자연어처리 분야에서 가장 큰 시장 규모와 연구 커뮤니티를 가진 기계번역에 대해서 알아봅시다.
기계번역은 언어학자들이 주도한 statistical machine translation(SMT)부터 최근의 neural machine translation(NMT)까지 눈부신 발전을 거듭했습니다.
병렬언어 말뭉치를 기반으로 하는 supervised NMT부터 단일언어 말뭉치를 기반으로 하는 unsupervised NMT를 알아봅니다.
그리고, 여전히 존재하고 있는 번역 task의 어려움에 대해서 알아봅시다.
기계번역이 성능을 어떻게 높였으며, 어떻게 진행되었는지를 알아보자.

Machine translation은 인공지능이 다루는 task 중 손에 꼽을 정도로 어려운 편에 속한다.
하지만, 어려움에 비해서 활용도가 매우 높기 때문에 중요한 task이다.
한국이나 외국에서 자연어처리 연구를 한다면, 기계번역 연구를 할 가능성이 높다.
machine translation은 주로 파파고, 구글 번역 등에 쓰이고 있다.
위키피디아의 정의에 따르면, 번역을 할 때, 번역의 시작점이 되는 언어를 source language, 번역하고자하는 언어를 target language라고 한다. 번역은 단순히 의미를 파악하는 것이 아니라, source language의 단어, 문법, 문맥을 전부 target language로 변환하는 것을 말한다.
컴퓨터가 등장하고부터 이를 통해 빠른 번역을 하기 위해 지금까지 많은 사람들이 노력하고 있다.
'해석은 번역이 아니다. 번역을 하는 일이 10이라고 할 때, 그 중 의미를 파악하는 부분은 2이고, 나머지는 문장을 어떻게 구성하고 작성할지를 결정하는 것이다.' 라고 말을 하기도 한다.
이러한 점을 살펴보았을 때, 번역은 아주 어려운 task임을 알 수 있다.
구글 번역기와 파파고에 동일한 문장을 번역시키더라도 다른 결과가 나올 수 있다. 이는 하나의 문장을 넣더라도 하나의 output만이 정답이 아니라, 여러 문장들이 정답이 될 수도 있음을 보여준다.

source language를 x라하고, target language를 y라고 할 때, x에서 y로 변환시키는 것을 번역이라고 한다.
한국어에서 영어로 번역한다고 할 때, 한국어가 source language, 영어가 target language가 된다.
NMT는 기본적으로 한 개의 문장을 번역하는 것을 기본 세팅으로 갖고 있다.
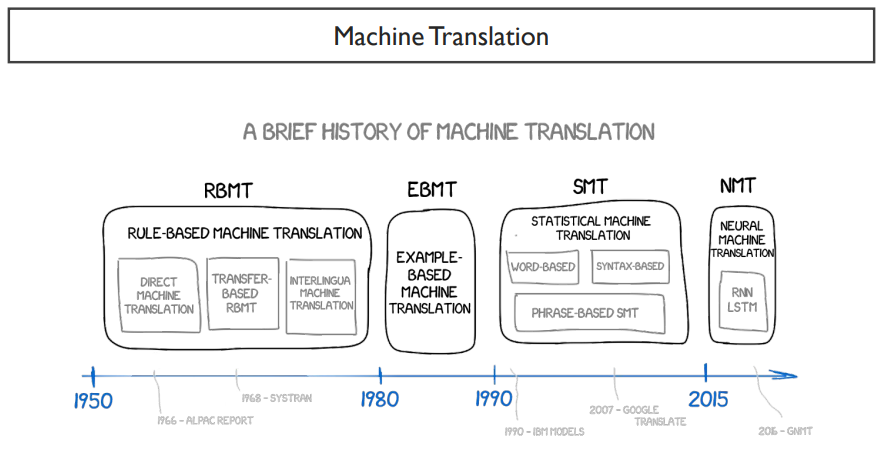
기계 번역이 인공지능의 시작이 된 것은 아니다.
하지만, 예전부터 전 세계 사람들이 서로의 언어를 별다른 공부 없이 자국의 언어로 알아들을 수 있었으면 하는 바램이 컸다.
1950년대에는 컴퓨터 튜닝을 시작하면서부터 기계번역이 시작되었다. 가장 간단하게 접근할 수 있던 방법은, 규칙이나 예제를 base로 하는 모델이었다.
그 다음으로는 컴퓨터의 계속된 발전으로 인해, 통계적인 접근방법이 있었다.
1990년대 이후에는 deep learning model을 기준으로 NMT(Neural Machine Translation)가 발달하기 시작하였다.
NMT 이전에는 SMT가 있었다.

SMT는 input을 tree dependecy로 만들고, 확률 기반으로 가장 높은 확률의 target 문장을 고르는 것이다.
위 그림은 google의 SMT이다. 영어를 주었을 때, 독일어로 이를 번역하는 것이다. 'leave'를 주었을 때, 결과 값으로 가장 확률이 높은 단어를 선택하는 것을 볼 수 있다.
이렇게 SMT는 확률기반의 방법이다.
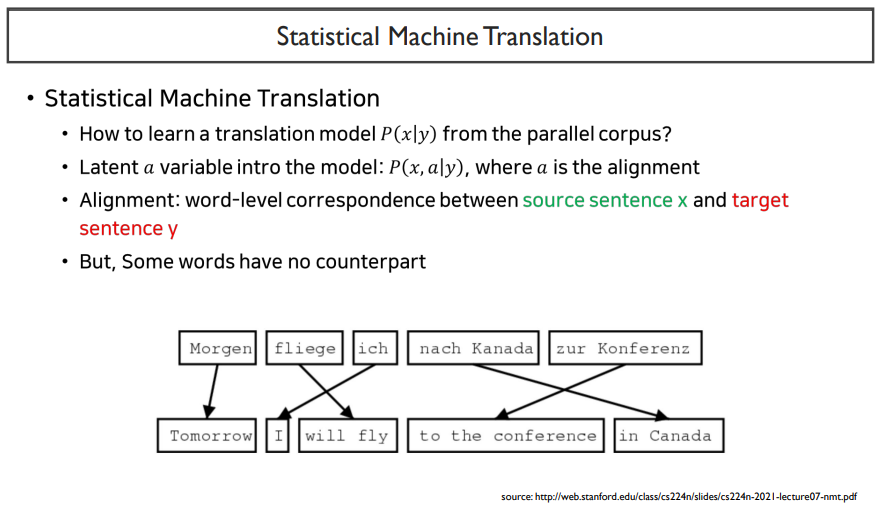
SMT에도 source language와 target language가 필요하다.
기본적으로 supervised learning으로만 학습이 진행되었다.
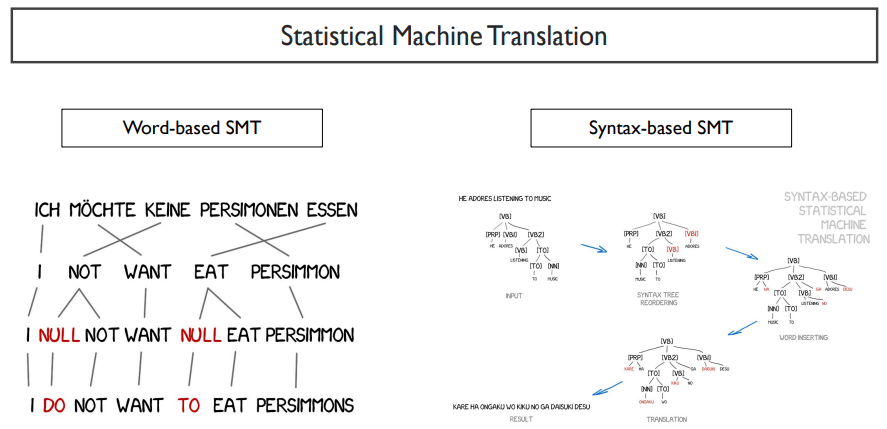
SMT의 예시로는 크게 두 가지로 나눌 수 있다.
Word-based SMT는 각 단어에 대해 대응되는 단어를 하나씩 재배치해주고, 해당 target언어의 어법에 맞게 순서를 바꾸어주고, 부족한 부분을 추가해주는 것이다.
Syntax-based SMT는 이보다 더 복잡한 과정을 거친다.
하지만, 많은 단어들을 매 time step마다 거쳐지고, 수많은 과정들을 코드로 작성해야 자동화가 될 것이다. 그렇게 된다면 어떤 문제가 생길까?

문제는 위와 같다. 또한, 고려해야할 것들도 많다.
예외 조건들을 전부 코딩해주어야할 것이다. 또한, 계속해서 업데이트를 해주어야 할 것이다.

통계 기반의 기계번역분야 이후로, 패턴을 파악하는 NMT가 등장하게 되었다.

2014년 Neurips 학회에서 Sequence to sequence 논문이 발표되었다.
이 모델의 아키텍처는 many-to-many 구조와 같다는 것을 알 수 있다.
S는 encoder의 LSTM 블럭을 하나씩 통과한 다음, 문장의 정보를 모두 함축하고 있다. decoder에서는 LSTM 모델을 통해 번역을 하나씩해서 풀어나가며 문장을 생성하게 된다.

BLEU score는 precision기반의 메소드이다.
precision은 예측한 것 중에서 맞춘 것이고, recall은 정답 중에서 맞춘 것을 말한다.
BLEU score는 내가 내뱉은 단어의 sequence중에서 얼마나 정답을 맞추었는지를 계산하는 것이다.

BLEU score에 대한 정의는 위 식과 같다.
이 식에서의 precision은 무엇일까? 밑에서 살펴보자.
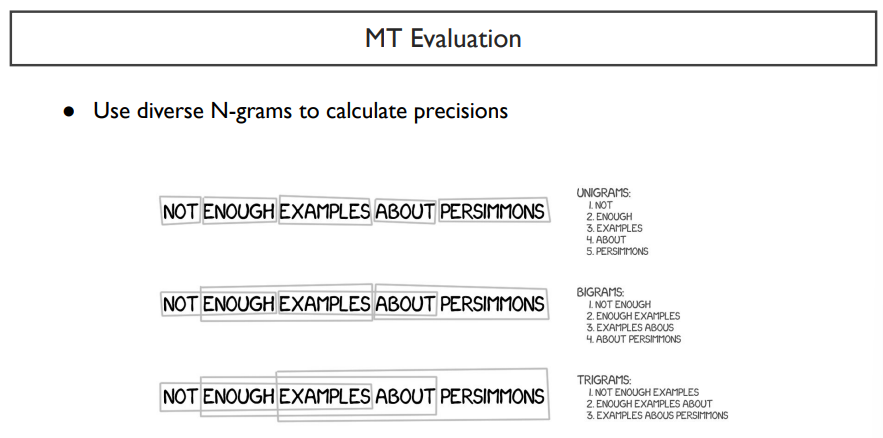
precision을 알기위해서는, N-gram을 다시 살펴봐야한다.
N-gram에서 1-gram을 unigram이라하고, 2-gram을 bigram, 3-gram을 trigram이라고 한다.
gram은 다루는 unit의 단위이다. 예를 들어, 두 단어씩 보면 bigram이다.
precision1은 unigram, precision2는 bigram, precision3는 trigram... 으로 보면 된다.
precision unit의 기준은 word, token 둘 다 될 수 있지만, 보통은 token을 주로 쓴다. 여기서는 보기 쉽게 word라고 가정하자.
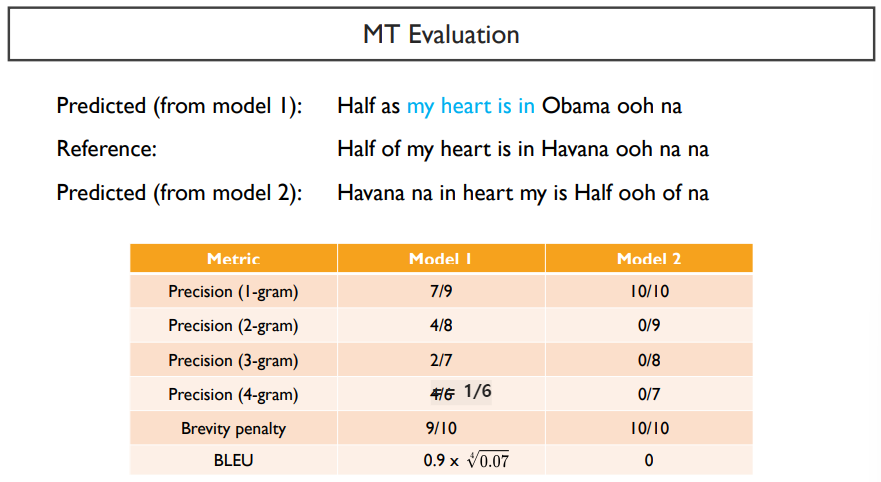
precision을 계산할 때에는 순서를 생각하지 않는다. 순서는 n-gram에서만 생각한다. 또한, brevity penalty를 주어 최종 BLEU score를 얻게 된다.
BLEU score는 길이가 긴 문장에 대해서는 점수가 낮아질 수 밖에 없는 한계점이 있다. BLEU score는 2002년에 기계 번역의 성능을 SMT 모델에서 알아보기 위한 것이기 때문에 지금으로써는 한계점이 많을 수밖에 없다.
대표적인 예로는, 위의 표에서 Model 2처럼, 하나의 precision에서 0인 점수를 받게된다면, 전체 BLEU score가 0이 되는 문제점이 발생한다.

이러한 BLEU score를 해결하기 위해서 많은 방법들이 나오게 되었다.
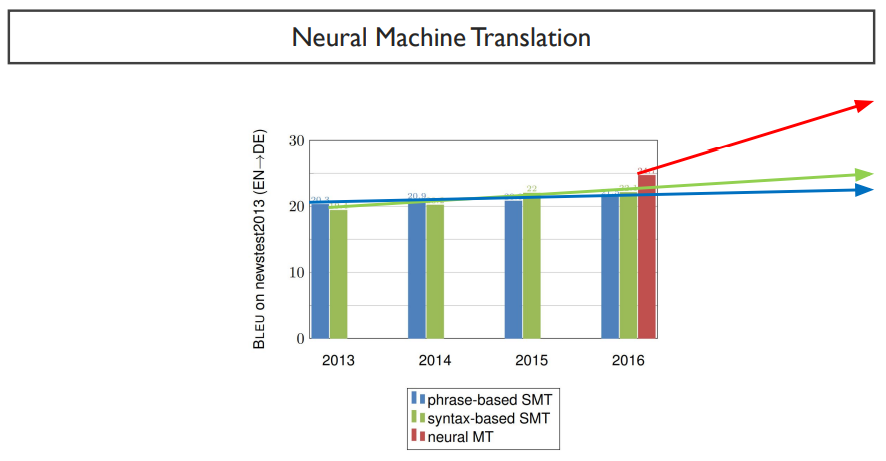
SMT의 성능은 별로 오르지 않는데, NMT의 성능은 계속해서 오르는 것을 볼 수 있다.
하지만, 평가지표인 BLEU score는 과연 이것을 만점으로 만들 수 있을 것인가에 대한 의문점이 발생하게 된다. 아무리 성능이 높은 기계 번역 모델이라고 하더라도, max score는 40정도이다. 심지어는 사람도 100점이 나오지 않는다. 대략 사람은 60정도 나온다. 만약, BLEU score가 70점 이상이 나온다면, 코딩을 잘못한 것이라고 말하곤 한다.
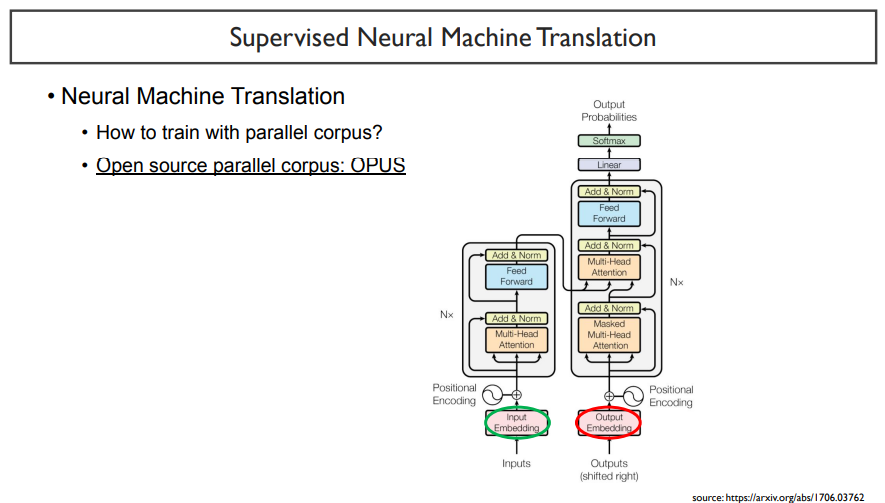
한국어에서 영어로 번역을 한다고 할 때, 한국어 문장에 대응되는 영어 문장을 모두 갖고 있다면, supervised learning을 할 수 있을 것이다.
이런식으로 언어에 대해 갖고 있는 데이터셋들을 통틀어 corpus라고 한다. 이 중에서 한국어-영어와 같이 병렬되는 데이터셋은 parallel이라는 말을 붙이기도한다. 이렇게 가장 유명한 데이터셋은 OPUS라는 데이터셋이다.
OPUS에는 다양한 데이터셋들이 존재한다. 대표적으로 유명한 데이터셋은 위키피디아, WMT-news 가 있다.
input 문장으로 '나는 학교에 간다' 가 들어가면, output 문장으로는 'I go to school'이 나와야 한다. 이렇게 train하는 과정은 위의 그림과 같고, 자세한 설명은 이전의 포스팅을 참고해보자

supervised learning을 하면 좋을 것이다. 하지만, 모든 것에 적용이 가능할까?
parallel corpus(bilingual corpus)는 만들기도, 얻기도 굉장히 어려울 것이다. 하지만, 각각의 언어에 대해서의 데이터셋인 monolingual corpus는 상대적으로 많을 것이다. 이러한 monolingual corpus를 이용하기 위해서 unsupervised를 적용하기 시작하였다.

UNMT(unsupervised neural machine translation)은 2018 논문으로 등장하였다.
이 논문이 말하는 방법으로는, 첫 번째로, 각 언어를 학습시키고, 두 번째로, 역 번역을 해본다는 것이다.

맨 처음으로 각 언어에 대한 학습은 어떻게 진행될까?
Denoising이라는 방법을 사용한다.
Dennosiing이란, L1과 L2라는 언어를 사용한다고 할 때, input문장으로 이상한 문장이 들어왔다고 하자. decoder가 생성하는 것은 input문장을 원래 상태로 복원시키는 것이다. encoder는 두 언어가 share한다. 이는 문장이 가지고 있는 의미는 동일한 과정을 거친다는 가정 때문이다.
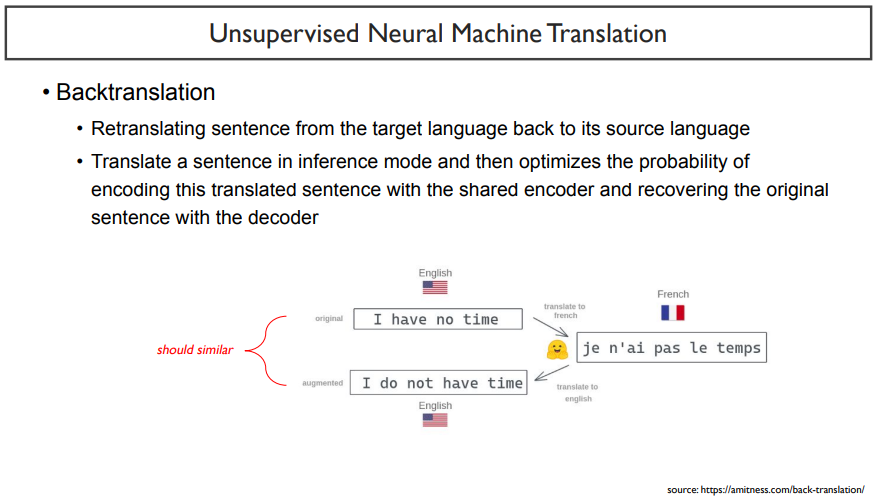
Backtranslation은 한 언어를 넣고, encoder에 넣은 다음, 다른 언어의 decoder에 넣어주는 것이다. 그 output을 다시 encoder에 넣은 후, 원래 언어의 decoder에 넣어주어 원래 언어로 만들어준다. 쉽게 말하면 위 그림과 같다.
그렇다면, 이 과정을 거치기 전의 문장과 다 거친 후의 문장은 유사한 형태가 되어야 할 것이다.
두 가지의 내용을 간단히 표현하면 다음과 같다.
denosing : L1 -> encoder -> L1 decoder
backtranslation : L1 -> encoder -> L2 decoder -> encoder -> L1 decoder
이러한 방식으로 학습이 진행된다. 처음에는 supervised learning보다는 성능이 안좋았지만, 최근에는 활발하게 연구되고 있는 분야이다.
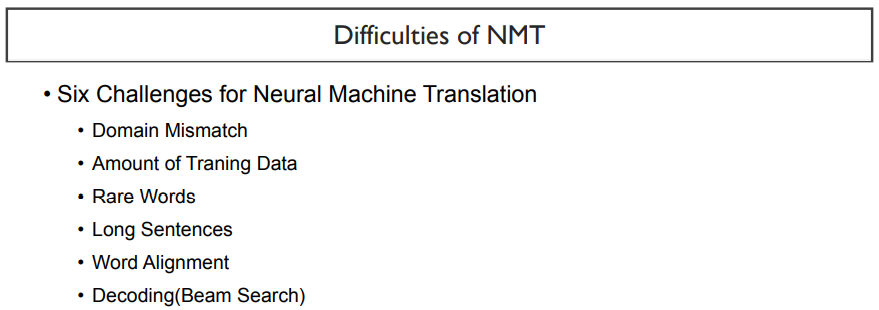
NMT에서 풀기 어려운 것을 여섯 가지로 말할 수 있다. 이들은 아주 중요하고 아직 해결되지 못한 문제이다.
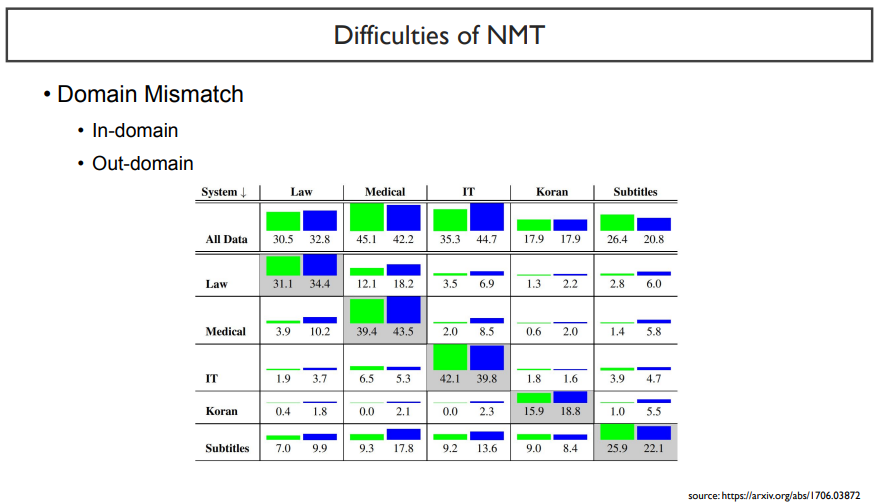
첫 번째로, 모델이 보지 못한 도메인에 대해서는 성능이 떨어진다.
NMT에서의 domain mismatch에서 불리는 domain은 다음과 같이 불린다. my model이 학습한 데이터는 in-domain, 보지 못한 데이터셋들은 out-domain이라고 한다.
위 표를 보면, out-domain값에는 성능이 많이 떨어지는 것을 볼 수 있다.
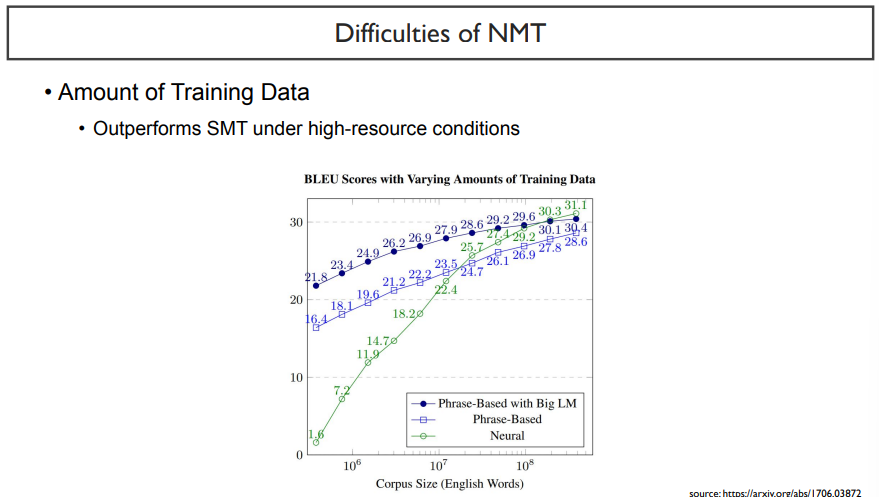
두 번째로는, 데이터셋의 사이즈이다.
위 그래프에서 남색, 파란색이 SMT이고, 초록색 그래프가 NMT이다. x축은 corpus size, y축은 BLEU score이다.
이 때, 결국 NMT의 성능이 높아지는 것은 corpus size가 클 때이다. dataset이 작을 때는 오히려 더 낮은 성능을 보이고 있다.
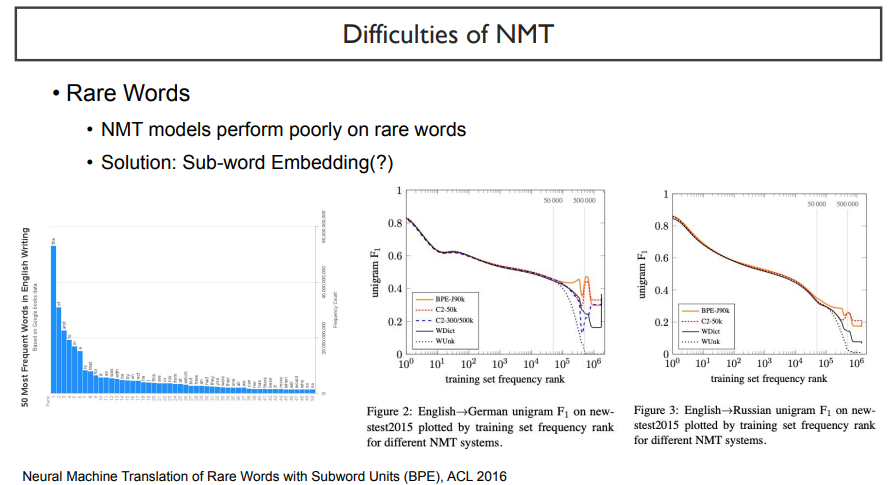
세 번째로, 자주 쓰지 않는 단어가 들어가면 성능이 낮아진다.
왼쪽 그래프는 단어별로 빈도수를 측정했을 때 나타낸 것이다. 자세히 살펴보면, 빈도수가 높은 단어들은 'the', 'in', 'a' 이러한 단어들이다. 정작 유의미한 단어들은 빈도수가 매우 낮게 나타날 것이다. 이렇게 단어의 빈도수가 많이 차이난다. 내가 유의미해서 rare word가 아니라고 생각하여도, 빈도수를 측정하면 rare word가 될 수도 있다.
오른쪽 두 개의 그래프를 보자. 이들은 학습 데이터셋에서 어느 영역까지 포함할 것인지를 나타내는 그래프이다. vocab의 수가 50000이 넘어가는 단어들을 포함하는 순간 성능이 확 떨어지는 것을 볼 수 있다. 따라서, NLP task를 할 때, rare word까지 포함하려면, word단위가 아니라 subword 단위로 보는 것도 좋겠다는 결과를 볼 수 있다.
어느 정도까지 vocab으로 취급할 것이지를 정하는 것도 중요한 하이퍼파라미터라고 생각할 수 있을 것이다.
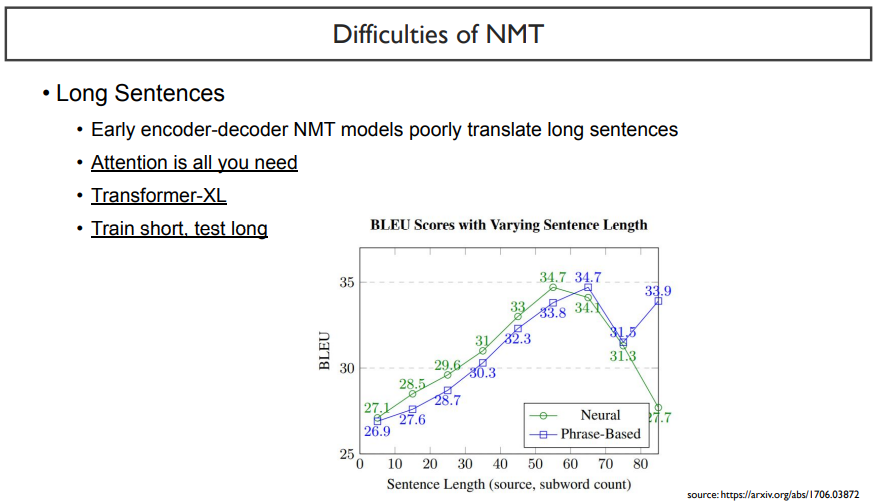
네 번째로, 문장의 길이가 매우 길어질 때, 성능이 많이 떨어진다.
NMT는 문장 길이가 55정도 지나고 나면 성능이 많이 떨어지고, SMT는 65정도 지나면 성능이 떨어진다. NMT가 SMT에 비해 많이 예민한 것을 볼 수 있다.
긴 문장에서 어려움을 겪는다는 것은, short term memory와 유사한 문제를 갖고 있다. 이를 해결하기위해 많은 방법이 시도되었다.
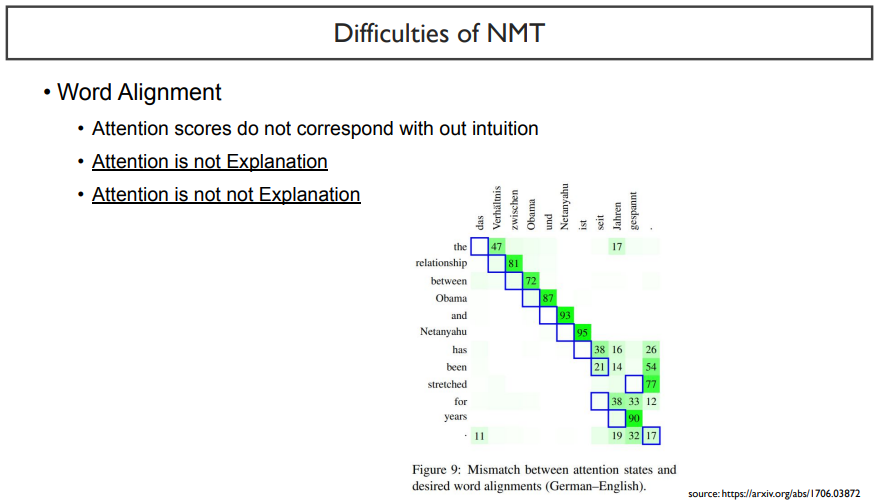
다섯 번째로는, 딥러닝 모델이 우리가 생각한대로 alignment를 맞춰서 잘 학습하지 않는다는 것이다.
예를 들어, 위 그림을 보면, relationship에 대응되는 단어는 x축에서의 두 번째 단어이다. 그러나, attention weight는 다음 단어에 더 높다. 영어와 독일어 사이에서 diagonal한 쌍을 이루는 정답값이 있지만, 모델이 집중하는 것은 그 다음단어라고 실험으로 나타내었다.
이렇게 attention이 병렬되는 단어를 잘 맞추는지에 대한 논문이 attention is not explanation이다. 그러나 구글이 이에 반박하기위해 내놓은 논문이 attention is not not explanation이 있다고 한다.
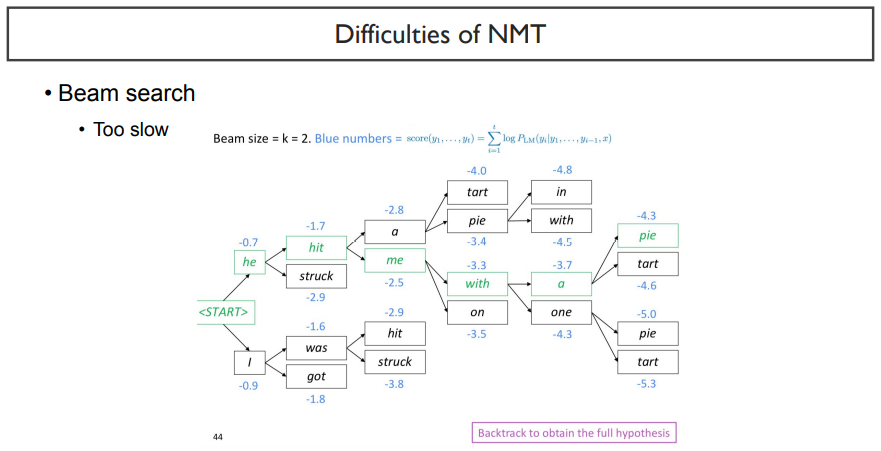
여섯 번째는, decoder에서 문장을 생성할 때, 매우 느리다는 점이다.
확률이 가장 높은 한가지 뿐만 아니라, 그 차선책까지 생각하기 때문에 sequence length가 길어짐에 따라 그 수가 많아져서 굉장히 느려지기 때문이다.
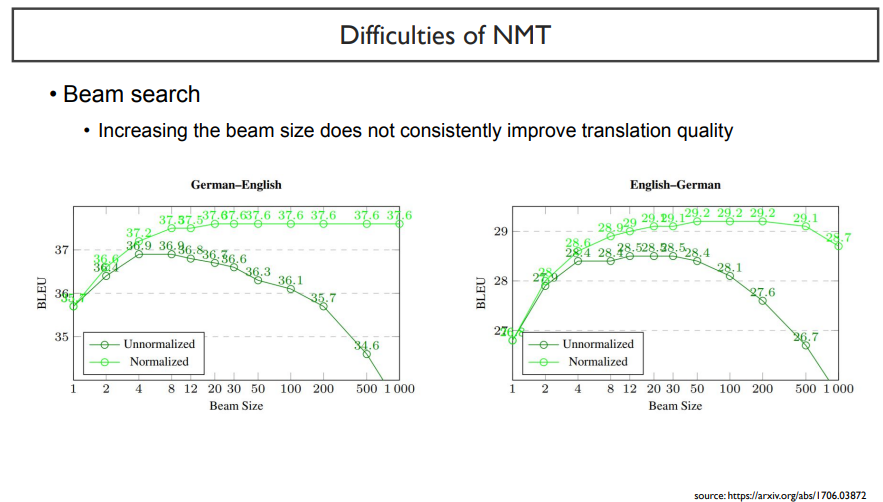
beam search를 할 때 normalized를 하지 않았을 경우에는 성능이 많이 떨어지는 것을 볼 수 있다.
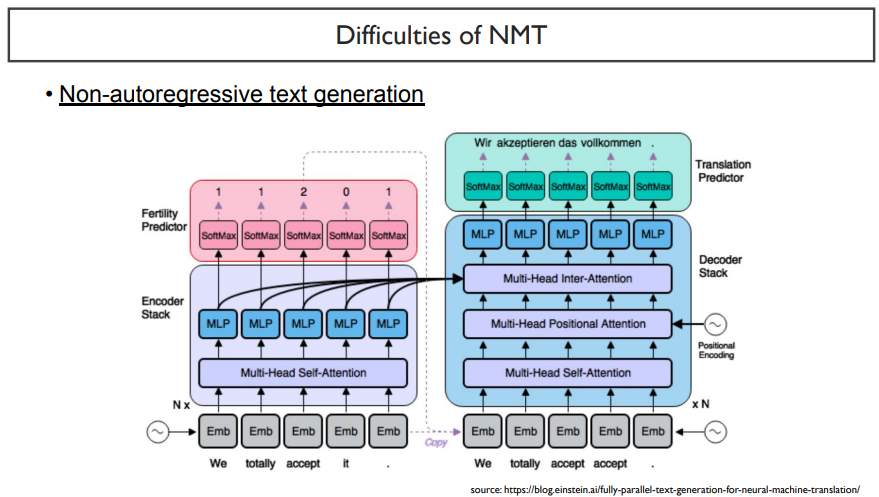
이를 해결하기 위해서, beam search가 아닌 한 번에 text를 생성하자는 것이 등장하였다.
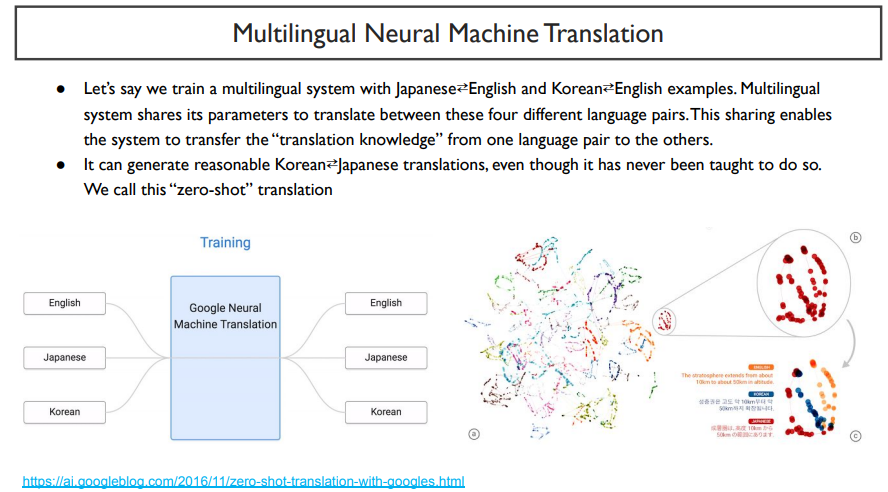
지금까지 본 것은 bilingual 이었다. 그러나, 모든 언어를 한 모델로 처리가 가능하다면 더 좋을 것이다.
그래서 나온 것이 multilingual NMT이다. 이는 수십가지 언어를 한 모델로 처리한다.
만약, (영어, 일본어), (영어, 한국어) parallel이 있을 때, test에서 (일본어, 한국어)를 한다고 하면, 이미 갖고 있는 지식을 활용해서 한 번도 보지 못한 것을 수행하겠다는 의미이다. 이는 embedding space에서 유래되었는데, 비슷한 의미를 갖는 단어들은 언어가 다르더라도 비슷한 위치에 존재하기 때문이다.
하지만, 이 방법은 항상 많은 좋은 성능을 내는 것은 아니다. 하지만, 이와 비슷한 예가 존재했다는 것은 흥미로운 일이다.
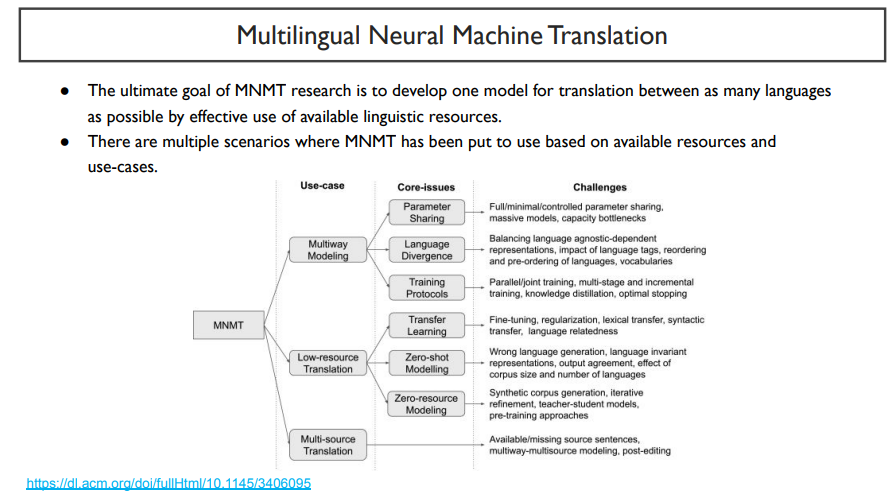
데이터셋을 보았을 때, (한국어 - 영어) , (일본어 - 영어) 데이터셋은 많지만, (한국어 - 일본어) 데이터셋은 그 수가 너무 적어 성능이 많이 떨어진다고 하자. 이럴 때, (한국어 - 영어 - 일본어) 와 같은 해결방법을 사용하는 것이다.
이것은 MNMT라고 부른다. 하지만, 가장 큰 부작용인 성능 저하를 갖고 있다.

기계 번역은 sorce에서 다른 target으로 번역하는 task이다.
MT는 규칙, 통계, neural base로 종류가 다양하지만, 최근에는 encoder-decoder bert가 가장 크게 떠오르고 있다.
metrics는 여러 가지가 있다.


'NLP > AI기술 자연어처리 전문가 양성 과정 3기_NLP' 카테고리의 다른 글
| Day 52. Training Multi-Billion Parameter LM (0) | 2022.07.14 |
|---|---|
| Day 50. Text Generation (0) | 2022.07.12 |
| Day35. NLP intro (0) | 2022.03.22 |