13 |
|---|---|
| Day 50. Text Generation (0) | 2022.07.12 |
| Day35. NLP intro (0) | 2022.03.22 |